
Diferențele dintre Data Scientist și Machine Learning
Un cercetător de date este un expert responsabil pentru colectarea, examinarea și interpretarea volumelor mari de date pentru a recunoaște modalitățile de a ajuta o afacere să își îmbunătățească operațiunile și să obțină un avantaj viabil față de rivali. Urmează o abordare interdisciplinară. Se află între conexiunea matematicii, statisticii, ingineriei software, inteligenței artificiale și gândirii de design. Se ocupă cu colectarea datelor, curățarea, analiza, vizualizarea, modelul de validare, predicția experimentelor, proiectarea, testarea și ipoteza multe în continuare. Învățarea automată este o diviziune a inteligenței artificiale care este folosită de știința datelor pentru a-și atinge obiectivele. Învățarea automată se concentrează în principal pe algoritmi, structuri polinomiale și adăugare de cuvinte. Este format dintr-un grup de algoritmi, mașini și care le permite să învețe fără a fi clar programat pentru aceasta.
Data științific
Acest rol Data Scientist este o ramură a rolului statisticilor care include utilizarea tehnologiilor analitice versiunea avansată, inclusiv învățarea automată și modelarea predictivă, pentru a oferi viziuni dincolo de analiza statistică. Petiția pentru abilitățile de știință a datelor a crescut semnificativ în ultimii ani, deoarece companiile urmăresc să colecteze informații utile din cantitățile uriașe de date structurate, semi-structurate și nestructurate pe care o întreprindere mare le produce și denumite colectiv date mari. Scopul tuturor etapelor este doar să obținem informații din date.
Sarcini standard:
- Alocați, agregați și sintetizați date din diverse surse structurate și nestructurate
- Explorați, dezvoltați și aplicați învățarea inteligentă pentru datele din lumea reală, oferiți rezultate importante și acțiuni de succes bazate pe ele
- Analizați și furnizați datele colectate în organizație
- Proiectarea și construirea de noi procese de modelare, extragere de date și implementare
- Dezvolta prototipuri, algoritmi, modele predictive, prototipuri
- Efectuați cererile de analiză a datelor și comunicați constatările și deciziile acestora
În plus, există mai multe sarcini specifice în funcție de domeniul în care angajatorul lucrează sau de implementarea proiectului.
Date brute -> Știința datelor ---> Informații acționabile
Învățare automată
Poziția inginerului Machine Learning este mai „tehnică”. ML Engineer are mai multe în comun cu Ingineria software clasică decât Data Scientist. Vă ajută să aflați funcția obiectivă care plasează intrările către variabila țintă și / sau variabile independente pentru variabilele dependente.
Sarcinile standard ale ML Engineer sunt în general ca Data Scientist. De asemenea, trebuie să fiți capabil să lucrați cu date, să experimentați diferiți algoritmi de Machine Learning care vor rezolva sarcina, vor crea prototipuri și soluții gata făcute.
Cunoștințele și abilitățile necesare pentru această poziție se suprapun și cu Data Scientist. Dintre diferențele cheie, aș evidenția:
- Abilități puternice de programare în unul sau mai multe limbaje populare (de obicei Python și Java), precum și în baze de date;
- Mai puțin accent pe capacitatea de a lucra în mediile de analiză a datelor, dar mai mult accent pe algoritmii de învățare automată;
- R și Python pentru modelare sunt preferabile Matlab, SPSS și SAS;
- Posibilitatea de a utiliza biblioteci gata pentru diverse stive în aplicație, de exemplu, Mahout, Lucene pentru Java, NumPy / SciPy pentru Python;
- Posibilitatea de a crea aplicații distribuite folosind Hadoop și alte soluții.
După cum puteți vedea, poziția ML Engineer (sau mai restrânsă) necesită mai multe cunoștințe în Ingineria Software și, în consecință, este potrivită pentru dezvoltatorii cu experiență. Destul de des, cazul funcționează atunci când dezvoltatorul obișnuit trebuie să rezolve sarcina ML pentru datoria sa, iar el începe să înțeleagă algoritmii și bibliotecile necesare.
Comparație față în cap între științistul de date și învățarea mașinii
Mai jos se află primele 5 diferențe între savantul de date și inginerul Machine Learning 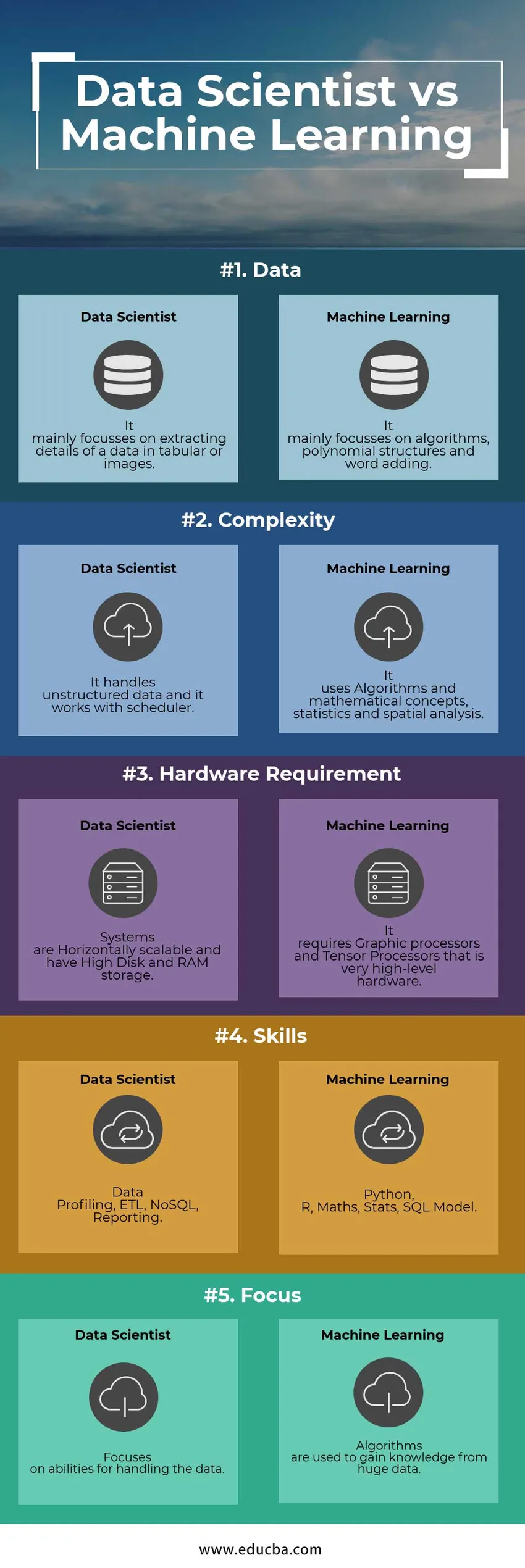
Diferența cheie între data de știință de știință și de învățare automată
Mai jos sunt listele de puncte, descrieți diferențele cheie între Data Scientist și inginerul Machine Learning
- Învățarea automată și statisticile fac parte din știința datelor. Învățarea cuvântului în învățarea automată înseamnă că algoritmii depind de anumite date, utilizate ca un set de instruire, pentru a regla anumite parametri de model sau algoritm. Aceasta cuprinde multe tehnici, cum ar fi regresia, Bayes naiv sau clusteringul supravegheat. Dar nu toate tehnicile se încadrează în această categorie. De exemplu, clustering-ul nesupravegheat - o tehnică statistică și științifică a datelor - are ca scop detectarea clusterelor și structurilor clusterului, fără a exista cunoștințe prealabile sau un set de pregătire care să ajute algoritmul de clasificare. O ființă umană este necesară pentru a eticheta grupurile găsite. Unele tehnici sunt hibride, cum ar fi clasificarea semi-supravegheată. Unele tehnici de detectare a modelului sau de estimare a densității se încadrează în această categorie.
- Știința datelor este mult mai mult decât învățarea automată. Datele, în știința datelor, pot sau nu provin dintr-o mașină sau un proces mecanic (datele sondajului ar putea fi colectate manual, studiile clinice implică un tip specific de date mici) și s-ar putea să nu aibă nicio legătură cu învățarea așa cum am discutat. Dar diferența principală este faptul că știința datelor acoperă întregul spectru de prelucrare a datelor, nu doar aspectele algoritmice sau statistice. Știința datelor acoperă, de asemenea, integrarea datelor, arhitectura distribuită, învățarea automată a mașinilor, vizualizarea datelor, tablourile de bord și ingineria Big Data.
Data Scientist vs. Tabelul de comparare a învățării mașinilor
Următoarele sunt listele de puncte, descrieți comparațiile dintre Data Scientist și inginerul Machine Learning:
| Caracteristică | Data științific | Învățare automată |
| Date | Se concentrează în principal pe extragerea detaliilor unei date în tabele sau imagini | Se concentrează în principal pe algoritmi, structuri polinomiale și adăugare de cuvinte |
| Complexitate | Gestionează datele nestructurate și funcționează cu programatorul | Utilizează algoritmi și concepte matematice, statistici și analize spațiale |
| Cerințe hardware | Sistemele sunt scalabile orizontal și dispun de un disc înalt și de stocare RAM | Necesită procesoare grafice și procesoare cu tensiune, care sunt hardware la nivel înalt |
| Aptitudini | Profilare date, ETL, NoSQL, raportare | Python, R, Matematică, Statistici, Model SQL |
| concentra | Se concentrează pe abilitățile de manipulare a datelor | Algoritmii sunt folosiți pentru a obține cunoștințe din date uriașe |
Concluzie - Data Scientist vs Machine Learning
Învățarea automată vă ajută să învățați funcția obiectivă care plasează intrările către variabila țintă și / sau variabile independente pentru variabilele dependente
Un om de știință de date face o mulțime de explorare a datelor și ajunge la strategia largă de abordare a acestora. El este responsabil pentru a pune întrebări în interiorul datelor și a găsi ce răspunsuri se pot trage în mod rezonabil din date. Ingineria caracteristică aparține domeniului Data Scientist. Creativitatea joacă, de asemenea, un rol aici, iar un inginer Machine Learning cunoaște mai multe instrumente și poate construi modele date cu un set de caracteristici și date - conform indicațiilor de la Data Scientist. Domeniul pre-procesării datelor și extragerea caracteristicilor aparține inginerului ML.
Știința și examinarea datelor utilizează învățarea automată pentru acest tip de validare și creare arhetipală. Este esențial să rețineți că toți algoritmii din acest model de creare pot să nu provină din învățarea automată. Pot ajunge din numeroase alte domenii. Modelul dorește să fie păstrat relevant întotdeauna. Dacă situațiile se schimbă, atunci modelul pe care l-am creat mai devreme poate deveni imaterial. Cerințele modelului care trebuie verificate pentru certitudinea sa în diferite momente și trebuie adaptate dacă certitudinea acestuia se reduce.
Știința datelor este un domeniu cu totul mare. Dacă am încerca să o introducem într-o conductă, ar avea achiziție de date, stocare de date, preprocesare de date sau curățare de date, tipare de învățare în date (prin învățare automată), folosind învățare pentru predicții. Acesta este un mod de a înțelege modul în care învățarea automată se încadrează în știința datelor.
Articol recomandat
Acesta a fost un ghid pentru diferențele dintre oamenii de știință de date față de inginerul de învățare în mașini, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparație și concluzii. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Minerirea datelor vs învățarea mașinii - 10 cele mai bune lucruri pe care trebuie să le știi
- Învățare automată față de analize predictive - 7 diferențe utile
- Data scientist vs Business Analyst - Aflați cele 5 deosebiri minunate
- Data Scientist vs Data Engineer - 7 comparații uimitoare
- Întrebări de interviu pentru inginerie software | Top and Most Întrebat