

Diferența dintre MapReduce și Spark
Map Reduce este un cadru open-source pentru scrierea datelor în HDFS și procesarea datelor structurate și nestructurate prezente în HDFS. Map Reduce este limitată la procesarea lotului, iar pe alte Spark este capabil să efectueze orice tip de procesare. SPARK este un motor de procesare independent pentru procesare în timp real, care poate fi instalat pe orice sistem de fișiere distribuite, cum ar fi Hadoop. SPARK oferă o performanță de 10 ori mai rapidă decât Map Reduce pe disc și de 100 de ori mai rapid decât Map Reduce pe o rețea din memorie.
Nevoie de scânteie
- Analiza iterativă: Map-reduce nu este la fel de eficientă ca un SPARK pentru a rezolva problemele care necesită analize iterative, deoarece trebuie să meargă pe disc pentru fiecare iterație.
- Analitică interactivă: Map-reduce este adesea folosit pentru a rula interogări ad-hoc pentru care trebuie să ajungă la memoria de pe disc, care din nou nu este la fel de eficientă ca SPARK, deoarece aceasta din urmă se referă în memoria care este mai rapidă.
- Nu este potrivit pentru OLTP: deoarece funcționează pe cadrul orientat pe lot, nu este potrivit pentru un număr mare de tranzacții scurte.
- Nu este potrivit pentru grafic: biblioteca Apache Graph prelucrează graficul care adaugă mai multă complexitate Map Reduce.
- Nu este potrivit pentru operații banale: pentru operațiuni precum un filtru și uniri, ar putea fi necesar să rescriem lucrările, care devine mai complex din cauza modelului valorii cheie.
Comparație de la cap la cap între MapReduce și Spark (Infografie)
Mai jos se află diferența de top 15 între MapReduce și Spark

Diferențele cheie între MapReduce și Spark
Mai jos sunt listele de puncte, descrieți diferențele cheie între MapReduce și Spark:
- Spark este potrivit pentru timp real, deoarece se procesează folosind memorie, în timp ce MapReduce este limitat la procesarea lotului.
- Spark are RDD (Resilient Distributed Dataset) care ne oferă operatori la nivel înalt, dar în Map Map trebuie să codăm fiecare operațiune, ceea ce o face comparativ dificilă.
- Spark poate prelucra graficele și suportă instrumentul de învățare automată.
- Mai jos este diferența dintre ecosistemul MapReduce și Spark.
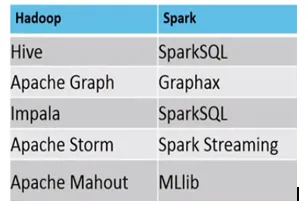
Exemplu, în care MapReduce vs Spark sunt potrivite, sunt următoarele
Scânteie: detectarea fraudelor cu cardul de credit
MapReduce: Elaborarea de rapoarte periodice care necesită luarea deciziilor.
Tabelul de comparare MapReduce vs Spark
| Bazele comparației | MapReduce | Scânteie |
| Cadru | Un cadru open-source pentru scrierea datelor în HDFS și procesarea datelor structurate și nestructurate prezente în HDFS. | Un cadru open-source pentru procesarea rapidă și generală a datelor |
| Viteză | Map-Reduce procesarea datelor (citește și scrie) de pe disc, astfel încât filtrarea este lentă în comparație cu Spark. | Spark este cu cel puțin 10X mai rapid pe disc și 100X mai rapid în memorie ca cel al Map Reduce. |
| Dificultate | Trebuie să codăm / să gestionăm fiecare proces. | Cu disponibilitatea RDD (Resilient Distributed Dataset), este ușor de programat. |
| Timp real | Nu este potrivit pentru tranzacția OLTP doar pentru modul Lot | Se poate ocupa de procesarea în timp real. Folosind SPARK Streaming. |
| Latență | Cadru de calcul pentru latență la nivel înalt | Cadru de calcul de latență la nivel scăzut. |
| Toleranță la erori | Daemonii maeștri verifică bătăile inimii demonilor sclavi și în cazul în care demoni sclavi nu reușesc daemoni maestri reprograma toate operațiunile pendinte și în curs de desfășurare la un alt sclav. | RDD asigură toleranță la erori la SPARK. Ele se referă la setul de date prezent în stocare externă (HDFS, HBase) și funcționează paralel. |
| Scheduler | În Map Reduce folosim un programator extern precum Oozie. | Deoarece SPARK funcționează cu calculatoare în memorie, acționează ca un programator propriu. |
| Cost | Map Reduce este relativ mai ieftin comparativ cu SPARK. | Deoarece funcționează în memorie, așa că necesită multă memorie RAM, ceea ce o face comparativ. |
| Platformă dezvoltată pe | Map Reduce a fost dezvoltat folosind Java. | SPARK a fost dezvoltat folosind Scala. |
| Limba acceptată | Map Reduce acceptă practic C, C ++, Ruby, Groovy, Perl, Python. | Spark acceptă Scala, Java, Python, R, SQL. |
| Asistență SQL | Map Reduce execută interogări folosind limbajul de interogare Hive. | Spark are propriul limbaj de interogare cunoscut sub numele de Spark SQL. |
| scalabilitate | În Reduceți harta putem adăuga până la n număr de noduri. Cel mai mare Hadoop Cluster are 14000 de noduri. | În Spark, de asemenea, putem adăuga n număr de noduri. Cel mai mare cluster Spark are 8000 de noduri. |
| Învățare automată | Map Reduce acceptă instrumentul Apache Mahout pentru învățarea mașinii. | Spark acceptă instrumentul MLlib pentru învățarea mașinii. |
| Caching | Reducerea hărții nu este în măsură să cacheze în datele de memorie, deci nu este la fel de rapid în comparație cu Spark. | Spark ascunde datele din memorie pentru mai multe iterații, astfel încât acestea sunt foarte rapide în comparație cu Map Reduce. |
| Securitate | Map Reduce acceptă mai multe proiecte și funcții de securitate în comparație cu Spark | Securitatea de scânteie nu este încă maturizată ca cea a Map Reduce |
Concluzie - MapReduce vs Spark
În conformitate cu diferența de mai sus dintre MapReduce și Spark, este destul de clar că SPARK este un motor de calcul mult mai avansat în comparație cu Map Reduce. Spark este compatibil cu orice tip de format de fișier și, de asemenea, destul de rapid decât Map Reduce. În plus, scânteia are, de asemenea, capacități de procesare grafică și de învățare automată.
Pe de o parte, Map Reduce este limitat la procesarea lotului, iar pe altă parte, Spark este capabil să efectueze orice tip de procesare (lot, interactiv, iterativ, streaming, grafic). Datorită compatibilității mari, Spark este favoritul Data Scientist și, prin urmare, înlocuiește Map Reduce și crește rapid. Dar totuși, trebuie să stocăm datele în HDFS și, de asemenea, putem avea nevoie de HBase. Deci trebuie să rulăm atât Spark cât și Hadoop pentru a obține cele mai bune.
Articole recomandate:
Acesta a fost un ghid pentru MapReduce vs Spark, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparare și concluzii. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- 7 lucruri importante despre Apache Spark (Ghid)
- Hadoop vs Apache Spark - Lucruri interesante pe care trebuie să le știi
- Apache Hadoop vs Apache Spark | Top 10 comparații pe care trebuie să le știi!
- Cum funcționează MapReduce?
- Confluența analizei tehnologiei și afacerilor