
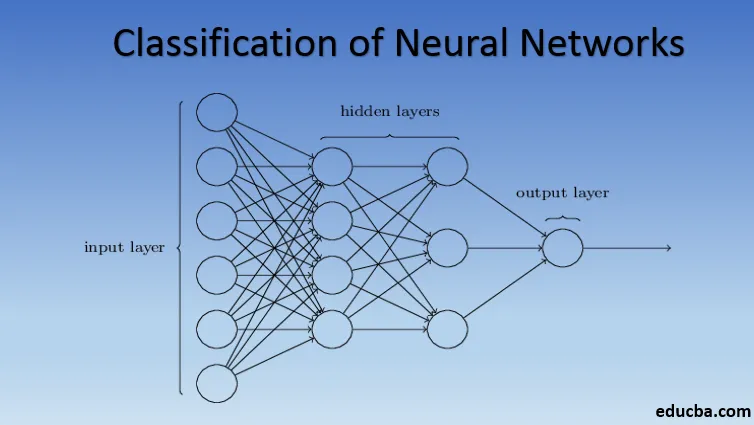
Introducere în clasificarea rețelei neuronale
Rețelele neuronale sunt cel mai eficient mod (da, ați citit-o corect) de a rezolva problemele din lumea reală în Inteligența artificială. În prezent, este, de asemenea, una dintre domeniile mult cercetate pe larg în domeniul informaticii că ar fi fost dezvoltată o nouă formă de rețea neuronală în timp ce citiți acest articol. Există sute de rețele neuronale pentru a rezolva probleme specifice domeniilor diferite. Aici vă vom conduce prin diferite tipuri de rețele neuronale de bază, în ordinea creșterii complexității.
Diferite tipuri de bază în clasificarea rețelelor neuronale
1. Rețele neuronale superficiale (filtrare colaborativă)
Rețelele neuronale sunt formate din grupuri de Perceptron pentru a simula structura neurală a creierului uman. Rețelele neuronale superficiale au un singur strat ascuns de perceptron. Unul dintre exemple obișnuite de rețele neuronale superficiale este Filtrarea colaborativă. Stratul ascuns al perceptrului ar fi instruit să reprezinte asemănările dintre entități pentru a genera recomandări. Sistemul de recomandări în Netflix, Amazon, YouTube, etc. utilizează o versiune de filtrare colaborativă pentru a recomanda produsele lor în funcție de interesul utilizatorului.
2. Perceptron multistrat (rețele neuronale profunde)
Rețelele neuronale cu mai mult de un strat ascuns se numesc Rețele neuronale profunde. Alertă Spoiler! Toate rețelele neuronale următoare sunt o formă de rețea neuronală profundă modificată / îmbunătățită pentru a rezolva problemele specifice domeniului. În general, ele ne ajută să atingem universalitatea. Având în vedere un număr suficient de straturi ascunse ale neuronului, o rețea neuronală profundă poate aproxima, adică rezolvă orice problemă din lumea reală complexă.
Teorema aproximării universale este nucleul rețelelor neuronale profunde pentru a antrena și a se potrivi cu orice model. Fiecare versiune a rețelei neuronale profunde este dezvoltată printr-un strat complet conectat de produs rezumat maxim de înmulțire a matricei care este optimizat prin algoritmi de backpropagare. Vom continua să învățăm îmbunătățirile care rezultă în diferite forme de rețele neuronale profunde.
3. Rețea neuronală convoluțională (CNN)
CNN-urile sunt cea mai matură formă a rețelelor neuronale profunde pentru a produce cele mai precise, adică mai bune decât rezultatele umane în viziunea computerului. CNN-urile sunt formate din straturi de revoluții create prin scanarea fiecărui pixel de imagini dintr-un set de date. Pe măsură ce datele sunt aproximate strat după strat, CNN începe să recunoască tiparele și, prin urmare, să recunoască obiectele din imagini. Aceste obiecte sunt utilizate pe scară largă în diferite aplicații pentru identificare, clasificare etc. Practici recente precum învățarea transferului în CNN-uri au dus la îmbunătățiri semnificative ale inexactității modelelor. Google Translator și Google Lens sunt cele mai cunoscute exemple de artă ale CNN.
Aplicarea CNN-urilor este exponențială, deoarece sunt chiar utilizate în rezolvarea problemelor care nu sunt în primul rând legate de viziunea computerului. O explicație foarte simplă, dar intuitivă a CNN-urilor, poate fi găsită aici.
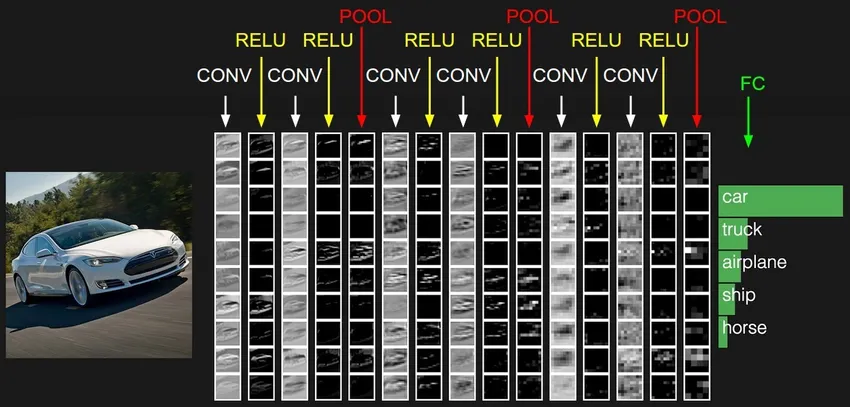
4. Rețea neuronală recurentă (RNN)
RNN-urile sunt cea mai recentă formă de rețele neuronale profunde pentru rezolvarea problemelor în NLP. Mai simplu spus, RNN-urile alimentează câștigarea câtorva straturi ascunse înapoi la stratul de intrare pentru a agrega și duce mai departe aproximarea la următoarea iterație (epocă) a setului de date de intrare. De asemenea, ajută modelul să se auto-învețe și să corecteze mai rapid previziunile. Astfel de modele sunt de mare ajutor pentru a înțelege semantica textului în operațiunile NLP. Există diferite variante de RNN-uri precum LSTM (Long Short Term Memory), Gated Recurrent Unit (GRU), etc. În diagrama de mai jos, activarea de la h1 și h2 este alimentată cu intrarea x2, respectiv x3.
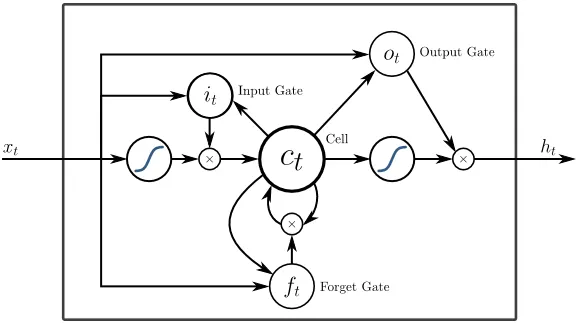
5. Memorie pe termen scurt (LSTM)
LSTM-urile sunt concepute special pentru a rezolva problema gradienților care dispar cu RNN. Gradientele dispărute se întâmplă cu rețele neuronale mari, unde gradienții funcțiilor de pierdere tind să se apropie de zero, făcând o pauză a rețelelor neuronale pentru a învăța. LSTM rezolvă această problemă prin prevenirea funcțiilor de activare în componentele sale recurente și prin faptul că valorile stocate nu au fost mutate. Această mică schimbare a adus îmbunătățiri majore în modelul final, ceea ce a determinat gigantii tehnologici să adapteze LSTM în soluțiile lor. Până la „cea mai simplă explicație de sine” a LSTM,
6. Rețele bazate pe atenție
Modelele de atenție preiau lent, chiar și noile RNN-uri în practică. Modelele de atenție sunt construite concentrându-se pe o parte dintr-un subset de informații pe care le oferă, eliminând astfel cantitatea copleșitoare de informații de fundal care nu sunt necesare pentru sarcina la îndemână. Modelele de atenție sunt construite cu o combinație de atenție moale și dură și montare prin atenția moale de propagare a spatelui. Modele de atenție multiplă stivuite ierarhic se numesc Transformator. Acești transformatori sunt mai eficienți pentru a rula stivele în paralel, astfel încât să obțină rezultate de ultimă generație cu date și timp relativ reduse pentru instruirea modelului. O distribuție a atenției devine foarte puternică atunci când este utilizată cu CNN / RNN și poate produce descrierea textului pentru o imagine după cum urmează.

Giganții tehnici precum Google, Facebook, etc., adaptează rapid modelele de atenție pentru construirea soluțiilor lor.
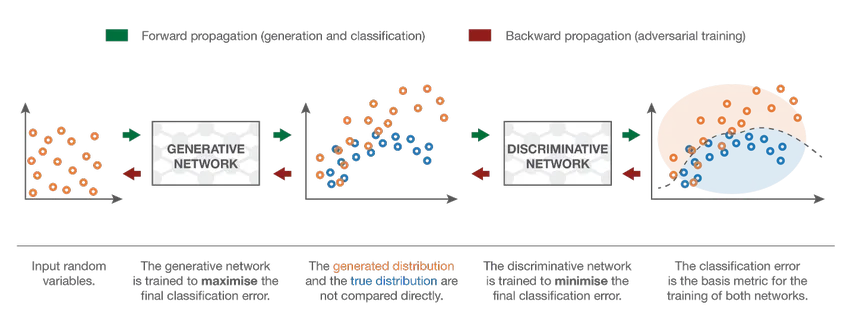
7. Rețea generațională adversă (GAN)
Deși modelele de învățare profundă oferă rezultate de ultimă generație, ele pot fi păcălite de omologii umani mult mai inteligenți, adăugând zgomot la datele din lumea reală. GAN-urile sunt cea mai recentă dezvoltare în învățarea profundă pentru abordarea unor astfel de scenarii. GAN-urile folosesc învățare nesupravegheată unde rețelele neuronale profunde antrenate cu datele generate de un model AI împreună cu setul de date efectiv pentru a îmbunătăți exactitatea și eficiența modelului. Aceste date contradictorii sunt utilizate mai ales pentru a păcăli modelul discriminatoriu pentru a construi un model optim. Modelul rezultat tinde să fie o aproximare mai bună decât poate depăși un astfel de zgomot. Interesul cercetării pentru GAN-uri a dus la implementări mai sofisticate precum GAN condiționat (CGAN), GAN Piramidă Laplaciană (LAPGAN), GAN Super Rezoluție (SRGAN) etc.
Concluzie - Clasificarea rețelei neuronale
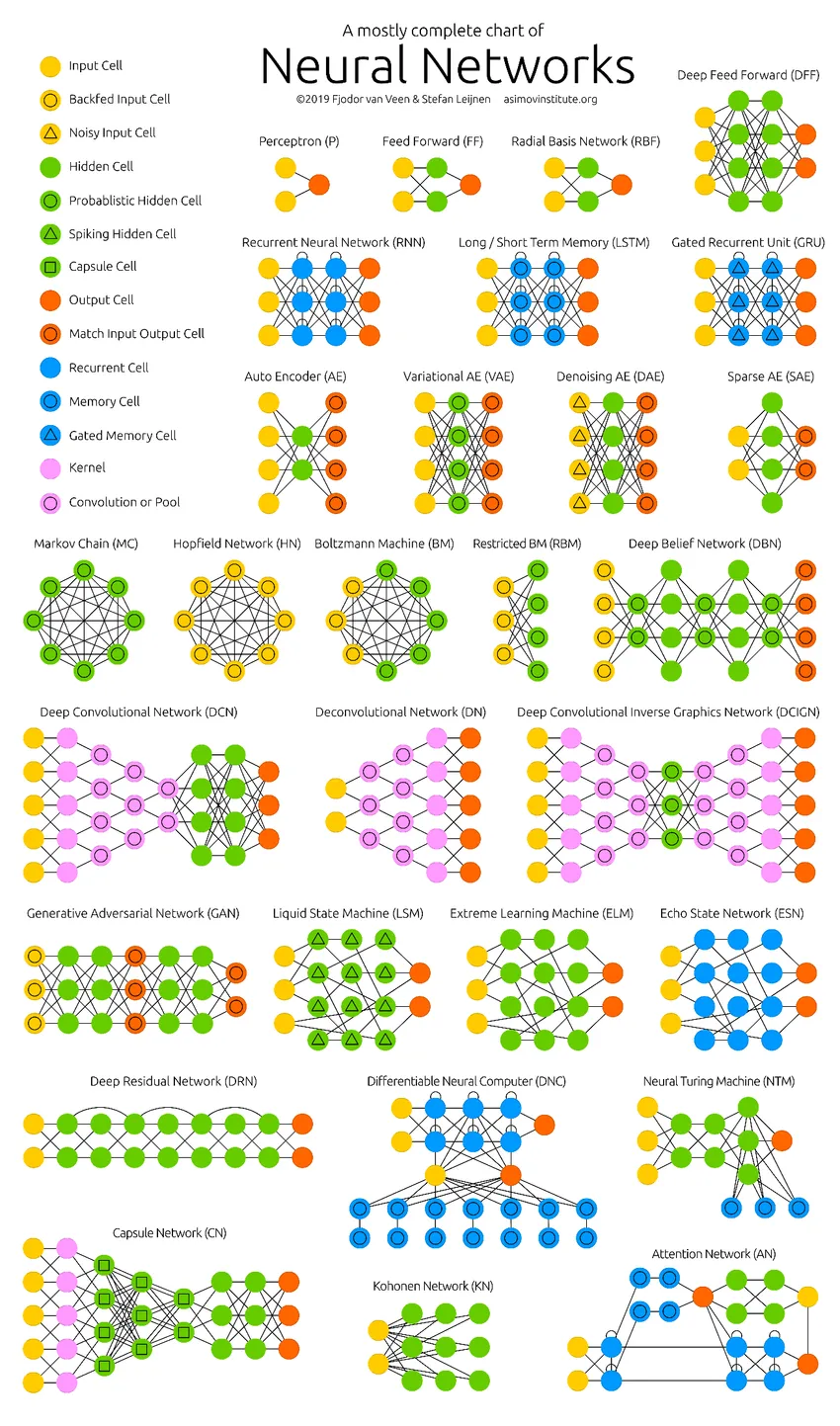
Rețelele neuronale profunde au împins limitele calculatoarelor. Ele nu se limitează doar la clasificare (CNN, RNN) sau predicții (Filtrare colaborativă), ci chiar generarea de date (GAN). Aceste date pot varia de la frumoasa formă de artă la falsele controversate adânci, dar depășesc oamenii cu o sarcină în fiecare zi. Prin urmare, ar trebui să luăm în considerare, de asemenea, etica și impactul AI în timp ce lucrăm din greu pentru a construi un model eficient de rețea neuronală. Timp pentru o infografie îngrijită despre rețelele neuronale.
Articole recomandate
Acesta este un ghid pentru clasificarea rețelei neuronale. Aici am discutat despre diferitele tipuri de rețele neuronale de bază. De asemenea, puteți parcurge articolele noastre date pentru a afla mai multe-
- Ce este rețelele neuronale?
- Algoritmi de rețea neuronală
- Instrumente de scanare în rețea
- Rețele neuronale recurente (RNN)
- Top 6 comparații între CNN și RNN