

Ce este algoritmul Naive Bayes?
Algoritmul Naive Bayes este o tehnică care ajută la construirea clasificatoarelor. Clasificatorii sunt modelele care clasifică instanțele problemă și le dau etichete de clasă care sunt reprezentate ca vectori de predictori sau valori de caracteristici. Se bazează pe teorema lui Bayes. Se numește Bayes naiv, deoarece presupune că valoarea unei caracteristici este independentă de cealaltă caracteristică, adică schimbarea valorii unei caracteristici nu ar afecta valoarea celeilalte caracteristici. Este, de asemenea, numit Bayes idiot datorită aceluiași motiv. Acest algoritm funcționează eficient pentru seturi de date mari, de aceea este cel mai potrivit pentru predicții în timp real.
Ajută la calcularea probabilității posterioare P (c | x) folosind probabilitatea anterioară a clasei P (c), probabilitatea anterioară a predictorului P (x) și probabilitatea de predicție a clasei date, de asemenea, numită probabilitate P (x | c ).
Formula sau ecuația pentru calcularea probabilității posterioare este:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Cum funcționează algoritmul Naive Bayes?
Să înțelegem funcționarea algoritmului Naive Bayes folosind un exemplu. Ne asumăm un set de date despre instruire despre vremea și variabila țintă „Du-te la cumpărături”. Acum vom clasifica dacă o fată va merge la cumpărături în funcție de condițiile meteorologice.
Setul de date dat este:
| Vreme | A merge la cumparaturi |
| Însorit | Nu |
| Ploios | da |
| Acoperit de nori | da |
| Însorit | da |
| Acoperit de nori | da |
| Ploios | Nu |
| Însorit | da |
| Însorit | da |
| Ploios | Nu |
| Ploios | da |
| Acoperit de nori | da |
| Ploios | Nu |
| Acoperit de nori | da |
| Însorit | Nu |
Următorii pași ar fi efectuate:
Pasul 1: Faceți tabele de frecvență folosind seturi de date.
| Vreme | da | Nu |
| Însorit | 3 | 2 |
| Acoperit de nori | 4 | 0 |
| Ploios | 2 | 3 |
| Total | 9 | 5 |
Pasul 2: Faceți un tabel de probabilități calculând probabilitățile fiecărei condiții meteo și mergeți la cumpărături.
| Vreme | da | Nu | Probabilitate |
| Însorit | 3 | 2 | 5/14 = 0, 36 |
| Acoperit de nori | 4 | 0 | 4/14 = 0, 29 |
| Ploios | 2 | 3 | 5/14 = 0, 36 |
| Total | 9 | 5 | |
| Probabilitate | 9/14 = 0, 64 | 5/14 = 0, 36 |
Pasul 3: Acum trebuie să calculăm probabilitatea posterioară folosind ecuația Naive Bayes pentru fiecare clasă.
Exemplu de problemă: o fată va merge la cumpărături dacă vremea este înnorată. Este corectă această afirmație?
Soluţie:
- P (Da | Înnourat) = (P (Înnorat | Da) * P (Da)) / P (Înnorat)
- P (Acoperit | Da) = 4/9 = 0, 44
- P (Da) = 9/14 = 0, 64
- P (Plușit) = 4/14 = 0, 39
Acum puneți toate valorile calculate în formula de mai sus
- P (Da | Acoperit) = (0, 44 * 0, 64) / 0, 39
- P (Da | Acoperit) = 0, 722
Clasa care are cea mai mare probabilitate ar fi rezultatul prezicerii. Utilizarea acelorași probabilități de abordare a diferitelor clase poate fi prevăzută.
Pentru ce se folosește algoritmul Naive Bayes?
1. Predicție în timp real: Algoritmul Naive Bayes este rapid și este întotdeauna gata să învețe, deci cel mai potrivit pentru predicțiile în timp real.
2. Predicție cu mai multe clase : Probabilitatea mai multor clase de orice variabilă țintă poate fi prevăzută folosind un algoritm Naive Bayes.
3. Sistem de recomandări: Clasificatorul Naive Bayes cu ajutorul Filtrării colaborative creează un Sistem de Recomandare. Acest sistem folosește tehnici de extragere a datelor și de învățare automată pentru a filtra informațiile care nu se văd înainte și apoi a prezice dacă un utilizator ar aprecia sau nu o resursă dată.
4. Clasificarea textului / Analiza sentimentelor / Filtrarea spamului: Datorită performanței sale mai bune cu probleme din mai multe clase și a regulii sale de independență, algoritmul Naive Bayes are o performanță mai bună sau are o rată mai mare de succes în clasificarea textului, prin urmare, este utilizat în analiza sentimentelor și Filtrare spam.
Avantajele algoritmului Naive Bayes
- Ușor de implementat.
- Rapid
- Dacă presupune independența, atunci funcționează mai eficient decât alți algoritmi.
- Necesită mai puține date de instruire.
- Este foarte scalabil.
- Poate face predicții probabilistice.
- Poate gestiona atât date continue, cât și discrete.
- Insensibil la caracteristicile irelevante.
- Poate funcționa ușor cu valori lipsă.
- Ușor de actualizat la sosirea datelor noi.
- Cel mai potrivit pentru problemele de clasificare a textului.
Dezavantajele algoritmului Naive Bayes
- Presupunerea puternică despre caracteristicile de a fi independente, ceea ce este cu adevărat adevărat în aplicațiile din viața reală.
- Lipsa de date.
- Șanse de pierdere a preciziei.
- Frecvență zero adică dacă categoria oricărei variabile categorice nu este văzută în setul de date de formare, atunci modelul atribuie o probabilitate zero acelei categorii și atunci nu se poate face o predicție.
Cum se construiește un model de bază folosind algoritmul Naive Bayes
Există trei tipuri de modele Naive Bayes, adică Gaussian, Multinomial și Bernoulli. Să discutăm pe scurt fiecare dintre ele.
1. Gaussian: Algoritmul Naive Bay Gaussian presupune că valorile continue corespunzătoare fiecărei caracteristici sunt distribuite în funcție de distribuția Gaussiană, de asemenea, numită distribuție normală.
Probabilitatea sau probabilitatea prealabilă a predictorului clasei date este presupusă a fi gaussiană, prin urmare, probabilitatea condițională poate fi calculată ca:
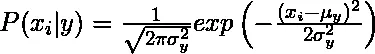
2. Multinomial: Frecvențele apariției anumitor evenimente reprezentate de vectorii caracteristici sunt generate cu ajutorul distribuției multinomiale. Acest model este utilizat pe scară largă pentru clasificarea documentelor.
3. Bernoulli: În acest model, intrările sunt descrise de caracteristicile care sunt variabile binare independente sau booleane. Acest lucru este, de asemenea, utilizat pe scară largă în clasificarea documentelor precum Multinomial Naive Bayes.
Puteți utiliza oricare dintre modelele de mai sus, conform cerințelor necesare pentru a gestiona și clasifica setul de date.
Puteți construi un model Gaussian folosind Python înțelegând exemplul dat mai jos:
Cod:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
ieşire:
((3, 4))
Concluzie
În acest articol, am învățat în detaliu conceptele Algoritmului Naive Bayes. Este folosit mai ales în clasificarea textului. Este ușor de implementat și de executat rapid. Dezavantajul său principal este că necesită ca funcțiile să fie independente, ceea ce nu este adevărat în aplicațiile din viața reală.
Articole recomandate
Acesta a fost un ghid pentru Algoritmul Naive Bayes. Aici am discutat Conceptul de bază, Lucrul, Avantajele și Dezavantajele Algoritmului Naive Bayes. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Îmbunătățirea algoritmului
- Algoritmul în programare
- Introducere în Algoritm