

Diferența dintre Hadoop și stup
Hadoop:
Hadoop este un cadru sau un software care a fost inventat pentru a gestiona date uriașe sau Big Data. Hadoop este utilizat pentru stocarea și procesarea datelor mari distribuite pe un grup de servere de mărfuri.
Hadoop stochează datele folosind sistemul de fișiere distribuit Hadoop și le prelucrează / interogează cu ajutorul modelului de programare Map Reduce.
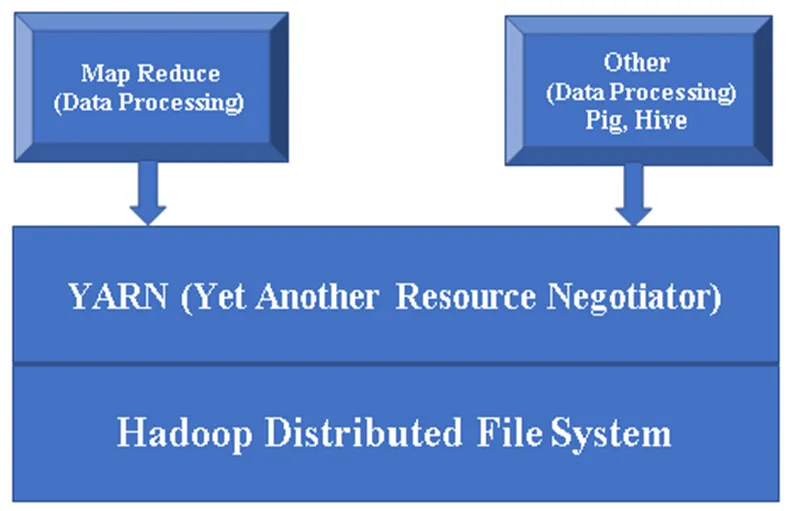
Figura 1, o arhitectură de bază a unei componente Hadoop.
Componentele majore ale lui Hadoop:
Hadoop Base / Common: Hadoop comun vă va oferi o singură platformă pentru a instala toate componentele sale.
HDFS (sistem de fișiere distribuite Hadoop): HDFS este o parte majoră a cadrului Hadoop, care are grijă de toate datele din Hadoop Cluster. Funcționează pe Arhitectura Master / Slave și stochează datele folosind replicare.
Master / Slave Architecture and Replication:
- Nod principal / Nume Nume: Nodul nume stochează metadatele fiecărui bloc / fișier stocate în HDFS, HDFS poate avea un singur nod principal (În cazul HA, un alt Nod principal va funcționa ca Nod principal secundar).
- Nod Slave / Nod de date: nodurile de date conțin fișiere de date reale în blocuri. HDFS poate avea mai multe noduri de date.
- Replicare: HDFS stochează datele sale împărțindu-le în blocuri. Dimensiunea implicită a blocului este de 64 MB. Datorită replicării datelor sunt stocate în 3 (factorul implicit de replicare, poate fi mărit după cerință) diferite noduri de date, deci există cea mai mică posibilitate de a pierde datele în cazul unei defecțiuni a nodului.
YARN (încă un negociator de resurse): este utilizat în principal pentru gestionarea resurselor Hadoop, de asemenea, joacă un rol important în programarea aplicațiilor utilizatorilor.
MR (Map Reduce): Acesta este modelul de programare de bază al Hadoop. Este utilizat pentru procesarea / interogarea datelor în cadrul Hadoop.
Stup:
Hive este o aplicație care trece peste cadrul Hadoop și oferă interfață asemănătoare SQL pentru procesarea / interogarea datelor. Hive este proiectat și dezvoltat de Facebook înainte de a deveni parte a proiectului Apache-Hadoop.
Hive își execută interogarea folosind HQL (limbajul de interogare Hive). Hive are aceeași structură ca RDBMS și aproape aceleași comenzi pot fi utilizate în Hive.
Hive poate stoca datele în tabele externe, astfel încât nu este obligatorie utilizarea HDFS, de asemenea, acesta acceptă formate de fișiere precum ORC, Avro, Fișiere de secvență și fișiere text etc.
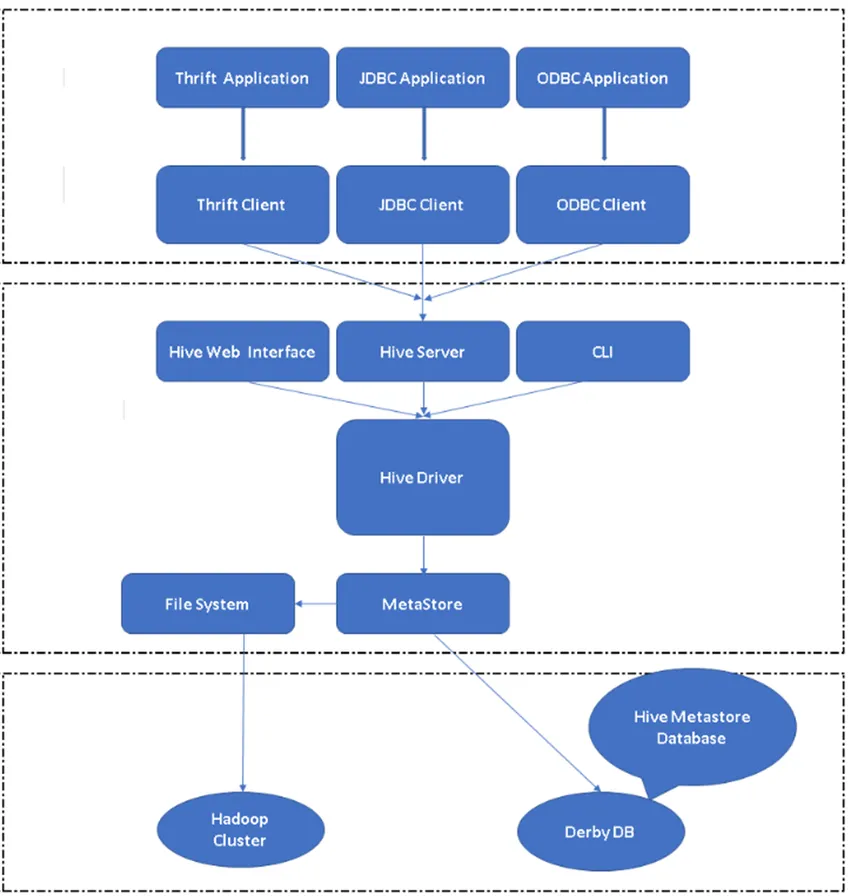
Figura 2, Arhitectura stupului și componentele sale majore.
Componenta principală a stupului:
Clienți Hive: Nu numai SQL, Hive acceptă, de asemenea, limbaje de programare precum Java, C, Python folosind diferite drivere precum ODBC, JDBC și Thrift. Se poate scrie orice aplicație client stup în alte limbi și se poate rula în stup utilizând acești Clienți.
Servicii Hive: În cadrul serviciilor Hive, executarea comenzilor și a interogărilor are loc. Hive Web Interface are cinci sub-componente.
- CLI: Interfață de linie de comandă implicită furnizată de Hive pentru executarea interogărilor / comenzilor Hive.
- Interfețe Hive Web: Este o interfață simplă de utilizator grafic. Este o alternativă la linia de comandă Hive și este utilizată pentru a rula interogările și comenzile din aplicația Hive.
- Hive Server: Se mai numește Apache Thrift. Este responsabil să preia comenzi de la diferite interfețe de linie de comandă diferite și să trimită toate comenzile / interogările către Hive, de asemenea, acesta preia rezultatul final.
- Driver Apache Hive: Este responsabil pentru preluarea intrărilor din interfețele CLI, UI web, ODBC, JDBC sau Thrift de către un client și trece informațiile către metastore unde sunt stocate toate informațiile despre fișiere.
- Metastore: Metastore este un depozit pentru a stoca toate informațiile despre metadatele Hive. Metadatele Hive stochează informații precum structura tabelelor, partițiilor și tipului de coloană etc …
Depozitare stup: este locația în care se execută sarcina reală, Toate întrebările care rulează din stup au efectuat acțiunea în stocarea stupului.
Comparație față în față între Hadoop și Hive (Infografie)
Mai jos este diferența de top 8 dintre Hadoop și Hive
Diferențele cheie între Hadoop și Hive:
Mai jos sunt listele de puncte, descrieți despre diferențele cheie dintre Hadoop și Hive:
1) Hadoop este un cadru pentru procesarea / interogarea datelor mari, în timp ce Hive este un instrument bazat pe SQL care se construiește prin Hadoop pentru a procesa datele.
2) Procesarea stupului / interogarea tuturor datelor utilizând HQL (limbajul de interogare Hive) este limbaj asemănător cu SQL, în timp ce Hadoop poate înțelege doar Reducerea Hărții.
3) Map Reduce este o parte integrantă a Hadoop, interogarea Hive este transformată mai întâi în Map Reduce decât prelucrată de Hadoop pentru a interoga datele.
4) Hive funcționează pe interogarea SQL Like, în timp ce Hadoop o înțelege folosind doar Map Reducerea bazată pe Java.
5) În Hive, comenzile tradiționale „bazele de date relaționale” folosite anterior pot fi, de asemenea, folosite pentru a interoga datele mari în timp ce în Hadoop, trebuie să scrie programe complexe Map Reduce folosind Java care nu este similar cu tradiția Java.
6) stupul poate prelucra / interoga numai datele structurate, în timp ce Hadoop este destinat tuturor tipurilor de date, indiferent dacă sunt structurate, nestructurate sau semistructurate.
7) Folosind Hive, se pot prelucra / interoga datele fără programare complexă, în timp ce în ecosistemul Hadoop Simplu, trebuie să scrie un program Java complex pentru aceleași date.
8) O parte de cadre Hadoop au nevoie de o linie de 100 pentru pregătirea programului MR bazat pe Java, o altă parte Hadoop cu Hive poate interoga aceleași date folosind 8 până la 10 linii de HQL.
9) În stup, este foarte dificil să inserați ieșirea unei interogări ca intrare a alteia, în timp ce aceeași interogare poate fi făcută ușor folosind Hadoop cu MR.
10) Nu este obligatoriu să aveți Metastore în clusterul Hadoop În timp ce Hadoop stochează toate metadatele sale în HDFS (Hadoop Distributed File System).
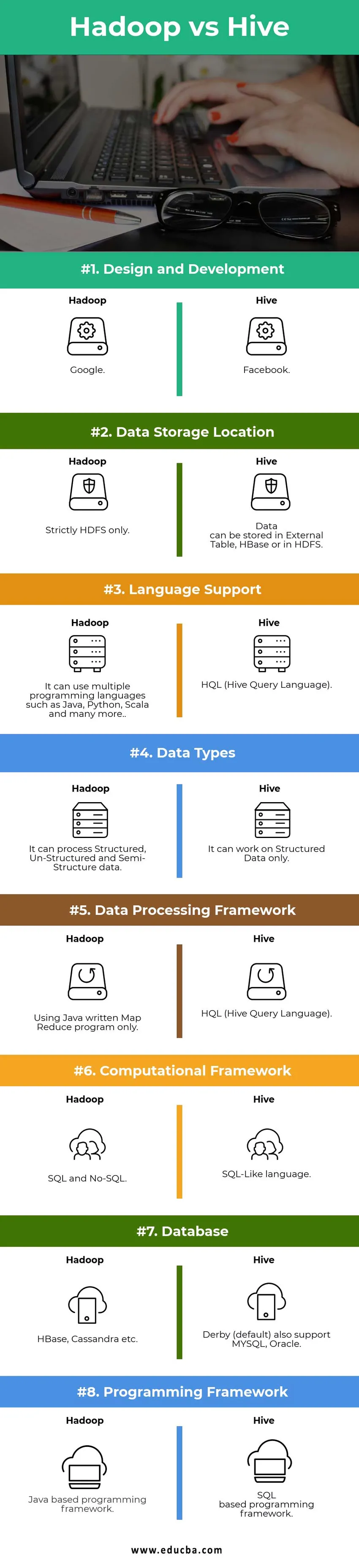
Tabelul de comparare Hadoop vs Hive
| Puncte de comparație | Stup | Hadoop |
|
Design și dezvoltare | ||
| Locație stocare date |
Datele pot fi stocate în extern Tabel, HBase sau în HDFS. | Doar pentru HDFS. |
| Suport lingvistic | HQL (limbă de interogare stupă) |
Poate utiliza mai multe limbaje de programare precum Java, Python, Scala și multe altele. |
| Tipuri de date | Poate funcționa numai pe Date structurate. |
Poate prelucra date structurate, nestructurate și semi-structurate. |
| Cadrul de prelucrare a datelor |
HQL (limbă de interogare stupă) | Folosirea programului Java Map Map Reduce doar. |
|
Cadrul de calcul | Limbaj asemănător cu SQL | SQL și No-SQL. |
| Bază de date |
Derby-ul (implicit) acceptă și MYSQL, Oracle … | HBase, Cassandra etc … |
| Cadrul de programare |
Cadru de programare bazat pe SQL. | Cadrul de programare bazat pe Java. |
Concluzie - Hadoop vs Hive
Hadoop și Hive sunt ambele utilizate pentru a prelucra Big Data. Hadoop este un cadru care oferă platformă pentru alte aplicații pentru interogarea / procesarea Big Data, în timp ce Hive este doar o aplicație bazată pe SQL care prelucrează datele folosind HQL (Hive Query Language)
Hadoop poate fi utilizat fără Hive pentru a prelucra datele mari, în timp ce nu este ușor de utilizat Hive fără Hadoop.
Ca o concluzie, nu putem compara Hadoop și Hive oricum și sub orice aspect. Atât Hadoop, cât și Hive sunt complet diferite. Folosirea ambelor tehnologii împreună poate face procesul de interogare Big Data mult mai ușor și confortabil pentru utilizatorii Big Data.
Articole recomandate:
Acesta a fost un ghid pentru Hadoop vs Hive, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparare și concluzii. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Hadoop vs Apache Spark - Lucruri interesante pe care trebuie să le știi
- HADOOP vs RDBMS | Cunoaște cele 12 diferențe utile
- Cât de mari sunt schimbarea datelor Asistenței medicale
- Top 12 Comparație dintre Apache Hive și Apache HBase (Infografie)
- Ghid uimitor pe Hadoop vs Spark