

Introducere în Harta Alăturați-vă în stup
Map join este o caracteristică utilizată în interogările Hive pentru a-și crește eficiența în ceea ce privește viteza. Join este o condiție folosită pentru a combina datele din 2 tabele. Așadar, atunci când efectuăm o aderare normală, lucrarea este trimisă unei sarcini Map-Reduce care împarte sarcina principală în 2 etape - „Etapa hartă” și „Reduce etapa”. Etapa Hartă interpretează datele de intrare și returnează ieșirea la etapa de reducere sub formă de perechi cheie-valoare. Acest lucru trece prin etapa de schimbare în care sunt sortate și combinate. Reductorul ia această valoare sortată și finalizează lucrarea de alăturare.
Un tabel poate fi încărcat complet în memorie într-un mapper și fără a fi necesar să folosiți procesul Map / Reducer. Citește datele din tabelul mai mic și le stochează într-un tabel de hash în memorie și apoi îl serializează în fișierul de memorie hash, reducând astfel substanțial timpul. Este, de asemenea, cunoscut sub numele de Map Side Join in Hive. Practic, implică efectuarea de îmbinări între 2 tabele folosind doar faza Map și sărirea fazei Reduce. O scădere a timpului în calculul întrebărilor dvs. poate fi observată dacă utilizează în mod regulat un mic tabel.
Sintaxa pentru harta Alăturați-vă în stup
Dacă dorim să efectuăm o interogare de aderare folosind harta-unire, trebuie să specificăm un cuvânt cheie „/ * + MAPJOIN (b) * /” în enunțul de mai jos:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Pentru acest exemplu, trebuie să creăm 2 tabele cu nume tablename1 și tablename2 având 2 coloane: emp_id și emp_name. Unul ar trebui să fie un fișier mai mare și unul mai mic.
Înainte de a rula interogarea, trebuie să setăm proprietatea de mai jos pe true:
hive.auto.convert.join=true
Interogarea de unire pentru hartă este înscrisă ca mai sus, iar rezultatul pe care îl obțin este:
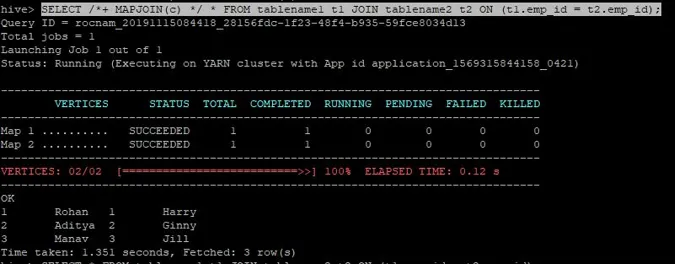
Interogarea sa finalizat în 1.351 de secunde.
Exemple de hartă Alăturați-vă în stup
Iată următoarele exemple menționate mai jos
1. Exemplu de alăturare a hărții
Pentru acest exemplu, să creăm 2 tabele numite table1 și table2 cu 100 și respectiv 200 de înregistrări. Puteți consulta comanda de mai jos și capturile de ecran pentru a executa același lucru:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Acum încărcăm înregistrările în ambele tabele folosind comenzile de mai jos:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Să efectuăm o interogare normală de aderare la hartă pe ID-urile lor, așa cum se arată mai jos, și să verificăm timpul necesar pentru același lucru:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
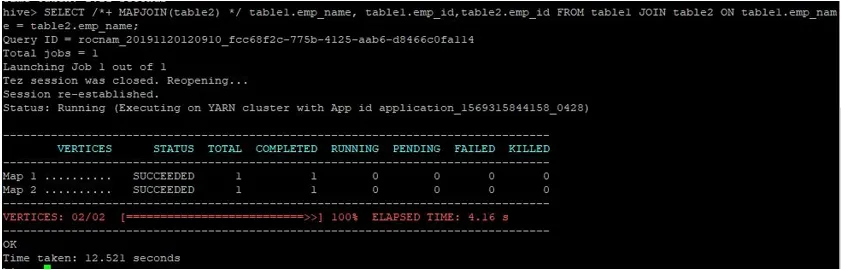
După cum putem vedea, o interogare normală de hartă-hartă a durat 12.521 secunde.
2. Exemplu de îmbinare cu bucket-map
Să folosim acum Bucket-map join pentru a rula la fel. Există câteva constrângeri care trebuie urmate pentru găleată:
- Găile pot fi unite între ele numai dacă totalul găleților din oricare tabel este multiplu din numărul de găleți din celălalt tabel.
- Trebuie să aibă mese cu găleată pentru a efectua găleata. Prin urmare, să creăm același lucru.
Următoarele sunt comenzile utilizate pentru a crea tabele bucketed table1 și table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Vom insera aceleași înregistrări din tabelul1 în aceste tabele cu găleți:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
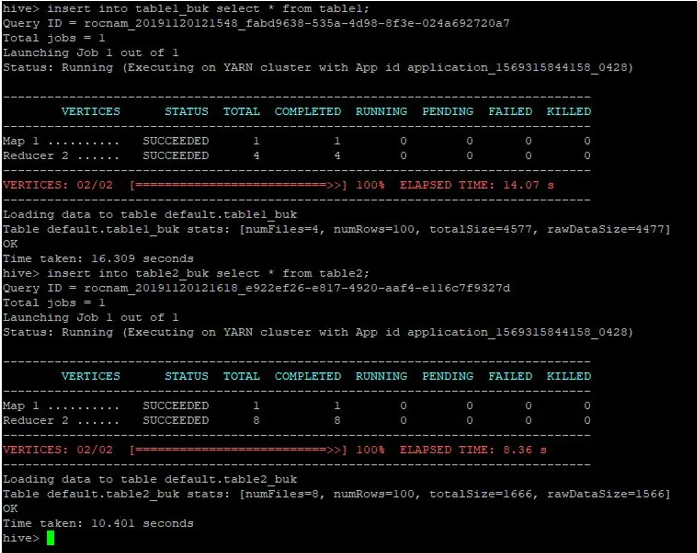
Acum că avem cele 2 tabele cu găleată, permiteți-ne să realizăm o îmbinare-bucket-map pe acestea. Primul tabel are 4 găleți, în timp ce cel de-al doilea tabel are 8 găleți create pe aceeași coloană.
Pentru ca să funcționeze interogarea cu bucket-map, ar trebui să setăm proprietatea de mai jos pe true în stup:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
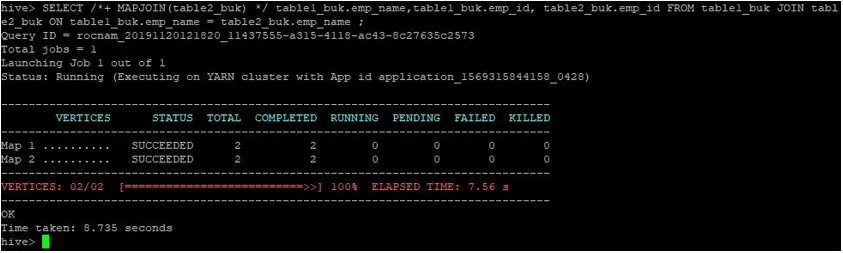
După cum putem vedea, interogarea a fost finalizată în 8.735 de secunde, ceea ce este mai rapid decât o aderare normală pe hartă.
3. Sortare Exemplu de îmbinare a hărții găleată (SMB)
SMB poate fi executat pe tabele cu găleți care au același număr de găleți și dacă tabelele trebuie sortate și găleate pe coloanele de îmbinare. Nivelul de mapare se alătură în mod corespunzător acestor găleți.
La fel ca în unirea cu bucket-map, există 4 găleți pentru masa1 și 8 găleți pentru masa2. Pentru acest exemplu, vom crea un alt tabel cu 4 găleți.
Pentru a rula interogarea SMB, trebuie să setăm următoarele proprietăți ale stupului, așa cum se arată mai jos:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Pentru a efectua aderarea SMB trebuie să fie sortate date conform coloanelor de unire. Prin urmare, vom suprascrie datele din tabelul 1 bucketed ca mai jos:
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Datele sunt sortate acum, care pot fi văzute în imaginea de mai jos:
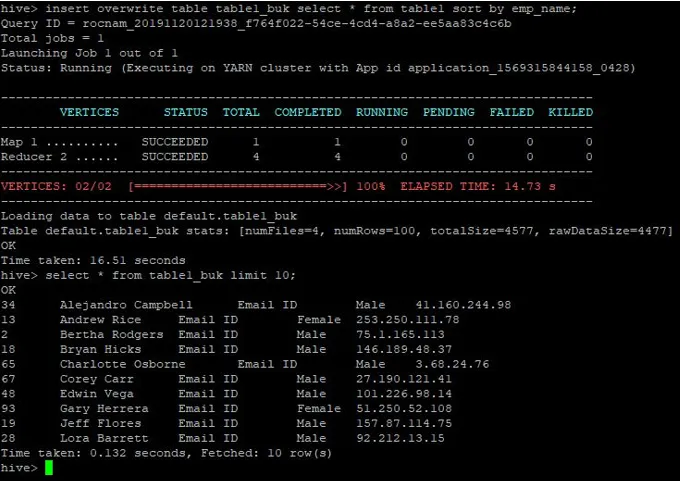
De asemenea, vom suprascrie datele în tabelul cu secțiune2 după cum urmează:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Să realizăm unirea pentru cele 2 tabele de mai sus, după cum urmează:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
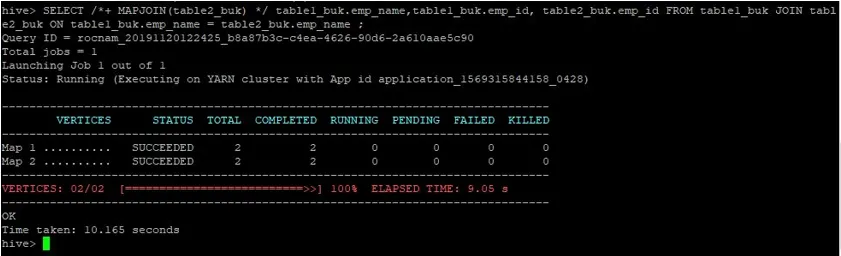
Putem vedea că interogarea a durat 10, 165 secunde, care este din nou mai bună decât o aderare normală pe hartă.
Să creăm acum un alt tabel pentru table2 cu 4 găleți și aceleași date sortate cu emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
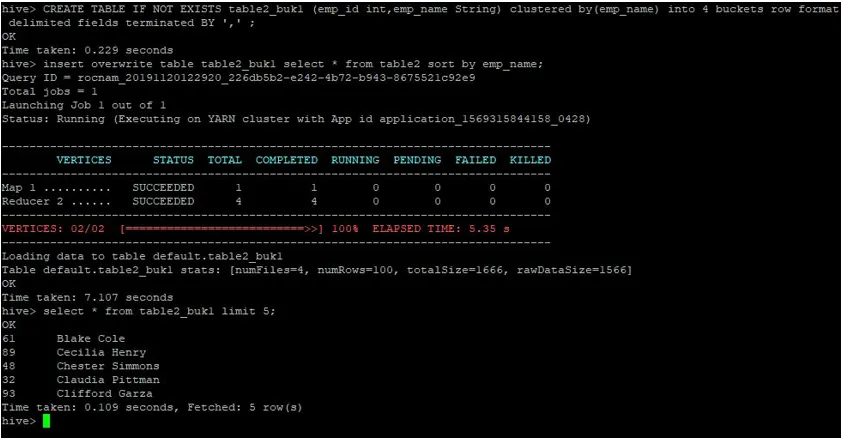
Având în vedere că acum avem ambele tabele cu 4 găleți, să efectuăm din nou o interogare de unire.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Interogarea a durat din nou 8.851 de secunde mai repede decât interogarea cu harta normală.
avantaje
- Map join reduce timpul necesar proceselor de sortare și îmbinare care au loc în shuffle și reduce etapele reducând astfel și costurile.
- Crește eficiența performanței sarcinii.
limitări
- Aceeași tabelă / alias nu este permisă pentru unirea coloanelor diferite în aceeași interogare.
- Interogarea de aderare la hartă nu poate converti îmbinările exterioare complete în unirile laterale ale hărții.
- Alăturarea pe hartă poate fi efectuată numai atunci când una dintre tabele este suficient de mică pentru a putea fi potrivită memoriei. Prin urmare, nu poate fi executată acolo unde datele din tabel sunt uriașe.
- O alăturare la stânga este posibilă pentru o alăturare pe hartă numai atunci când dimensiunea dreaptă a tabelului este mică.
- O alăturare dreapta poate fi făcută la o alăturare pe hartă numai atunci când dimensiunea stânga a tabelului este mică.
Concluzie
Am încercat să includem cele mai bune puncte posibile ale Map Join in Hive. După cum am văzut mai sus, alăturarea pe hartă funcționează cel mai bine atunci când un tabel are mai puține date, astfel încât lucrarea să fie completată rapid. Timpul necesar pentru interogările prezentate aici depinde de dimensiunea setului de date, prin urmare, timpul afișat aici este doar pentru analiză. Aderarea la hartă poate fi implementată cu ușurință în aplicații în timp real, deoarece avem date uriașe, contribuind astfel la reducerea traficului de I / O din rețea.
Articole recomandate
Acesta este un ghid pentru Map Join in Hive. Aici discutăm exemplele de Map Join in Hive împreună cu Avantajele și limitările. De asemenea, puteți consulta articolul următor pentru a afla mai multe -
- Se alătură în stup
- Funcții încorporate stup
- Ce este un stup?
- Comenzile stupului