

Prezentare generală a aplicațiilor Kafka
Unul dintre domeniile în trend în industria IT este Big Data, unde compania se ocupă cu o cantitate mare de date despre clienți și obține informații utile care ajută afacerea lor și oferă clienților servicii mai bune. Una dintre provocări este gestionarea și transferul acestor volume mari de date de la un capăt la altul pentru analiză sau procesare, de aici intră în joc Kafka (un sistem de mesagerie fiabil), care ajută la colectarea și transportul unui volum imens de date. in timp real. Kafka este proiectat pentru sisteme distribuite cu debit mare și este o formă potrivită pentru aplicații de prelucrare a mesajelor la scară largă. Kafka acceptă multe dintre cele mai bune aplicații comerciale și industriale din zilele noastre. Există o cerere pentru profesioniștii Kafka care au abilități puternice și cunoștințe practice.
În acest articol, vom afla despre Kafka, caracteristicile sale, cazurile de utilizare și vom înțelege unele aplicații notabile unde este utilizat.
Ce este Kafka?
Apache Kafka a fost dezvoltat la LinkedIn și ulterior a devenit un proiect Apache open-source. Apache Kafka este un sistem de mesagerie rapid, tolerant la erori, scalabil și distribuit, care permite comunicarea între două entități, adică între producători (generatorul mesajului) și consumatori (receptorul mesajului) folosind subiecte bazate pe mesaje și oferă o platformă pentru gestionarea tuturor fluxurile de date în timp real.
Caracteristicile care fac ca Apache Kafka să fie mai bună decât alte sisteme de mesagerie și aplicabile sistemelor în timp real sunt disponibilitatea ridicată, recuperarea imediată și automată a eșecurilor nodului și acceptă livrarea de mesaje cu latență scăzută. Aceste caracteristici ale Apache Kafka ajută la integrarea acesteia cu sisteme de date la scară largă și îl fac o componentă ideală pentru comunicare. 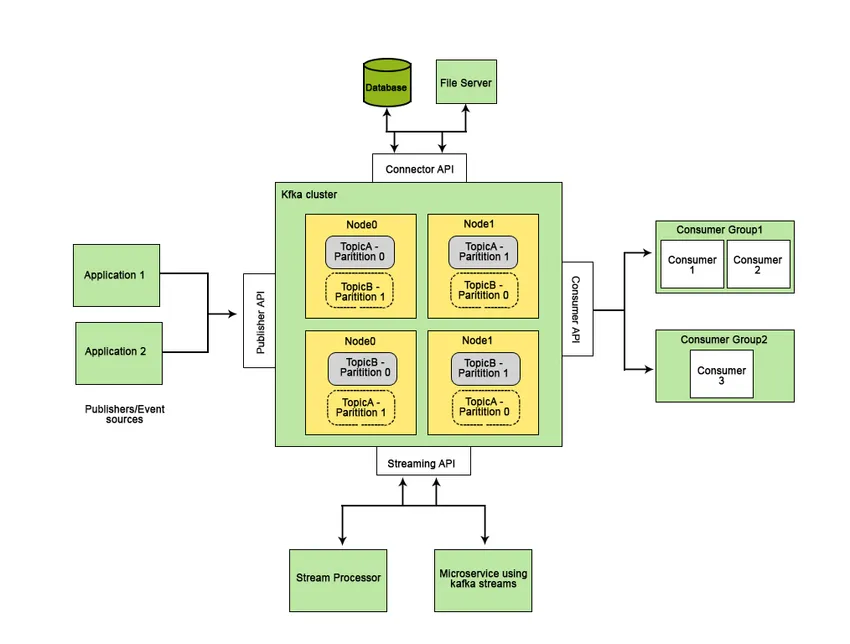
Aplicații de top Kafka
În această secțiune a articolului, vom vedea câteva cazuri de utilizare populare și aplicate pe scară largă și vom vedea unele implementări din viața reală a Kafka.
Aplicații în viața reală
1. Twitter: Activitate de procesare a fluxurilor
Twitter este o platformă de rețea socială care folosește Storm-Kafka (instrument de procesare a fluxurilor open-source) ca parte a infrastructurii lor de procesare a fluxurilor, unde datele de intrare (tweet-uri) sunt consumate pentru agregare, transformări și îmbogățire pentru consum suplimentar sau monitorizare. activități de procesare.
2. LinkedIn: Procesarea fluxurilor și măsurători
LinkedIn folosește Kafka pentru fluxul de date și pentru activitatea de măsurare operațională. LinkedIn folosește Kafka pentru funcțiile sale suplimentare, cum ar fi Newsfeed, pentru consumul de mesaje și pentru efectuarea analizei datelor primite.
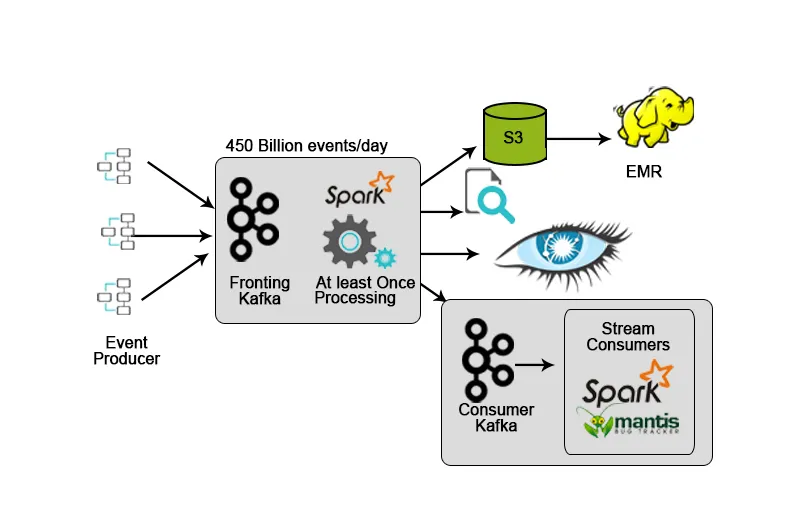
3. Netflix: Monitorizare în timp real și procesare flux
Netflix are propriul său cadru de ingestie care aruncă datele de intrare în AWS S3 și folosește Hadoop pentru a rula analize ale fluxurilor video, activități UI, evenimente pentru a îmbunătăți experiența utilizatorului și Kafka pentru ingestia de date în timp real prin API-uri.
4. Hotstar: procesare flux
Hotstar a introdus propria sa platformă de gestionare a datelor - Bifrost, unde Kafka este utilizat pentru streamingul de date, monitorizare și urmărire a țintelor. Datorită capacității sale de scalabilitate, disponibilitate și latență scăzută, Kafka a fost o alegere ideală pentru a gestiona datele pe care le generează platforma hotstar zilnic sau cu orice ocazie specială (transmisia în direct a oricăror concerte sau orice meci de sport live etc.) volumul de date crește semnificativ.
Apache Kafka de cele mai multe ori este utilizat ca un bloc de construcții pentru a dezvolta arhitectura de date în flux. Acest tip de arhitectură este utilizat în aplicații cum ar fi o colecție de jurnale de produse / server, analiza fluxului de clicuri și obținerea informațiilor din datele generate de mașini.
Dar împreună cu Kafka, trebuie să folosim resurse sau instrumente suplimentare pentru a converti fluxul de date obținut în date semnificative care ajută la obținerea unor informații care pot fi utilizate în deciziile bazate pe date. De exemplu, este posibil să avem nevoie să generăm informații despre datele brute obținute de pe dispozitivele IoT sau din datele obținute de pe platformele de socializare în timp real și să efectuăm unele analize sau prelucrări și să le prezentăm întreprinderii pentru a lua decizii mai bune sau pentru a le ajuta să îmbunătățească performanța serviciilor lor.
Pentru aceste tipuri de cazuri, am dori să transmitem datele noastre de intrare / datele brute într-un lac de date, unde să putem stoca datele noastre și să asigurăm calitatea datelor fără a împiedica performanța.
O situație diferită, am putea citi datele direct de la Kafka, este momentul în care avem nevoie de o latență extrem de scăzută, precum alimentarea datelor în aplicații în timp real.
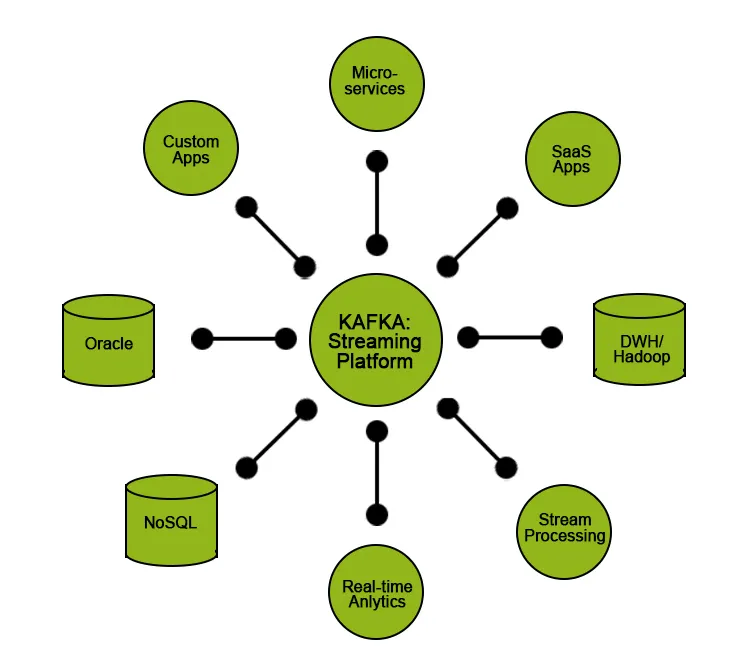
Kafka oferă anumite funcționalități utilizatorilor săi:
- Publicați și abonați-vă la date.
- Stocați datele în ordinea în care au fost generate în mod eficient.
- Prelucrare în timp real / în timp real a datelor.
Kafka de cele mai multe ori este folosit pentru:
- Implementarea unor conducte de transmisie de date în flux care obțin date fiabile între două entități din sistem.
- Implementarea fluxurilor de aplicații de zbor care transformă sau manipulează sau prelucrează fluxurile de date.
Cazuri de utilizare
Mai jos sunt prezentate câteva cazuri de utilizare pe scară largă ale aplicației Kafka:
1. Mesagerie
Kafka funcționează mai bine decât alte sisteme de mesagerie tradiționale, cum ar fi ActiveMQ, RabbitMQ, etc. În comparație, Kafka oferă un randament mai bun, facilități de partiție încorporate, replicare și toleranță la erori, ceea ce îl face un sistem de mesagerie mai bun pentru aplicații de procesare la scară largă. .
2. Urmărirea activității site-ului web
Activitățile utilizatorilor (vizualizări pe pagini, căutări sau orice acțiuni făcute) pot fi urmărite și alimentate pentru monitorizare sau analiză în timp real prin Kafka sau utilizați Kafka pentru a stoca aceste tipuri de date în Hadoop sau în depozitul de date pentru prelucrare sau manipulare ulterioară. Urmărirea activității generează o cantitate uriașă de date care trebuie transferate în locația dorită, fără pierderi de date.
3. Agregarea jurnalului
Agregarea jurnalului este un proces de colectare / îmbinare a fișierelor jurnal fizice de pe diferite servere ale unei aplicații într-un singur depozit (server de fișiere sau HDFS) pentru procesare. Kafka oferă performanțe bune, latență inferioară la capăt în comparație cu Flume.

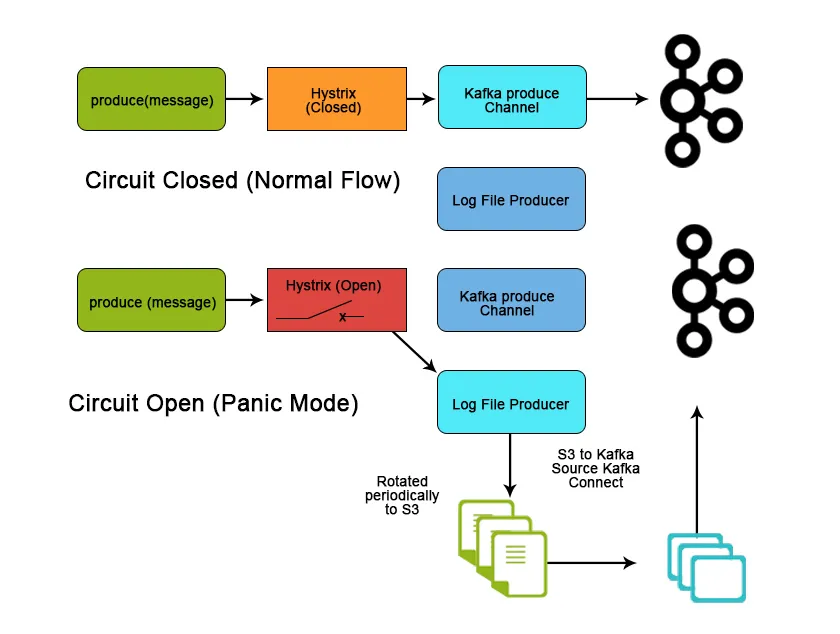
Concluzie
Kafka este utilizat foarte mult în spațiul mare de date ca o modalitate de a ingera și a muta cantități mari de date foarte rapid datorită caracteristicilor și caracteristicilor sale de performanță care ajută la obținerea scalabilității, fiabilității și durabilității. În acest articol, am discutat despre Apache Kafka despre caracteristicile sale, cazurile de utilizare și aplicația și ceea ce o face un instrument mai bun pentru transmiterea datelor.
Articole recomandate
Acesta este un ghid pentru Aplicațiile Kafka. Aici vom discuta despre ce este Kafka împreună cu aplicațiile de top ale Kafka, care includ cazuri de utilizare implementate pe scară largă și unele implementări din viața reală. De asemenea, puteți consulta următoarele articole pentru a afla mai multe-
- Ce este Kafka?
- Cum se instalează Kafka?
- Întrebări la interviu Kafka
- Apache Kafka vs Flume
- Top 8 dispozitive ale IoT pe care ar trebui să le știi
- Kafka vs Kinesis | Diferențe cu Infografia
- Diferite tipuri de instrumente Kafka cu componente
- Aflați diferențele de top ale ActiveMQ față de Kafka