

Introducere în arborele decizional în extragerea datelor
În lumea de azi, pe „Big Data”, termenul „Data Mining” înseamnă că trebuie să analizăm seturi de date mari și să efectuăm „extragerea” datelor și să scoatem în evidență sucul sau esența importantă a ceea ce vor să spună datele. O situație foarte analogă este cea a mineritului de cărbune unde sunt necesare unelte diferite pentru minarea cărbunelui îngropat adânc sub pământ. Dintre instrumentele din data mining „Arborele de decizie” este unul dintre ele. Astfel, extragerea de date în sine este un domeniu vast în care în următoarele câteva paragrafe ne vom arunca în profunzime în „instrumentul” din Arborele de decizie din Data Mining.
Algoritmul arborelui decizional în data mining
Un arbore de decizie este o abordare de învățare supravegheată, în care formăm datele prezente, știind deja care este de fapt variabila țintă. După cum sugerează și numele, acest algoritm are un tip de structură arbore. Haideți să analizăm mai întâi aspectul teoretic al arborelui decizional și apoi să analizăm același lucru într-o abordare grafică. În arborele de decizii, algoritmul împarte setul de date în subseturi pe baza celui mai important sau semnificativ atribut. Cel mai semnificativ atribut este desemnat în nodul rădăcină și de acolo are loc divizarea întregului set de date prezent în nodul rădăcină. Această divizare făcută este cunoscută sub numele de noduri de decizie. În cazul în care nu mai este posibilă divizarea, nodul este denumit nod de frunză.
Pentru a opri algoritmul pentru a ajunge la o etapă copleșitoare, se folosește un criteriu de oprire. Unul dintre criteriile de oprire este numărul minim de observații din nod înainte de a se produce divizarea. În timp ce aplicați arborele de decizie în împărțirea setului de date, trebuie să aveți grijă ca multe noduri să aibă doar date zgomotoase. Pentru a rezolva problemele de date mai vechi sau zgomotoase, folosim tehnici cunoscute sub numele de Pruning Data. Tăierea datelor nu este altceva decât un algoritm de clasificare a datelor din subset, ceea ce face dificilă învățarea dintr-un model dat.
Algoritmul Tree Tree a fost lansat ca ID3 (Iterative Dichotomiser) de către cercetătorul de mașini J. Ross Quinlan. Ulterior C4.5 a fost lansat ca succesor al ID3. Atât ID3 cât și C4.5 sunt o abordare lacomă. Acum să ne uităm într-un diagramă a algoritmului Arborele Deciziei.
Pentru înțelegerea pseudocodului nostru, am lua „n” puncte de date, fiecare având atribute „k”. Mai jos este organizat fluxul ținând cont de „Câștigul de informații” ca condiție pentru o împărțire.
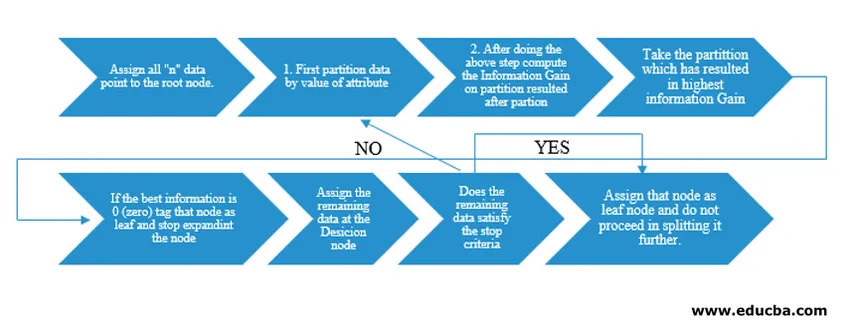
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
În loc de câștig de informații (IG), putem folosi, de asemenea, indicele Gini ca criterii de divizare. Pentru a înțelege diferența dintre aceste două criterii în termeni laici, ne putem gândi la acest câștig de informații ca diferență de entropie înainte de împărțire și după divizare (împărțit pe baza tuturor caracteristicilor disponibile).
Entropia este ca aleatoriu și am ajunge la un punct după divizare pentru a avea starea cea mai puțin aleatorie. Prin urmare, Informația Câștig trebuie să fie cea mai mare din funcția pe care dorim să o împărțim. Altfel, dacă dorim să alegem divizând pe baza indexului Gini, am găsi indexul Gini pentru atribute diferite și folosind același lucru aflăm indicele Gini ponderat pentru diferite împărțiri și îl vom folosi pe cel cu indexul Gini mai mare pentru a împărți setul de date.
Termeni importanți de Arborele de decizie în Data Mining
Iată câțiva dintre termenii importanți ai unui arbore decizional în extragerea de date prezentat mai jos:
- Nodul rădăcină: Acesta este primul nod în care are loc divizarea.
- Nodul frunzei: Acesta este nodul după care nu mai există ramificări.
- Nod de decizie: nodul format după divizarea datelor dintr-un nod anterior este cunoscut ca nod de decizie.
- Ramură: Subsecțiunea unui arbore care conține informații despre consecințele împărțirii la nodul decizional.
- Tăierea: Când există o îndepărtare a sub-nodurilor unui nod decizional pentru a răspunde unei date anterioare sau zgomotoase, se numește tăiere. De asemenea, se crede că este opusul divizării.
Aplicarea arborelui decizional în extragerea datelor
Arborul de decizii are un tip de arhitectură de flux integrat în funcție de tipul algoritmului. În esență, are un tipar „Dacă X atunci Y alt Z” în timp ce se face divizarea. Acest tip de model este utilizat pentru înțelegerea intuiției umane în câmpul programatic. Prin urmare, se poate folosi pe larg acest lucru în diferite probleme de categorizare.
- Acest algoritm poate fi utilizat pe scară largă în domeniul în care funcția obiectivă este legată de analiza făcută.
- Când există numeroase cursuri de acțiune disponibile.
- Analiză anterioară.
- Înțelegerea setului semnificativ de funcții pentru întregul set de date și „a mea”, câteva funcții dintr-o listă de sute de funcții din datele mari.
- Selectarea celui mai bun zbor pentru a călători către o destinație.
- Procesul decizional bazat pe diferite situații circumstanțiale.
- Analiza Churn.
- Analiza sentimentelor.
Avantajele arborelui decizional
Iată câteva avantaje ale arborelui decizional explicat mai jos:
- Ușor de înțeles: Modul în care este prezentat arborele decizional în formele sale grafice face ușor de înțeles pentru o persoană cu un fundal non-analitic. Mai ales pentru persoanele din conducere care doresc să privească care caracteristici sunt importante doar printr-o privire asupra arborelui de decizie poate scoate la iveală ipoteza lor.
- Explorarea datelor: Așa cum s-a discutat, obținerea de variabile semnificative este o funcționalitate de bază a arborelui decizional și folosirea acelorași, se poate da seama în timpul explorării datelor, pentru a decide ce variabilă ar avea nevoie de o atenție specială în cursul fazei de modelare și modelare.
- Există foarte puține intervenții umane în faza de pregătire a datelor și, ca urmare a timpului consumat în timpul datelor, curățarea se diminuează.
- Arborul de decizii este capabil să gestioneze variabile categorice, precum și numerice și, de asemenea, se ocupă cu probleme de clasificare cu mai multe clase.
- Ca parte a prezumției, arborii decizionali nu au nicio presupunere dintr-o distribuție spațială și o structură de clasificare.
Concluzie
În cele din urmă, pentru a încheia Arborii de decizie, aduc o clasă cu totul diferită de neliniaritate și rezolvă problemele legate de neliniaritate. Acest algoritm este cea mai bună alegere pentru a imita o gândire la nivel de decizie a oamenilor și a o înfățișa într-o formă matematic-grafică. Este nevoie de o abordare de sus în jos în determinarea rezultatelor din noile date nevăzute și urmează principiul divizării și cuceririi.
Articole recomandate
Acesta este un ghid pentru Arborele de decizie în Data Mining. Aici vom discuta despre algoritmul, importanța și aplicarea arborelui decizional în extragerea datelor împreună cu avantajele acestuia. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Învățarea mașinilor de știință a datelor
- Tipuri de tehnici de analiză a datelor
- Arborele de decizii în R
- Ce este data mining?
- Ghid pentru diverse metodologii de analiză a datelor