

Introducere în Comenzile Spark
Apache Spark este un cadru construit pe partea de sus a Hadoop pentru calcule rapide. Extinde conceptul MapReduce în scenariul bazat pe cluster pentru a rula eficient o sarcină. Spark Command este scris în Scala.
Hadoop poate fi utilizat de Spark în următoarele moduri (vezi mai jos):
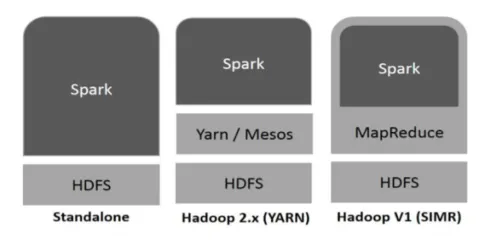
Fig 1
https://www.tutorialspoint.com/
- Standalone: Spark dislocat direct în partea de sus a Hadoop. Locurile de muncă Spark se desfășoară paralel pe Hadoop și Spark.
- Hadoop YARN: Spark rulează pe Fire fără a fi nevoie de nicio preinstalare.
- Spark in MapReduce (SIMR): Scânteia în MapReduce este folosită pentru a lansa lucrul de scânteie, pe lângă implementarea de sine stătătoare. Cu SIMR, se poate porni Spark și își poate folosi shell-ul fără niciun acces administrativ.
Componentele Spark:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- GraphX
Seturi de date distribuite rezistente (RDD) este considerată structura de date fundamentală a comenzilor Spark. RDD este imuabil și numai în natură de citire. Tot felul de calcule din comenzile de scânteie se realizează prin transformări și acțiuni pe RDD.
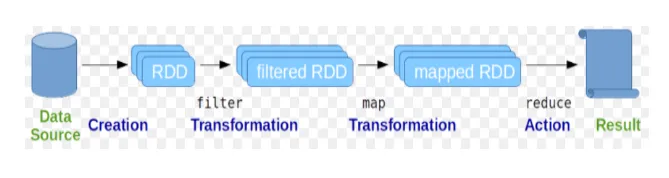
Fig. 2
Imagine Google
Spark shell oferă un mediu pentru utilizatori să interacționeze cu funcționalitățile sale. Comenzile Spark au o mulțime de comenzi diferite care pot fi utilizate pentru a prelucra date pe shell-ul interactiv.
Comenzi de bază pentru scânteie
Haideți să aruncăm o privire la unele dintre comenzile de bază Spark care sunt prezentate mai jos: -
-
Pentru a porni shell-ul Spark:

Fig 3
-
Citiți fișierul din sistemul local:

Aici „sc” este contextul scântei. Având în vedere „data.txt” se află în directorul principal, se citește astfel, altfel trebuie să specificați calea completă.
-
Creați RDD prin paralelizare

NewData este acum RDD.
-
Numărați articolele în RDD

-
Colectarea
Această funcție returnează întregul conținut RDD la programul de driver. Acest lucru este util în depanarea la diferite etape ale programului de scriere.
-
Citiți primele 3 articole din RDD

-
Salvați datele de ieșire / procesate în fișierul text

Aici folderul „ieșire” este calea curentă.
Comenzi intermediare de scânteie
1. Filtrează pe RDD
Să creăm un nou RDD pentru articolele care conțin „da”.

Filtrul de transformare trebuie să apeleze la RDD-ul existent pentru a filtra cuvântul „da”, care va crea un nou RDD cu noua listă de elemente.
2. Funcționarea în lanț

Aici transformarea filtrului și acțiunea de numărare au acționat împreună. Aceasta se numește operație în lanț.
3. Citiți primul articol din RDD

4. Numărați partițiile RDD
După cum știm, RDD este format din mai multe partiții, apare nevoia de a număra nr. de partiții. Întrucât ajută la reglarea și depanarea în timp ce lucrați cu comenzile Spark.

În mod implicit, minimul nr. partiția pf este 2.
5. alătură-te
Această funcție se alătură a două tabele (elementul tabelului este în mod perechi) bazat pe cheia comună. În RDD pereche, primul element este cheia, iar al doilea element este valoarea.
6. Cache un fișier
Cache-ul este o tehnică de optimizare. În cache RDD înseamnă, RDD va rămâne în memorie și toate calculele viitoare se vor face pe acele RDD în memorie. Economisește timpul de citire a discului și îmbunătățește performanțele. Pe scurt, reduce timpul de acces la date.

Cu toate acestea, datele nu vor fi memorate în cache dacă executați funcția de mai sus. Acest lucru poate fi dovedit accesând pagina web:
http: // localhost: 4040 / depozitare
RDD va fi memorat în cache, după ce acțiunea este finalizată. De exemplu:

O altă funcție care funcționează similar cu cache () este persist (). Persist oferă utilizatorilor flexibilitatea de a da argumentul, ceea ce poate ajuta datele să fie memorate în cache, pe disc sau în memorie off-heap. Persistați fără niciun argument funcționează la fel ca cache ().
Comenzi avansate de scânteie
Să aruncăm o privire la unele dintre comenzile avansate Spark care sunt prezentate mai jos: -
-
Difuzați o variabilă
Variabila Broadcast ajută programatorul să citească singura variabilă memorată în cache pe fiecare mașină din cluster, mai degrabă decât să trimită o copie a acelei variabile cu sarcini. Acest lucru ajută la reducerea costurilor de comunicare.
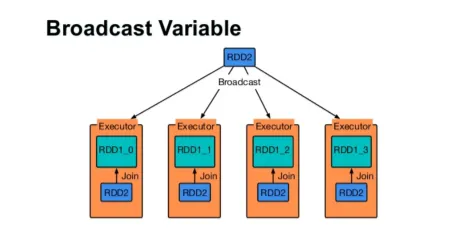
Fig 4
imagine Google
Pe scurt, există trei caracteristici principale ale variabilei difuzate:
- Imuabil
- Se potrivesc în memorie
- Distribuit pe cluster
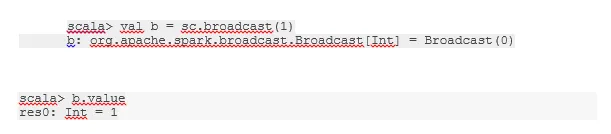
-
Acumulatori
Acumulatorii sunt variabilele care se adaugă la operațiunile asociate. Există multe utilizări pentru acumulatori precum contoare, sume etc.

Numele acumulatorului din cod ar putea fi văzut și în Spark UI.
-
Hartă
Funcția de hartă ajută la iterarea pe fiecare linie din RDD. Funcția utilizată pe hartă este aplicată fiecărui element din RDD.
De exemplu, în RDD (1, 2, 3, 4, 6) dacă aplicăm „rdd.map (x => x + 2)” vom obține rezultatul ca (3, 4, 5, 6, 8).
-
Flatmap
Flatmap funcționează similar cu harta, dar harta returnează un singur element, în timp ce flatmap poate returna lista de elemente. Prin urmare, împărțirea propozițiilor în cuvinte va avea nevoie de o foaie plană.
-
Coalesce
Această funcție ajută la evitarea amestecării datelor. Acest lucru este aplicat în partiția existentă, astfel încât să fie reduse mai puține date. În acest fel, putem restricționa utilizarea nodurilor din cluster.
Sfaturi și trucuri pentru a utiliza comenzile scânteie
Mai jos sunt diferite sfaturi și trucuri ale comenzilor Spark: -
- Începătorii Spark pot folosi Spark-shell. Deoarece comenzile Spark sunt construite pe Scala, cu siguranță utilizarea scala scark shell este excelentă. Cu toate acestea, coajă de scânteie python este de asemenea disponibilă, astfel încât chiar și ceva care poate fi folosit, care sunt bine versați cu python.
- Spark shell are o mulțime de opțiuni pentru a gestiona resursele clusterului. Sub Comandă vă poate ajuta:

- În Spark, lucrul cu seturi de date lungi este un lucru obișnuit. Dar lucrurile merg prost atunci când sunt luate contribuții proaste. Este întotdeauna o idee bună să renunțați la rânduri proaste folosind funcția de filtrare a Spark. Un set bun de contribuții va fi un lucru bun.
- Spark alege o partiție bună numai pentru datele dvs. Dar este întotdeauna o practică bună să fii cu ochii pe partiții înainte de a începe munca. Încercarea diferitelor partiții vă va ajuta în paralelismul activității.
Concluzie - Comenzi Scânteie:
Comanda Spark este un motor de date mari și revoluționar, versatil, care poate funcționa pentru procesarea loturilor, procesarea în timp real, stocarea în cache a datelor etc. aplicații rapide.
Articole recomandate
Acesta a fost un ghid pentru comenzile Spark. Aici am discutat despre comenzile Spark de bază și avansate și unele comenzi Spark imediate. De asemenea, puteți consulta articolul următor pentru a afla mai multe -
- Comenzi Adobe Photoshop
- Comenzi VBA importante
- Comenzile Tableau
- Cheat sheet SQL (comenzi, sfaturi gratuite și trucuri)
- Tipuri de uniri în Spark SQL (Exemple)
- Componente scânteie | Prezentare generală și Top 6 componente