

Diferențe între Sqoop și Flume
Sqoop este un produs din software-ul Apache. Sqoop extrage informații utile din Hadoop și apoi trece în depozitele de date exterioare. Cu ajutorul Sqoop, putem importa date dintr-un RDBMS sau mainframe în HDFS. Flume este și din software-ul Apache. Colectează și mută datele recursive care sunt generate. Flume Apache nu este restricționat doar la agregarea datelor de jurnal, dar sursele de date sunt personalizabile și astfel Flume poate fi utilizat pentru a transporta cantități masive de date. Cea mai bună modalitate de colectare, agregare și mișcare a unor cantități mari de date între sistemul de fișiere distribuite Hadoop și RDBMS este prin utilizarea unor instrumente precum Sqoop sau Flume.
Să discutăm aceste două instrumente utilizate în mod obișnuit în scopul menționat mai sus.
Ce este Sqoop
Pentru a utiliza Sqoop, un utilizator trebuie să specifice instrumentul pe care utilizatorul dorește să îl utilizeze și argumentele care controlează instrumentul particular. De asemenea, puteți exporta apoi datele înapoi într-un RDBMS folosind Sqoop. Funcționalitatea de export a Sqoop este utilizată pentru a extrage informații utile din Hadoop și a le exporta în depozitele de date structurate din exterior. Funcționează cu diferite baze de date precum Teradata, MySQL, Oracle, HSQLDB.
- Arhitectura Sqoop: -
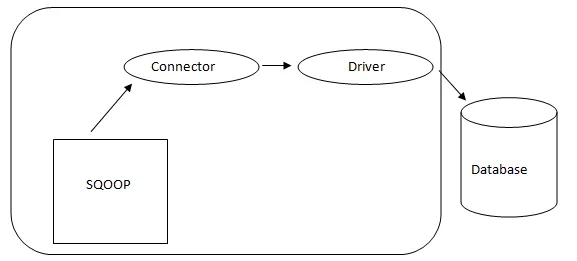
Arhitectura Sqoop
Conectorul dintr-un Sqoop este un plugin pentru o anumită sursă a bazei de date, deci este fundamental faptul că este o componentă a unui set Sqoop. În ciuda faptului că driverele sunt piese specifice bazei de date și distribuite de diverși furnizori de baze de date, Sqoop în sine vine la pachet cu diferite tipuri de conectori utilizați pentru baza de date prevalentă și sistemul de depozitare a informațiilor. Astfel, Sqoop expediază și o varietate mixtă de conectori. Sqoop oferă o componentă conectabilă pentru o rețea ideală și un sistem extern. API-ul Sqoop oferă o structură utilă pentru asamblarea de noi conectori și, prin urmare, orice conectori ai bazei de date pot fi încadrați în instalarea Sqoop pentru a oferi conectivitate diferitelor sisteme de date.
Ce este Flume
Fluxul Apache nu este restricționat doar la agregarea datelor de jurnal, dar sursele de date sunt personalizabile și astfel Flume poate fi utilizat pentru a transporta cantități masive de date, inclusiv, fără a se limita la mesaje de e-mail, date generate de social-media, date despre traficul de rețea și aproape orice sursă de date posibilă.
Arhitectura Flume: - Arhitectura Flume se bazează pe concepte cu mai multe nuclee:
- Flume Event - este reprezentat ca unitatea de date care curge, care are o încărcare utilă de octeți și un set de șiruri cu anteturi de șir opționale. Flume consideră un eveniment doar un blob generic de octeți.
- Flume Agent - Este un proces JVM care găzduiește componente precum canale, chiuvete și surse. Are potențialul de a primi, stoca și transmite evenimentele de la o sursă externă la nivelul următor.
- Flume Flow - este momentul în care evenimentul este generat.
- Flume Client - se referă la interfața în care clientul operează la punctul de origine al evenimentului și îl livrează agentului Flume.
- Sursa- O sursă este cea care consumă evenimente având un format specific și o livrează printr-un mecanism specific.
- Channel- Este un magazin pasiv unde se desfășoară evenimente până când chiuveta îl scoate pentru transportul suplimentar.
- Sink - Înlătură evenimentul dintr-un canal și îl pune într-un depozit extern precum HDFS. În prezent acceptă crearea de fișiere text și secvență și acceptă compresia în ambele tipuri de fișiere.
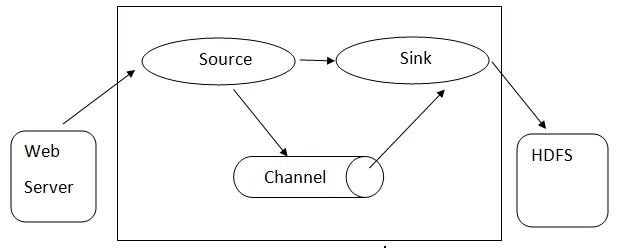
Arhitectura Flume
Comparație față în față între Sqoop și Flume (Infografie)
Mai jos se află prima comparație între Sqoop și Flume

Diferențele cheie între Sqoop și Flume
Știm acum că există multe diferențe între Sqoop și Flume, aici sunt cele mai importante diferențe între ele date mai jos -
1. Sqoop este proiectat pentru a face schimb de informații în masă între Hadoop și baza de date relațională.
Întrucât, Flume este utilizat pentru a colecta date din diferite surse care generează date referitoare la un caz de utilizare particular și apoi transferă această cantitate mare de date din resurse distribuite într-un singur depozit centralizat.
2. Sqoop include și un set de comenzi care vă permit să inspectați baza de date cu care lucrați. Astfel, putem considera Sqoop ca o colecție de instrumente conexe.
În timp ce colectează data Flume scalează datele orizontal și mai mulți agenți Flume pot fi puse în acțiune pentru colectarea datei și agregarea lor. După aceea, jurnalele de date sunt mutate într-un depozit de date centralizat, adică sistemul de fișiere distribuite Hadoop (HDFS).
3. Factorul cheie pentru utilizarea Flume este că datele trebuie să fie generate într-un mod continuu și în flux. În mod similar, Sqoop este cel mai potrivit în situațiile în care datele dvs. locuiesc în sisteme de baze de date precum MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (tabel comparativ)
| Baza pentru comparație | SQOOP | CANAL |
|
Natura de bază | Sqoop funcționează bine cu orice RDBMS care are JDBC (Java Database Connectivity) precum Oracle, MySQL, Teradata etc. | Flume funcționează bine pentru fluxul de surse de date care generează continuu, cum ar fi jurnalele, JMS, directorul, rapoartele de avarie etc. |
| Flux de date | Sqoop utilizat special pentru transferul paralel de date. Din acest motiv, ieșirea ar putea fi în mai multe fișiere | Flume este utilizat pentru colectarea și agregarea datelor, datorită naturii sale distribuite. |
| Evenimente conduse | Sqoop nu este condus de evenimente. | Flume este complet bazat pe evenimente. |
| Arhitectură | Sqoop urmează arhitectura bazată pe conector, ceea ce înseamnă conectori, știe să se conecteze la o altă sursă de date. | Flume urmează arhitectura bazată pe agent, unde codul scris în ea este cunoscut ca agent care este responsabil pentru preluarea datelor. |
| Unde să folosești | Utilizat în principal pentru copierea rapidă a datelor și apoi utilizarea acestora pentru generarea de rezultate analitice. | Folosit în general pentru a trage date atunci când companiile doresc să analizeze tiparele, cauzele principale sau analiza sentimentelor folosind jurnalele și social media. |
| Performanţă | Reduce stocarea excesivă și prelucrarea încărcărilor prin transferul lor în alte sisteme și are performanțe rapide. | Flume este rezistent la erori, robust și are un mecanism de fiabilitate durabil pentru reîncărcare și recuperare. |
| Istoricul lansărilor | Prima versiune a Apache Sqoop a fost lansată în martie 2012. Actuala versiune stabilă este 1.4.7 | Prima versiune stabilă 1.2.0 a Apache Flume a fost lansată în iunie 2012. Actuala versiune stabilă este Apache Flume Versiunea 1.8.0. |
Concluzie - Sqoop vs Flume
După cum ați aflat mai sus Sqoop și Flume, sunt în principal două instrumente de ingerare a datelor utilizate este lumea Big Data. Dacă trebuie să ingeți date de jurnal textual în Hadoop / HDFS, atunci Flume este alegerea potrivită pentru a face asta. Dacă datele dvs. nu sunt generate în mod regulat, Flume va funcționa în continuare, dar va fi o supraîncărcare pentru situația respectivă. În mod similar, Sqoop nu este cea mai potrivită pentru gestionarea datelor bazate pe evenimente.
Articole recomandate
Acesta a fost un ghid pentru diferențele dintre Sqoop și Flume, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparație și concluzii. acest articol constă din toate diferențele utile între Sqoop și Flume. De asemenea, puteți consulta următoarele articole pentru a afla mai multe
- Hadoop vs Teradata - Diferite utilizări de învățat
- 5 Cea mai importantă diferență între Apache Kafka și Flume
- Big Data vs Apache Hadoop - Top 4 comparație pe care trebuie să o înveți
- 5 Cea mai importantă diferență între Apache Kafka și Flume
- Importarea textului important și procesarea limbajului natural - primele 5 comparații