
Ce este algoritmul SVM?
SVM înseamnă Mașină Vector Suport. SVM este un algoritm de învățare automată supravegheat, care este frecvent utilizat pentru provocările de clasificare și regresie. Aplicațiile obișnuite ale algoritmului SVM sunt sistemul de detectare a intruziunilor, recunoașterea scrisului de mână, predicția structurii proteice, detectarea steganografiei în imagini digitale etc.
În algoritmul SVM, fiecare punct este reprezentat ca un element de date în spațiul n-dimensional unde valoarea fiecărei caracteristici este valoarea unei coordonate specifice.
După complotare, clasificarea a fost efectuată prin găsirea planului hype care diferențiază două clase. Consultați imaginea de mai jos pentru a înțelege acest concept.
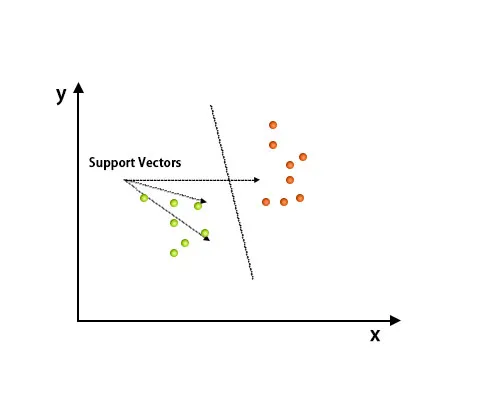
Algoritmul suport Vector Machine este utilizat în principal pentru rezolvarea problemelor de clasificare. Vectorii de asistență nu sunt altceva decât coordonatele fiecărui element de date. Suportul Vector Machine este o frontieră care diferențiază două clase folosind hiperplanul.
Cum funcționează algoritmul SVM?
În secțiunea de mai sus, am discutat despre diferențierea a două clase folosind hiperplanul. Acum vom vedea cum funcționează de fapt acest algoritm SVM.
Scenariul 1: Identificați hiperplanul potrivit
Aici am luat trei hiperplane adică A, B și C. Acum trebuie să identificăm hiperplanul drept pentru a clasifica stea și cerc.
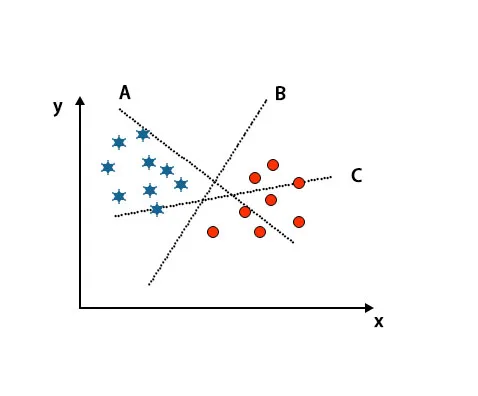
Pentru a identifica hiperplanul potrivit trebuie să cunoaștem regula degetului mare. Selectați hiperplanul care diferențiază două clase. În imaginea menționată mai sus, hiperplanul B diferențiază foarte bine două clase.
Scenariul 2: Identificați hiperplanul potrivit
Aici am luat trei hiperplane adică A, B și C. Aceste trei hiperplane deja diferențiază foarte bine clasele.
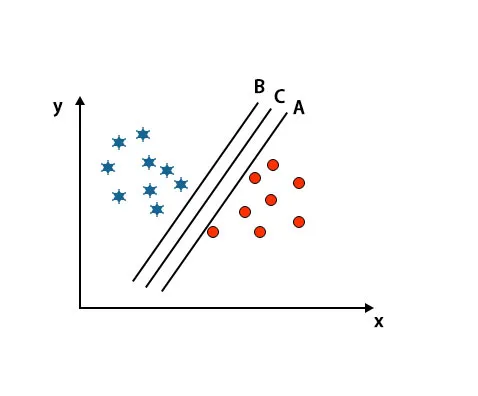
În acest scenariu, pentru a identifica hiperplanul drept creștem distanța dintre cele mai apropiate puncte de date. Această distanță nu este decât o marjă. Consultați imaginea de mai jos.
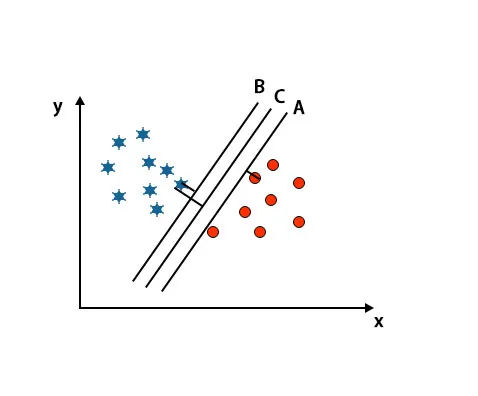
În imaginea menționată mai sus, marja hiperplanului C este mai mare decât hiperplanul A și hiperplanul B. Deci, în acest scenariu, C este hiperplanul drept. Dacă alegem hiperplanul cu o marjă minimă, poate duce la o clasificare greșită. Prin urmare, am ales hiperplanul C cu marja maximă datorită robustetei.
Scenariul 3: Identificați hiperplanul potrivit
Notă: Pentru a identifica hiperplanul, urmați aceleași reguli menționate în secțiunile anterioare.
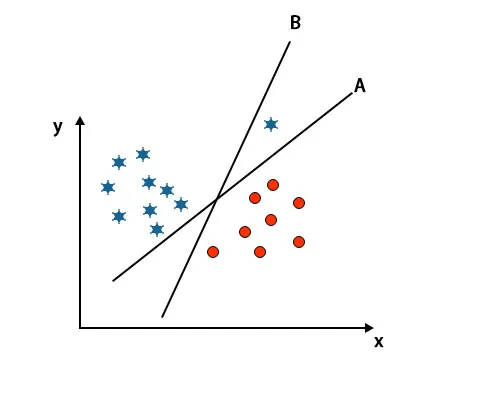
După cum puteți vedea în imaginea menționată mai sus, marja hiperplanului B este mai mare decât marja hiperplanului A, de aceea unii vor selecta hiperplanul B drept. Dar în algoritmul SVM, selectează acel hiperplan care clasifică clasele exacte înainte de maximizarea marjei. În acest scenariu, hiperplanul A a clasificat toate cu exactitate și există o eroare. Cu clasificarea hiperplanului B. Prin urmare, A este hiperplanul corect.
Scenariul 4: Clasificați două clase
După cum puteți vedea în imaginea menționată mai jos, nu putem să diferențiem două clase folosind o linie dreaptă, deoarece o stea se află ca o ieșire din clasa cealaltă cerc.
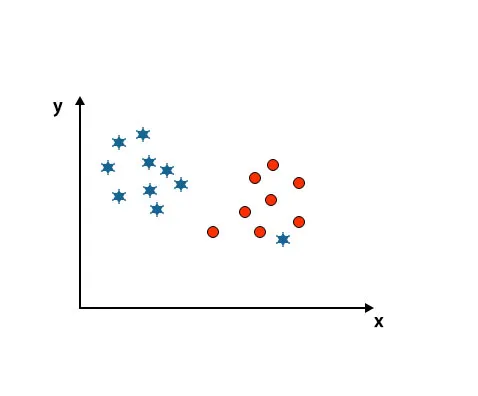
Aici, o stea este într-o altă clasă. Pentru clasa de stele, această stea este cea mai veche. Datorită proprietății de rezistență a algoritmului SVM, acesta va găsi hiperplanul potrivit cu marja superioară ignorând un aspect mai vechi.
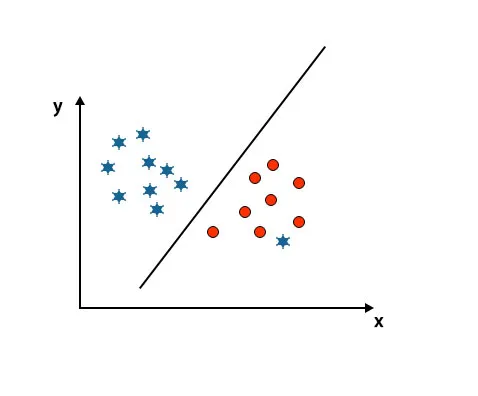
Scenariul 5: Hiperplan fin pentru diferențierea claselor
Până acum am arătat hiperplan liniar. În imaginea menționată mai jos, nu avem un hiperplan liniar între clase.
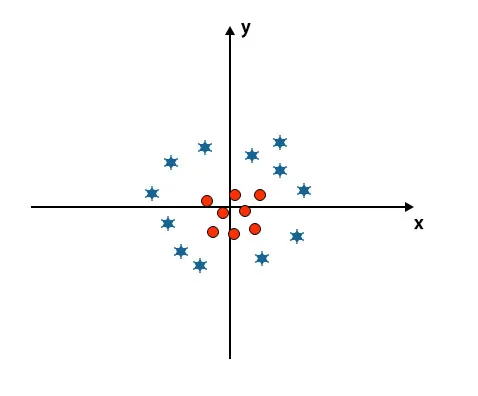
Pentru a clasifica aceste clase, SVM introduce câteva caracteristici suplimentare. În acest scenariu, vom folosi această nouă caracteristică z = x 2 + y 2.
Plasează toate punctele de date pe axa x și z.

Notă
- Toate valorile pe axa z ar trebui să fie pozitive, deoarece z este egal cu suma x x pătrat și y pătrat.
- În graficul menționat mai sus, cercurile roșii sunt închise la originea axei X și axa Y, ceea ce duce valoarea lui z în jos și stea este exact opusul cercului, este departe de originea axei x și axa y, conducând valoarea z la mare.
În algoritmul SVM, este ușor de clasificat folosind hiperplan liniar între două clase. Dar întrebarea apare aici este dacă ar trebui să adăugăm această caracteristică a SVM pentru a identifica hiperplanul. Deci, răspunsul este nu, pentru a rezolva această problemă SVM are o tehnică care este cunoscută în mod obișnuit sub numele de truc de kernel.
Trucul Kernel este funcția care transformă datele într-o formă adecvată. Există diferite tipuri de funcții de kernel utilizate în algoritmul SVM, adică Polinomial, liniar, neliniar, Funcție de bază radială, etc.
Când privim hiperplanul originea axei și axa Y, pare un cerc. Consultați imaginea de mai jos.
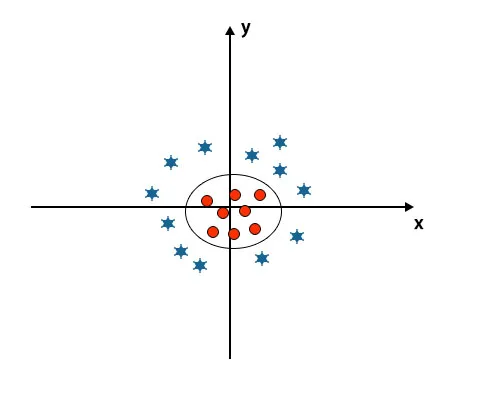
Beneficiile algoritmului SVM
- Chiar dacă datele de intrare sunt neliniare și non-separabile, SVM-urile generează rezultate de clasificare exacte din cauza robustetei sale.
- În funcția decizională, utilizează un subset de puncte de instruire numite vectori de sprijin, deci este eficient în memorie.
- Este util să rezolvați orice problemă complexă cu o funcție de sâmbure adecvată.
- În practică, modelele SVM sunt generalizate, cu un risc mai mic de supraîncărcare în SVM.
- SVM-urile funcționează excelent pentru clasificarea textului și pentru găsirea celui mai bun separator liniar.
Contra de algoritm SVM
- Este nevoie de o perioadă lungă de pregătire atunci când lucrați cu seturi de date mari.
- Este greu de înțeles modelul final și impactul individual.
Concluzie
A fost ghidat pentru Suportul Vectorului Algoritm, care este un algoritm de învățare a mașinilor. În acest articol, am discutat despre ce este algoritmul SVM, cum funcționează și despre avantajele sale în detaliu.
Articole recomandate
Acesta a fost un ghid pentru algoritmul SVM. Aici vom discuta modul de lucru cu un scenariu, pro și contra de algoritm SVM. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Algoritmi de extragere a datelor
- Tehnici de exploatare a datelor
- Ce este învățarea automată?
- Instrumente de învățare a mașinilor
- Exemple de algoritm C ++