

Diferența dintre Hadoop și HBase
Hadoop este un cadru Java open-source, utilizat pentru gestionarea și procesarea unei cantități imense de date structurate și nestructurate. Hadoop este masiv scalabil, prin urmare, este utilizat pentru a procesa sarcini mari de date. Datele mari sunt stocate, accesate și procesate în clusterul fiabil și extensibil. HBase (baza de date Hadoop) este o bază de date non-relațională și nu numai SQL, adică o bază de date NoSQL, care rulează pe partea de sus a Hadoop ca un depozit de date mari distribuit și scalabil. Este o bază de date open-source în care datele sunt stocate sub formă de rânduri și coloane, în acea celulă este o intersecție de coloane și rânduri.
Mai jos sunt componentele de bază ale arhitecturii Hadoop:
- Sistem de fișiere distribuite Hadoop (HDFS): Hadoop include un sistem de stocare distribuit, sistemul de fișiere distribuite Hadoop (HDFS). HDFS este arhitectura master-slave care stochează date în cluster. Date distribuite pe mai multe noduri slave de către nodul principal din blocul de formulare. Nodul principal se numește Namenode și nodurile slave se numesc Datanode. HDFS este ușor de extins și stochează o cantitate imensă de date pe Datanodes. HDFS are un factor de replicare configurabil cu valoarea implicită 3 care poate fi modificat.
- MapReduce: MapReduce este o paradigmă de programare, care se procesează în paralel pe un număr imens de seturi de date din rețea. MapReduce se referă la două sarcini diferite: maparea datelor de intrare în care datele împărțite într-un subset de date numite tuples și reduce sarcina ia aceste tupluri de pe hartă ca input și se combină pentru a forma ieșirea originalului.
- Fire: YARN înseamnă încă un alt navigator de resurse care calculează resurse precum gestionarea procesorului și a memoriei, programarea cererilor de resurse.
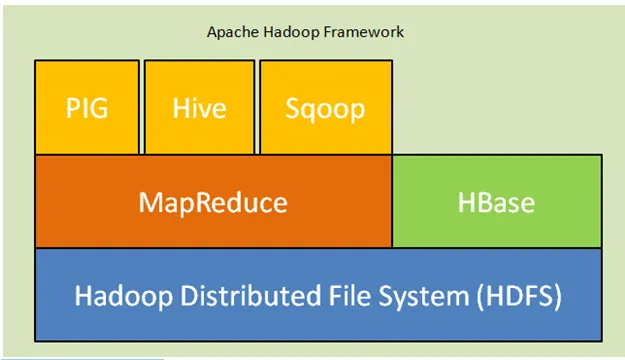
Fig. Cadrul Apache Hadoop
Serverul de regiune servește date pentru operațiunile de citire / scriere. Toate datele HBase sunt stocate în fișierul HDFS. Datanode HDFS stochează datele pe care le administrează serverul de regiune. Namenodul HDFS păstrează informații de metadate pentru toate blocurile de date fizice care cuprind fișierele.
Versiunea este utilizată pentru a urmări modificările celulelor, care păstrează evidența versiunii de conținut. Din aceasta se poate prelua orice versiune de conținut. Fiecare valoare de celulă include atributul „versiune” în ceea ce privește marcă de timp pentru a prelua celula. Fiecare valoare din hartă este un tablou neîntrerupt de octeți. Harta este indexată printr-o cheie de rând, tasta de coloană și o marcă de timp. Arhitectura HBase este extrem de scalabilă, redusă, distribuită, persistentă și hărți multidimensionale.
Comparație față în față între Hadoop și HBase (Infografie)
Mai jos se află diferența de top 7 între Hadoop și HBase
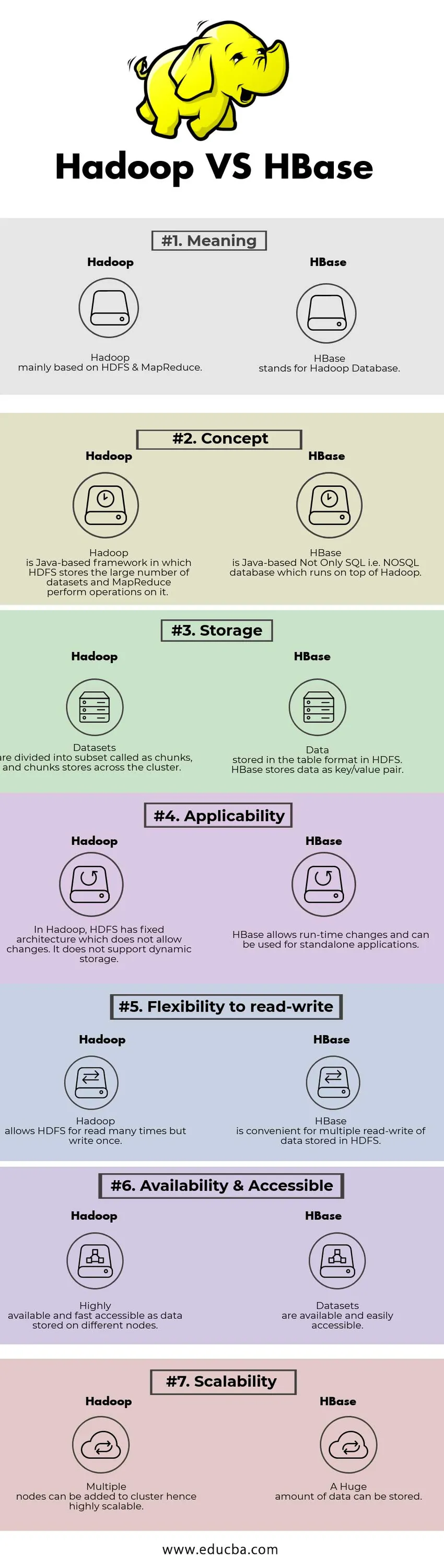
Diferențele cheie între Hadoop și HBase
Diferența dintre Hadoop și HBase sunt explicate în punctele prezentate mai jos:
- Hadoop nu este potrivit pentru procesarea analitică online (OLAP) și HBase face parte din ecosistemul Hadoop care oferă acces în timp real (citire / scriere) la datele din sistemul de fișiere Hadoop.
- Cadrul Hadoop este tolerant la erori prin proiectare și acceptă transferul rapid de date între noduri chiar și în timpul erorilor sistemului. HBase este o bază de date non-relațională și open source Not-Only-SQL care rulează în partea de sus a Hadoop. HBase se încadrează în tipul CP (coerență, disponibilitate și toleranța partițiilor).
- Hadoop este cel mai potrivit pentru efectuarea analizelor de loturi. Cu toate acestea, unul dintre cele mai mari dezavantaje este incapacitatea sa de a efectua analize în timp real, cerința de trend a industriei IT. HBase, pe de altă parte, poate gestiona seturi de date mari și nu este potrivit pentru analizele de lot. În schimb, este folosit pentru a scrie / citi date de la Hadoop în timp real.
- Atât Hadoop, cât și HBase sunt capabile să prelucreze date structurate, semi-structurate, precum și nestructurate. În Hadoop, HDFS nu are un motor de procesare în memorie, încetinind procesul de analiză a datelor; întrucât se folosește simplu MapReduce vechi pentru a o face. Dimpotrivă, HBase se mândrește cu un motor de procesare în memorie care mărește drastic viteza de citire / scriere.
- Hadoop este foarte transparent în realizarea analizei datelor. Pe de altă parte, HBase, fiind o bază de date NoSQL în format tabular, preia valorile prin sortarea lor sub diferite valori cheie.
Tabelul de comparare Hadoop vs HBase
| BAZĂ DE COMPARARE | Hadoop | HBase |
| Sens | Hadoop se bazează în principal pe HDFS și MapReduce. | HBase înseamnă Hadoop Database. |
| Concept | Hadoop este un cadru bazat pe Java în care HDFS stochează numărul mare de seturi de date și MapReduce efectuează operațiuni pe acesta. | HBase este bazat pe Java Nu numai SQL, adică baza de date NoSQL, care se execută în partea de sus a Hadoop. |
| Depozitare | Seturile de date sunt împărțite în subseturi denumite sub formă de bucăți și magazine de bucăți din cluster. | Date stocate în format tabel în HDFS. HBase stochează datele ca pereche cheie / valoare. |
| aplicabilitate | În Hadoop, HDFS are o arhitectură fixă care nu permite modificări. Nu acceptă stocarea dinamică. | HBase permite modificări în timp de rulare și poate fi utilizat pentru aplicații de sine stătătoare. |
| Flexibilitate la citire-scriere | Hadoop permite HDFS pentru citit de multe ori, dar scrie o singură dată. | HBase este convenabil pentru citirea multiplă a datelor stocate în HDFS |
| Disponibilitate și accesibil | Foarte disponibil și accesibil rapid ca date stocate pe diferite noduri. | Seturile de date sunt disponibile și ușor accesibile |
| scalabilitate | Mai multe noduri pot fi adăugate la cluster, deci extrem de scalabile. | O cantitate uriașă de date poate fi stocată. |
Concluzie - Hadoop vs HBase
Arhitectura Hadoop se bazează în principal pe HDFS și MapReduce. HBase este componenta de sprijin din sistemul Hadoop. HBase este capabil să găzduiască tabele uriașe și să ofere acces rapid aleatoriu la datele disponibile, în timp ce HDFS este potrivit pentru stocarea fișierelor mari. Atât Hadoop cât și HBase oferă acces rapid la date, dar cu operații de citire / scriere HBase pot fi efectuate și pentru HDFS citite de multe ori și odată ce se poate efectua scrierea. Acest articol a descris o înțelegere a Hadoop și HBase, caracteristici subliniate pe scurt și comparate cu înțelepciune.
Articol recomandat
- Apache Hadoop vs Apache Spark | Top 10 comparații pe care trebuie să le știi!
- Hadoop vs Hive - Aflați cele mai bune diferențe
- HBase vs Cassandra - Care este mai bun (Infografie)
- Top 12 Comparație dintre Apache Hive și Apache HBase (Infografie)
- Hadoop vs Spark: Care sunt caracteristicile