
Ce este regresia liniară în R?
Regresia liniară este algoritmul cel mai popular și utilizat pe scară largă în domeniul statisticilor și al învățării automate. Regresia liniară este o tehnică de modelare pentru a înțelege relația dintre variabilele de intrare și de ieșire. Aici variabilele trebuie să fie numerice. Regresia liniară provine de la faptul că variabila de ieșire este o combinație liniară de variabile de intrare. Ieșirea este de obicei reprezentată de „y”, în timp ce intrarea este reprezentată de „x”.
Regresia liniară în R poate fi clasificată în două moduri
-
Dă un regres liniar
Aceasta este regresia în care variabila de ieșire este o funcție a unei variabile de intrare unice. Reprezentarea regresiei liniare simple:
y = c0 + c1 * x1
-
Regresie liniară multiplă
Aceasta este regresia în care variabila de ieșire este o funcție a unei variabile cu mai multe intrări.
y = c0 + c1 * x1 + c2 * x2
În ambele cazuri de mai sus c0, c1, c2 sunt coeficientul care reprezintă greutăți de regresie.
Regresia liniară în R
R este un instrument statistic foarte puternic. Deci, să vedem cum poate fi executată regresia liniară în R și cum pot fi interpretate valorile sale de ieșire.
Să pregătim un set de date, pentru a efectua și înțelege regresia liniară în profunzime acum.
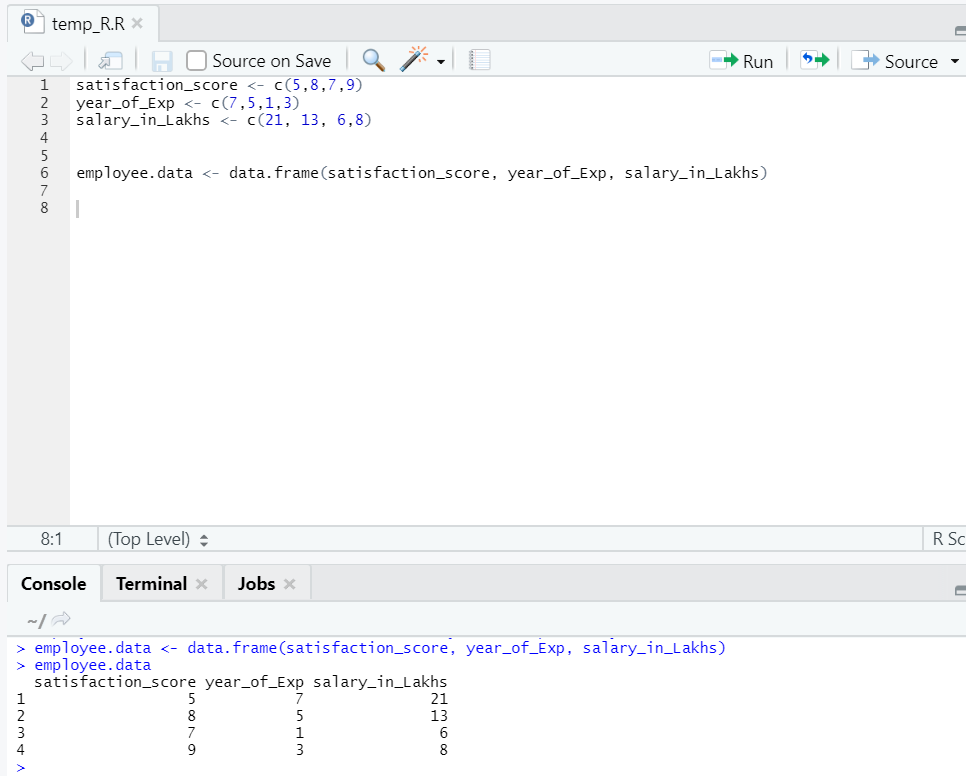
Acum avem un set de date, unde „satisfaction_score” și „year_of_Exp” sunt variabila independentă. „Salariul_in_lakhs” este variabila de ieșire.
Referindu-ne la setul de date de mai sus, problema pe care dorim să o abordăm aici prin regresie liniară este:
Estimarea salariului unui angajat, pe baza anului de experiență și a punctajului de satisfacție din compania sa.
Codul R de regresie liniară:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Rezultatul codului de mai sus va fi:
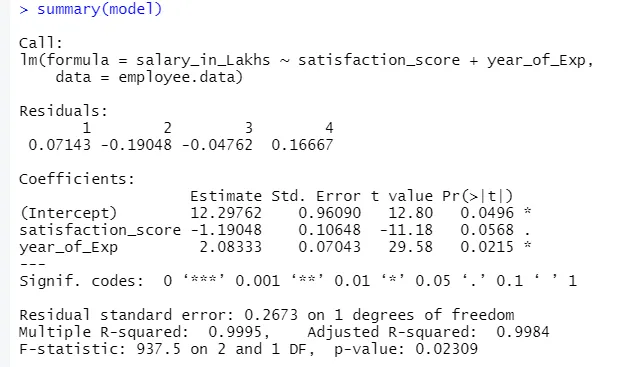
Formula regresiei devine
Y = 12.29-1.19 * satisfacție_scor + 2.08 × 2 * an_de_Exp
În caz, unul are mai multe intrări la model.
Atunci codul R poate fi:
model <- lm (salariu_in_Lakhs ~., data = angajat.data)
Cu toate acestea, dacă cineva dorește să selecteze o variabilă dintr-o variabilă de intrare multiplă, există mai multe tehnici precum „Eliminare înapoi”, „Selecție înainte” etc.
Interpretarea regresiei liniare în R
Mai jos sunt câteva interpretări ale regresiei liniare în r care sunt următoarele:
1.Residuals
Aceasta se referă la diferența dintre răspunsul real și răspunsul prevăzut al modelului. Deci, pentru fiecare punct, va exista un răspuns real și un răspuns prevăzut. Prin urmare, reziduurile vor fi la fel de multe ca observațiile. În cazul nostru avem patru observații, deci patru reziduuri.

2.Coefficients
Mergând mai departe, vom găsi secțiunea de coeficienți, care prezintă interceptul și panta. Dacă cineva dorește să prezică salariul unui angajat pe baza experienței și a scorului de satisfacție, trebuie să elaboreze o formulă model bazată pe pantă și interceptare. Această formulă vă va ajuta în prezicerea salariului. Interceptarea și panta ajută un analist să vină cu cel mai bun model care se potrivește corect informațiilor de date.
Panta: prezintă abruptul liniei.
Intercept: locația în care linia taie axa.
Să înțelegem cum se face formarea formulelor pe baza pantei și a interceptării.
Spuneți că interceptarea este 3 și panta 5.
Deci, formula este y = 3 + 5x . Aceasta înseamnă că dacă x a crescut cu o unitate, y devine crescut cu 5.
a.Coeficient - Estimare
În acest sens, interceptarea indică valoarea medie a variabilei de ieșire, când toată intrarea devine zero. Deci, în cazul nostru, salariul în lakhs va fi de 12.29Lakhs ca medie, având în vedere scorul de satisfacție și experiența este zero. Aici panta reprezintă modificarea variabilei de ieșire cu o modificare a unității în variabila de intrare.
b.Coeficient - Eroare standard
Eroarea standard este estimarea erorii, pe care o putem obține la calcularea diferenței dintre valoarea reală și cea prevăzută a variabilei noastre de răspuns. La rândul său, acest lucru spune despre încrederea pentru relaționarea variabilelor de intrare și ieșire.
c. Coeficient - valoarea t
Această valoare oferă încrederea de a respinge ipoteza nulă. Cu cât valoarea este mai mare de zero, cu atât este mai mare încrederea de a respinge ipoteza nulă și de a stabili relația dintre variabila de ieșire și de intrare. În cazul nostru, valoarea este departe de zero.
d.Coeficient - Pr (> t)
Acest acronim ilustrează practic valoarea p. Cu cât este mai aproape de zero, cu atât mai ușor putem respinge ipoteza nulă. Linia pe care o vedem în cazul nostru, această valoare este aproape de zero, putem spune că există o relație între pachetul salarial, scorul de satisfacție și anul experiențelor.

Eroare standard reziduală
Aceasta descrie eroarea în predicția variabilei de răspuns. Cu cât este mai scăzută, cu atât este mai mare precizia modelului.
Multiple R-pătrat, R-pătrat ajustat
R-squared este o măsură statistică foarte importantă pentru a înțelege cât de aproape s-au încadrat datele în model. De aici, în cazul nostru, cât de bine reprezintă modelul nostru de regresie liniară.
Valoarea pătrată R se întinde întotdeauna între 0 și 1. Formula este:

Cu cât valoarea este mai aproape de 1, cu atât modelul descrie mai mult seturile de date și variația sa.
Cu toate acestea, când intră în imagine mai multe variabile de intrare, este preferată valoarea pătrată R ajustată.
F-statistic
Este o măsură puternică pentru a determina relația dintre variabila de intrare și răspuns. Cu cât valoarea este mai mare decât 1, cu atât este mai mare încrederea în relația dintre variabila de intrare și ieșire.
În cazul nostru, „937.5”, care este relativ mai mare, având în vedere dimensiunea datelor. Prin urmare, respingerea ipotezei nule devine mai ușoară.
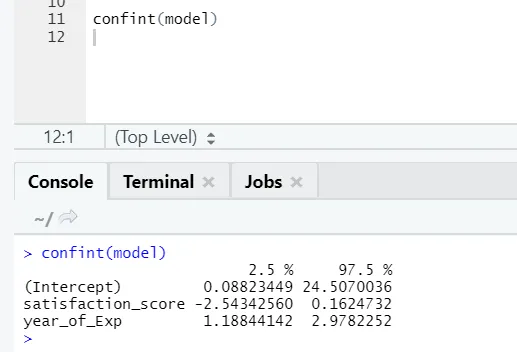
Dacă cineva dorește să vadă intervalul de încredere pentru coeficienții modelului, iată modul de a face acest lucru: -
Vizualizarea regresiei
Cod R:
complot (salariu_in_Lakhs ~ satisfacție_score + an_of_Exp, date = angajat.data)
abline (model)
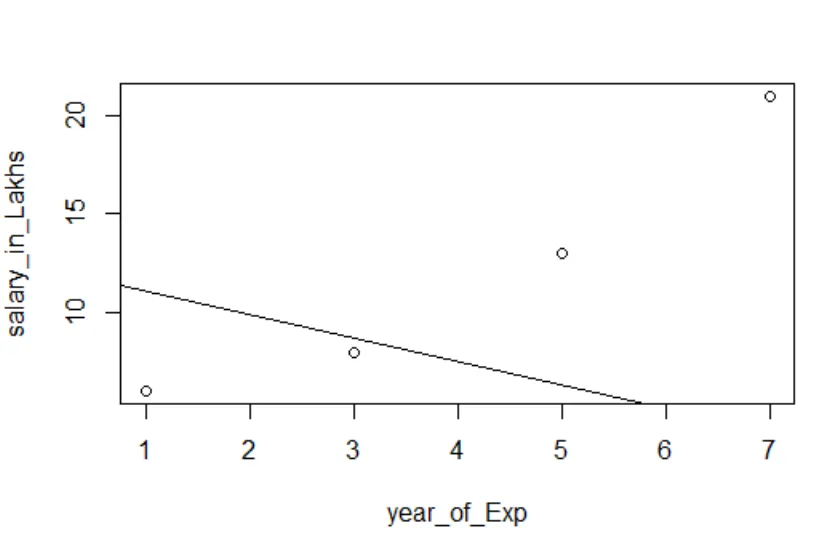
Este întotdeauna mai bine să aduni din ce în ce mai multe puncte, înainte de a se potrivi cu un model.
Concluzie - Regresie liniară în R
Regresia liniară este un model simplu, ușor de montat, ușor de înțeles, dar foarte puternic. Am văzut cum poate fi efectuată regresia liniară pe R. Am încercat, de asemenea, să interpretăm rezultatele, care vă pot ajuta în optimizarea modelului. Odată ce se obține confortabil cu o regresie liniară simplă, ar trebui să încercați regresia liniară multiplă. Alături de aceasta, întrucât regresia liniară este sensibilă la valori superioare, trebuie să privim înainte de a sări direct în regresia liniară.
Articole recomandate
Acesta este un ghid pentru regresia liniară în R. Aici am discutat despre ce este regresia liniară în R? clasificarea, vizualizarea și interpretarea lui R. Puteți parcurge și alte articole propuse pentru a afla mai multe -
- Modelarea predictivă
- Regresie logistică în R
- Arborele de decizii în R
- Întrebări de interviu R
- Cele mai importante diferențe de regresie față de clasificare
- Ghid pentru arborele decizional în învățarea mașinii
- Regresia liniară vs regresia logistică | Diferențe de top