

Introducere în Apache Flume
Apache Flume este Data Ingestion Framework care scrie date bazate pe evenimente în sistemul de fișiere distribuite Hadoop. Este cunoscut faptul că Hadoop prelucrează date mari, se pune întrebarea modul în care datele generate de diferite servere web sunt transmise către sistemul de fișiere Hadoop? Răspunsul este Apache Flume. Flume este proiectat pentru ingestia de date de volum mare către Hadoop de date bazate pe evenimente.
Luați în considerare un scenariu în care numărul de servere web generează fișiere jurnal și aceste fișiere jurnal trebuie să le transmită sistemului de fișiere Hadoop. Flume colectează acele fișiere ca evenimente și le ingerează la Hadoop. Deși Flume este utilizat pentru a transmite Hadoop, nu există o regulă rigidă că destinația trebuie să fie Hadoop. Flume este capabil să scrie la alte cadre precum Hbase sau Solr.
Arhitectura Flume
În general, arhitectura Apache Flume este compusă din următoarele componente:
- Sursa de flume
- Flume Channel
- Chiuveta cu apa
- Agent de flori
- Flume Event
Să aruncăm o privire scurtă a fiecărei componente Flume
1. Sursa de flume
O sursă de flume este prezentă pe generatoare de date precum Face book sau Twitter. Source colectează date de la generator și transferă aceste date în Flume Channel sub formă de Flume Events. Flume acceptă diferite tipuri de surse precum Avro Flume Source - se conectează pe portul Avro și primește evenimente de la clientul Avro extern, Thrift Flume Source - se conectează la portul Thrift și primește evenimente din fluxurile clientului extern Thrift, Spooling Directory Source și Kafka Flume Source.
2. Canalul Flume
Un magazin intermediar care tamponează evenimentele trimise de Flume Source până când sunt consumate de Sink se numește Flume Channel. Canalul funcționează ca o punte intermediară între Sursă și Sink. Canalele de flume sunt de natură tranzacțională.
Flume oferă asistență pentru canalul File și pentru memoria. Canalul fișierului este de natură durabilă, ceea ce înseamnă că, odată ce datele sunt scrise pentru a le canaliza, nu se vor pierde, deși dacă agentul repornește. În memorie, evenimentele canalului sunt stocate în memorie, deci nu este durabil, dar foarte rapid în natură.
3. Chiuveta cu flume
Sink Flume este prezent în depozitele de date precum HDFS, HBase. Chiuveta cu flume consumă evenimente de pe Channel și le stochează în magazinele Destinație precum HDFS. Nu există nicio regulă de genul ca chiuveta să livreze evenimente în Magazin, în schimb, o putem configura în așa fel încât o chiuvetă să poată livra evenimente unui alt agent. Flume acceptă diferite chiuvete precum HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
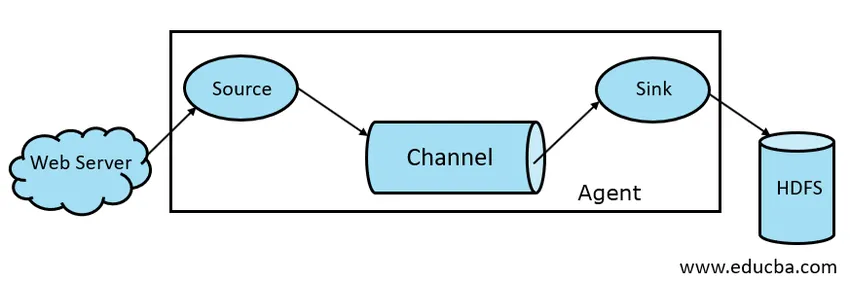
Fig 1.1 Arhitectura de bază a flumelor
4. Agent de flume
Un agent Flume este un proces Java de lungă durată, care se execută pe combinația Source - Channel - Sink Combination. Flume poate avea mai mult de un agent. Putem considera Flume ca o colecție de agenți Flume conectați care sunt distribuiți în natură.
5. Eveniment Flume
Un eveniment este unitatea de date transportată în Flume . Reprezentarea generală a obiectului de date în Flume se numește Eveniment. Evenimentul este format dintr-o sarcină utilă a unui tablou de octeți cu anteturi opționale.
Lucrări de flume
Un agent Flume este un proces java care constă din Source - Channel - Sink în cea mai simplă formă. Sursa colectează date de la generatorul de date sub formă de evenimente și le livrează canalului. O sursă poate livra pe mai multe canale, conform cerințelor. Fan out este procesul în care o singură sursă va scrie pe mai multe canale, astfel încât să poată livra la mai multe chiuvete.
Un eveniment este unitatea de bază a datelor transmise în Flume. Channel memorează datele până când sunt ingerate de Sink. Sink colectează datele de la Channel și le livrează la stocarea de date centralizată, cum ar fi HDFS sau Sink, care poate transmite evenimentele către un alt agent Flume, conform cerințelor.
Flume acceptă tranzacții. Pentru a obține fiabilitatea, Flume folosește tranzacții separate de la sursă la canal și de la canal la chiuvetă. Dacă evenimentele nu sunt livrate, atunci tranzacția este redusă și redirecționată ulterior.
Pentru a înțelege modul de funcționare al Flume, să luăm un exemplu de configurare Flume unde sursa este directorul de spooling și sink este Hdfs. În acest exemplu, agentul Flume este sub forma cea mai simplă, adică topologia sursă unică - canal - sink, care este configurată folosind un fișier de proprietăți java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
În exemplul de configurație de mai sus, agentul este baza cu care definim alte proprietăți. source1 și sink1 și channel1 sunt numele sursei, sink și canal respectiv, iar tipurile și locațiile lor sunt, de asemenea, menționate în consecință.
Avantajele Fluxului Apache
- Flume este scalabil, fiabil și rezistent la erori. Aceste proprietăți sunt discutate în detaliu mai jos
- Scalabil - Flume este scalabil pe orizontală, adică putem adăuga noi noduri conform cerinței noastre
- De încredere - Apache Flume are suport pentru tranzacții și se asigură că nu se pierd date în procesul de transmitere a datelor. Are diferite tranzacții de la sursă la canal și de la canal la sursă.
- Flume este personalizabil și oferă suport pentru diverse surse și chiuvete precum Kafka, Avro, directorul de spooling, Thrift etc
- În Flume, o singură sursă poate transmite date pe mai multe canale, iar aceste canale la rândul lor vor transmite datele la mai multe chiuvete, astfel o singură sursă poate transmite date către mai multe chiuvete. Acest mecanism se numește Fan out. Flume este, de asemenea, acceptat pentru Fan afară.
- Flume oferă fluxul constant de transmisie a datelor, adică dacă viteza de citire a datelor crește și apoi viteza de scriere a datelor crește.
- Deși Flume scrie în general date în stocare centralizată, cum ar fi HDFS sau Hbase, putem configura Flume conform cerinței noastre, astfel încât Sink să poată scrie date unui alt agent. Acest lucru arată flexibilitatea Flume
- Apache Flume este open source în natură.
Concluzie
În acest articol Flume, componentele Flume și lucrările Flume sunt discutate în detaliu. Flume este o platformă flexibilă, fiabilă și scalabilă pentru a transmite date unui magazin centralizat precum HDFS. Abilitatea sa de a se integra cu diferite aplicații precum Kafka, Hdfs, Thrift face din opțiunea sa viabilă pentru ingerarea datelor.
Articole recomandate
Acesta a fost un ghid pentru Apache Flume. Aici discutăm despre arhitectura, funcționarea și avantajele Apache Flume. De asemenea, puteți arunca o privire la următoarele articole pentru a afla mai multe -
- Ce este Apache Flink?
- Diferența dintre Apache Kafka și Flume
- Arhitectura Big Data
- Instrumente Hadoop
- Aflați diferitele evenimente JavaScript