

Introducere în ANOVA în R
Următorul articol ANOVA din R oferă un schiț pentru compararea valorii medii a diferitelor grupuri. Analiza Varianței (ANOVA) este o tehnică foarte frecventă folosită pentru a compara valoarea medie a diferitelor grupuri. Modelul ANOVA este utilizat pentru testarea ipotezelor, unde se generează o anumită ipoteză sau un parametru pentru o populație și se folosește metoda statistică pentru a determina dacă ipoteza este adevărată sau falsă.
Ipoteza este derivată din asumarea și informațiile disponibile ale anchetatorului despre populație. ANOVA se numește Analiza Varianței și se folosește pentru testarea ipotezelor, unde trebuie măsurate mijloacele unei variabile din mai multe grupuri independente.
De exemplu, într-un laborator pentru a studia sau inventa un nou medicament pentru obezitate, cercetătorii vor compara rezultatul tratamentului experimental și standard. Într-un studiu de obezitate, rezultate valoroase pot fi obținute atunci când rata medie de obezitate a populației poate fi comparată în diferite grupe de vârstă. În acest caz, dorim să observăm rata medie de obezitate între diferite grupe de vârstă, cum ar fi vârsta (5-18 ani), (19, 35) și (36 - 50). Metoda ANOVA este aplicată deoarece există mai mult de două grupuri care sunt independente. Metoda ANOVA este utilizată pentru a compara obezitatea medie a grupurilor independente. Funcția aov () este utilizată și Sintaxa este aov (formula, date = dataframe) În acest articol, vom afla despre modelul ANOVA și vom discuta în continuare modelul ANOVA unidirecțional și bidirecțional, împreună cu exemple.
De ce ANOVA?
- Această tehnică este utilizată pentru a răspunde ipotezei în timp ce analizează mai multe grupuri de date. Există mai multe abordări statistice, cu toate acestea, ANOVA în R se aplică atunci când comparația trebuie făcută pe mai mult de două grupuri independente, ca în exemplul nostru anterior, trei grupe de vârstă diferite.
- Tehnica ANOVA măsoară media grupurilor independente pentru a oferi cercetătorilor rezultatul ipotezei. Pentru a obține rezultate exacte, trebuie luate în considerare mijloacele de probă, mărimea eșantionului și abaterea standard de la fiecare grup în parte.
- Este posibilă observarea medie individuală pentru fiecare dintre cele trei grupuri pentru comparație. Cu toate acestea, această abordare are limitări și s-ar putea dovedi incorecte, deoarece aceste trei comparații nu iau în considerare datele totale și, astfel, pot duce la o eroare de tip 1. R ne oferă funcția de a efectua analiza ANOVA pentru a examina variabilitatea dintre grupurile independente de date. Există cinci etape de realizare a analizei ANOVA. În prima etapă, datele sunt aranjate în format csv și coloana este generată pentru fiecare variabilă. Una dintre coloane ar fi o variabilă dependentă, iar restul este variabila independentă. În a doua etapă, datele sunt citite în studioul R și numite în mod corespunzător. În a treia etapă, un set de date este atașat la variabile individuale și citit de memorie. În cele din urmă, ANOVA în R este definit și analizat. În secțiunile de mai jos am oferit câteva exemple de studiu de caz în care ar trebui utilizate tehnici ANOVA.
- Șase insecticide au fost testate pe 12 câmpuri, iar cercetătorii au numărat numărul de erori care au rămas în fiecare câmp. Acum fermierii trebuie să știe dacă insecticidele fac vreo diferență și, dacă da, care dintre ele le folosesc cel mai bine. Răspundeți la această întrebare folosind funcția aov () pentru a efectua un ANOVA.
- Cincizeci de pacienți au primit unul dintre cele cinci tratamente medicamentoase de reducere a colesterolului (trt). Trei dintre condițiile de tratament au implicat același medicament administrat ca 20 mg o dată pe zi (1 dată) 10 mg de două ori pe zi (de 2 ori) 5 mg de patru ori pe zi (de 4 ori). Cele două condiții rămase (drogul și drogul) au reprezentat droguri concurente. Care tratament medicamentos a produs cea mai mare reducere a colesterolului (răspuns)?
ANOVA One-Way
- Metoda unidirecțională este una dintre bazele tehnicii ANOVA în care se aplică analiza varianței și se compară valoarea medie a mai multor grupuri de populație.
- ANOVA și-a primit numele unic din cauza disponibilității datelor clasificate unidirecțional. Într-o singură variantă ANOVA variabilă dependentă și una sau mai multe variabile independente pot fi disponibile.
- De exemplu, vom efectua tehnica ANOVA pe setul de date privind colesterolul. Setul de date constă din două variabile Trt (care sunt tratamente la 5 niveluri diferite) și variabile de răspuns. Variabilă independentă - grupuri de tratament medicamentos, variabilă dependentă - mijloace de 2 sau mai multe grupuri ANOVA. Din aceste rezultate, puteți confirma că administrarea dozelor de 5 mg de 4 ori pe zi a fost mai bună decât a lua o doză de douăzeci mg o dată pe zi. Drogurile D au efecte mai bune în comparație cu acel medicament E
Drogurile D oferă rezultate mai bune dacă sunt luate în doze de 20 mg în comparație cu medicamentul E
Utilizează setul de date privind colesterolul în pachetul multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Testul ANOVA F pentru tratament (trt) este semnificativ (p <.0001), oferind dovezi că cele cinci tratamente
# nu sunt la fel de eficiente.
rezumat (aov_model)
detach (colesterolul)

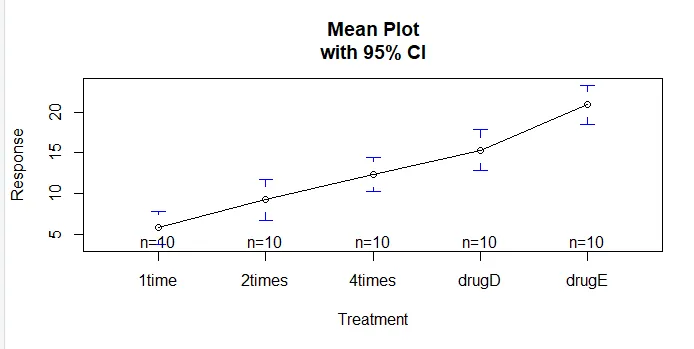
Funcția plotmeans () din pachetul gplots poate fi utilizată pentru a produce un grafic al mijloacelor de grup și a intervalelor de încredere ale acestora. Acest lucru arată clar diferențele de tratamentinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Să examinăm ieșirea de la TukeyHSD () pentru diferențele în perechi între mijloacele de grup
TukeyHSD (aov_model)
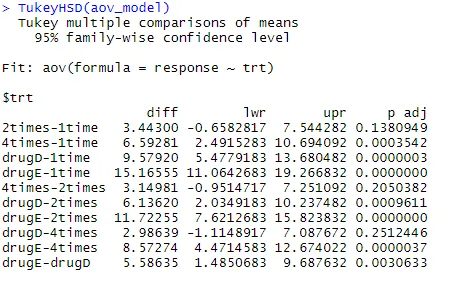
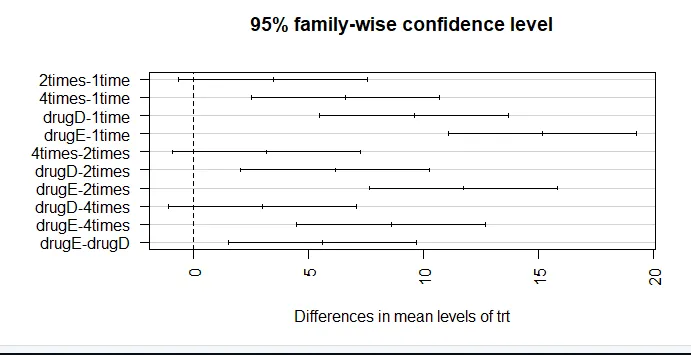
Reducerile medii ale colesterolului de 1 oară și de 2 ori nu sunt semnificativ diferite una de cealaltă (p = 0, 138), în timp ce diferența între o dată și de 4 ori este semnificativ diferită (p <0, 001).
par (mar = c (5, 8, 4, 2)) # creșteți marja din stânga (TukeyHSD (aov_model), las = 2)
Încrederea în rezultate depinde de gradul în care datele dvs. satisfac ipotezele care stau la baza testelor statistice. Într-un ANOVA unidirecțional, se presupune că variabila dependentă este distribuită în mod normal și are o variație egală în fiecare grup. Puteți utiliza un complot QQ pentru a evalua biblioteca de presupunere a normalității (mașină).
Grafic QQ (lm (răspuns ~ trt, date = colesterol), simula = ADEVĂRAT, principal = "QQ Plot", etichete = FALSE)
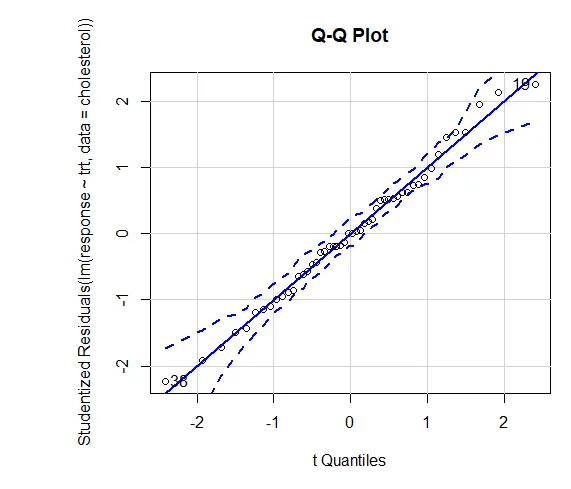
Linie punctată = plic de încredere de 95%, ceea ce sugerează că presupunerea de normalitate a fost îndeplinită destul de bine ANOVA presupune că variațiile sunt egale între grupuri sau probe. Testul Bartlett poate fi utilizat pentru a verifica această presupunere
bartlett.test (răspuns ~ trt, date = colesterol). Testul lui Bartlett indică faptul că variațiile din cele cinci grupuri nu diferă semnificativ (p = 0.97).
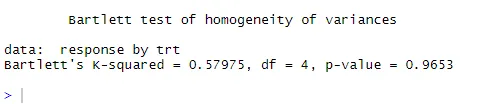
ANOVA este, de asemenea, sensibil la testul outliers pentru outliers folosind funcția outlierTest () din pachetul auto. Este posibil să nu fie nevoie să rulați acest pachet pentru a actualiza biblioteca auto.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
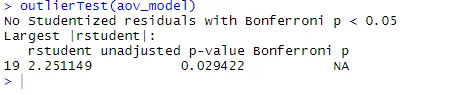
Din ieșire, puteți vedea că nu există nicio indicație de valori superioare în datele privind colesterolul (NA apare atunci când p> 1). Luând complotul QQ, testul lui Bartlett și testul anterior, datele par să se potrivească destul de bine modelului ANOVA.
Anova cu două căi
O altă variabilă este adăugată la testul ANOVA în două direcții. Când există două variabile independente, va trebui să folosim ANOVA în două sensuri, mai degrabă decât o tehnică ANOVA unidirecțională, care a fost utilizată în cazul anterior, unde am avut o variabilă dependentă continuă și mai mult de o variabilă independentă. Pentru a verifica ANOVA în două sensuri, trebuie să fie satisfăcute mai multe ipoteze.
- Disponibilitatea observațiilor independente
- Observațiile ar trebui să fie distribuite în mod normal
- Variatia trebuie sa fie egala in observatii
- Outliers nu ar trebui să fie prezenți
- Erori independente
Pentru a verifica ANOVA în două sensuri, o altă variabilă numită BP este adăugată la setul de date. Variabila indică rata tensiunii arteriale la pacienți. Am dori să verificăm dacă există vreo diferență statistică între BP și doza administrată pacienților.
df <- read.csv („file.csv”)
df
anova_two_way <- aov (răspuns ~ trt + BP, date = df)
rezumat (anova_two_way)
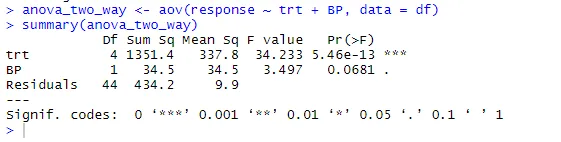
Din rezultat, se poate concluziona că atât trtul și BP sunt statistic diferite de 0. Prin urmare, ipoteza Null poate fi respinsă.
Beneficiile ANOVA în R
Testul ANOVA determină diferența medie între două sau mai multe grupuri independente. Această tehnică este foarte utilă pentru analiza mai multor articole, care este esențială pentru analiza pieței. Folosind testul ANOVA se pot obține informații necesare despre date. De exemplu, în timpul unui sondaj de produse în care sunt colectate mai multe informații, cum ar fi listele de cumpărături, aprecierile clientilor și neplăcerile de la utilizatori. Testul ANOVA ne ajută să comparăm grupurile de populație. Grupul poate fi masculin sau feminin sau diferite grupuri de vârstă. Tehnica ANOVA ajută la distingerea valorilor medii ale diferitelor grupuri ale populației, care sunt într-adevăr diferite.
Concluzie - ANOVA în R
ANOVA este una dintre cele mai utilizate metode pentru testarea ipotezelor. În acest articol, am efectuat un test ANOVA pe setul de date constând din cincizeci de pacienți care au primit tratament medicamentos pentru reducerea colesterolului și am văzut în continuare cum poate fi efectuat ANOVA în două sensuri când este disponibilă o variabilă independentă suplimentară.
Articole recomandate
Acesta este un ghid pentru ANOVA în R. Aici vom discuta despre modelul Anova unidirecțional și bidirecțional, împreună cu exemple și beneficii ale ANOVA. De asemenea, puteți parcurge și alte articole sugerate -
- Regresie vs ANOVA
- Ce este SPSS?
- Cum se interpretează rezultatele folosind testul ANOVA
- Funcții în R