
Introducere în ciclul de știință a datelor
Data Science Lifecycle se învârte în jurul utilizării învățării automate și a altor metode analitice pentru a produce perspective și predicții din date pentru a atinge un obiectiv de afaceri. Întregul proces implică mai multe etape precum curățarea datelor, pregătirea, modelarea, evaluarea modelului, etc. Este un proces lung și poate dura câteva luni până la finalizare. Deci, este foarte important să avem o structură generală care să fie respectată pentru fiecare problemă la îndemână. Structura recunoscută la nivel mondial în rezolvarea oricărei probleme analitice se numește Procesul standard de industrie încrucișată pentru data mining sau cadrul CRISP-DM
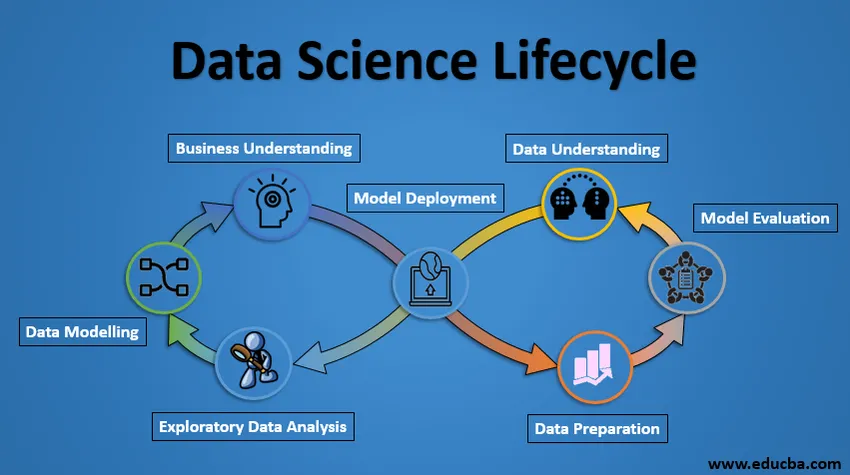
Ciclu de știință a datelor
Mai jos sunt proiectul Lifecycle of Data Science.
1. Înțelegerea afacerilor
Întregul ciclu se învârte în jurul obiectivului de afaceri. Ce veți rezolva dacă nu aveți o problemă precisă? Este extrem de important să înțelegeți clar obiectivul de afaceri, deoarece acesta va fi obiectivul final al analizei. După o înțelegere corectă, putem stabili obiectivul specific de analiză care este în sincronizare cu obiectivul de afaceri. Trebuie să știți dacă clientul dorește să reducă pierderea creditului sau dacă dorește să prezice prețul unei mărfuri etc.
2. Înțelegerea datelor
După înțelegerea afacerilor, următorul pas este înțelegerea datelor. Aceasta implică colectarea tuturor datelor disponibile. Aici trebuie să lucrați îndeaproape cu echipa de afaceri, deoarece sunt conștienți de fapt ce date sunt prezente, ce date ar putea fi utilizate pentru această problemă de afaceri și alte informații. Acest pas implică descrierea datelor, structura lor, relevanța lor, tipul lor de date. Explorați datele utilizând graficele grafice. Practic, extragerea informațiilor pe care le puteți obține despre date doar explorând datele.
3. Pregătirea datelor
Urmează etapa de pregătire a datelor. Aceasta include pași precum selectarea datelor relevante, integrarea datelor prin contopirea seturilor de date, curățarea acestora, tratarea valorilor care lipsesc, fie eliminându-le sau imputându-le, tratarea datelor eronate prin eliminarea acestora, verificați, de asemenea, valorile care utilizează comploturile casetelor și le gestionați . Construirea de noi date, obține noi caracteristici de la cele existente. Formatați datele în structura dorită, eliminați coloanele și funcțiile nedorite. Pregătirea datelor este cea mai consumatoare de timp, dar probabil cea mai importantă etapă din întregul ciclu de viață. Modelul dvs. va fi la fel de bun ca datele dvs.
4. Analiza datelor exploratorii
Acest pas implică o idee despre soluția și factorii care o afectează, înainte de a construi modelul propriu-zis. Distribuția de date în diferite variabile ale unei caracteristici este explorată grafic folosind barele grafice, relațiile dintre diferite caracteristici sunt capturate prin reprezentări grafice precum graficele de împrăștiere și hărțile de căldură. Multe alte tehnici de vizualizare a datelor sunt utilizate pe scară largă pentru a explora fiecare caracteristică individual și prin combinarea acestora cu alte funcții.
5. Modelarea datelor
Modelarea datelor este nucleul analizei datelor. Un model ia datele de pregătire ca intrare și oferă rezultatul dorit. Această etapă include alegerea tipului adecvat de model, indiferent dacă problema este o problemă de clasificare, sau o problemă de regresie sau o problemă de clustering. După alegerea familiei de modele, printre diverși algoritmi din acea familie, trebuie să alegem cu atenție algoritmii care să le implementeze și să le implementeze. Trebuie să reglăm hiperparametrele fiecărui model pentru a obține performanțele dorite. De asemenea, trebuie să ne asigurăm că există un echilibru corect între performanță și generalizare. Nu dorim ca modelul să învețe datele și să funcționeze slab pe date noi.
6. Evaluarea modelului
Aici modelul este evaluat pentru a verifica dacă este gata de a fi implementat. Modelul este testat pe date nevăzute, evaluate pe un set atent de metrici de evaluare. De asemenea, trebuie să ne asigurăm că modelul se conformează realității. Dacă nu obținem un rezultat satisfăcător în evaluare, trebuie să reiterăm întregul proces de modelare până la atingerea nivelului dorit de valori. Orice soluție de știință a datelor, un model de învățare automată, la fel ca un om, ar trebui să evolueze, ar trebui să poată să se îmbunătățească cu date noi, să se adapteze la o nouă măsurătoare de evaluare. Putem construi mai multe modele pentru un anumit fenomen, dar multe dintre ele pot fi imperfecte. Evaluarea modelului ne ajută să alegem și să construim un model perfect.
7. Implementarea modelului
Modelul după o evaluare riguroasă este în sfârșit implementat în formatul și canalul dorit. Acesta este ultimul pas în ciclul de viață al științei datelor. Fiecare pas din ciclul de viață al științei datelor explicat mai sus ar trebui să fie lucrat cu atenție. Dacă orice pas este executat în mod necorespunzător, acesta va afecta în consecință următorul pas și întregul efort se va pierde. De exemplu, dacă datele nu sunt colectate corect, veți pierde informații și nu veți construi un model perfect. Dacă datele nu sunt curățate corect, modelul nu va funcționa. Dacă modelul nu este evaluat corect, acesta va eșua în lumea reală. De la înțelegerea afacerilor până la desfășurarea modelului, fiecărui pas trebuie acordată atenție, timp și efort adecvat.
Articole recomandate
Acesta este un ghid pentru ciclul de știință a datelor. Aici discutăm o imagine de ansamblu asupra ciclului de știință a datelor și pașii care alcătuiesc un ciclu de viață al științei datelor. De asemenea, puteți parcurge articolele noastre conexe pentru a afla mai multe -
- Introducere în algoritmii de știință a datelor
- Știința datelor vs Ingineria software | Top 8 comparații utile
- Diferențe Tipuri de tehnici de știință a datelor
- Abilități de știință a datelor cu tipuri