
Introducere în modelele de învățare automată
O imagine de ansamblu a diferitelor modele de învățare automată utilizate în practică. Urmând definiția, un model de învățare automată este o configurație matematică obținută după aplicarea metodologiilor specifice de învățare automată. Folosind gama extinsă de API-uri, construirea unui model de învățare a mașinilor este destul de simplă în zilele noastre, cu mai puține linii de coduri. Dar adevărata abilitate a unui profesionist în știința datelor aplicate constă în alegerea modelului corect bazat pe enunțul problemei și validare încrucișată, în loc să arunce date la algoritmi fantezi la întâmplare. În acest articol, vom discuta despre diverse modele de învățare automată și cum să le utilizăm în mod eficient pe baza tipului de probleme pe care le abordează.
Tipuri de modele de învățare a mașinilor
Pe baza tipului de sarcini, putem clasifica modelele de învățare automată în următoarele tipuri:
- Modele de clasificare
- Modele de regresie
- clustering
- Reducerea dimensionalității
- Învățare profundă etc.
1) Clasificare
În ceea ce privește învățarea automată, clasificarea este sarcina de a prezice tipul sau clasa unui obiect dintr-un număr finit de opțiuni. Variabila de ieșire pentru clasificare este întotdeauna o variabilă categorică. De exemplu, prezicerea unui e-mail este spam sau nu este o sarcină standard de clasificare binară. Acum să notăm câteva modele importante pentru problemele de clasificare.
- Algoritmul vecinilor apropiați K - simplu, dar exhaustiv din punct de vedere computerizat.
- Naive Bayes - Bazat pe teorema lui Bayes.
- Regresie logistică - model liniar pentru clasificarea binară.
- SVM - poate fi utilizat pentru clasificări binare / multiclase.
- Arborele de decizii - clasificatorul bazat pe „ dacă nu este altceva ”, mai robust pentru valori.
- Ansambluri - Combinație de mai multe modele de învățare automată pentru a obține rezultate mai bune.
2) Regresie
În aparat, regresia de învățare este un set de probleme în care variabila de ieșire poate lua valori continue. De exemplu, prezicerea prețului companiei aeriene poate fi considerată o sarcină de regresie standard. Să notăm câteva modele importante de regresie utilizate în practică.
- Regresie liniară - Modelul de bază cel mai simplu pentru sarcina de regresie funcționează bine doar atunci când datele sunt separabile liniar și este foarte puțin sau nu există multicollinearitate.
- Regresie Lasso - Regresie liniară cu regularizare L2.
- Ridge Regression - Regresie liniară cu regularizare L1.
- Regresia SVM
- Regresiunea arborelui decizional etc.
3) Clustering
În cuvinte simple, gruparea este sarcina de a grupa obiecte similare. Modelele de învățare automată ajută la identificarea automată a obiectelor similare fără intervenție manuală. Nu putem construi modele eficiente de învățare automată supravegheată (modele care trebuie instruite cu date curate sau etichetate manual) fără date omogene. Clustering-ul ne ajută să realizăm acest lucru într-un mod mai inteligent. Iată câteva dintre modelele de clustering utilizate pe scară largă:
- K înseamnă - Simplu, dar suferă de o variație mare.
- K înseamnă ++ - Versiunea modificată a K înseamnă.
- K medoizi.
- Clustering aglomerativ - Un model de clustering ierarhic.
- DBSCAN - algoritm de clustering bazat pe densitate etc.
4) Reducerea dimensionalității
Dimensionalitatea este numărul de variabile predictoare utilizate pentru a prezice variabila independentă sau target.often în seturile de date din lumea reală, numărul de variabile este prea mare. Prea multe variabile aduc, de asemenea, blestemul de adaptare la modele. În practică, printre aceste număr mare de variabile, nu toate variabilele contribuie în egală măsură la obiectiv și într-un număr mare de cazuri, putem păstra efectiv variațiile cu un număr mai mic de variabile. Să enumerăm câteva modele utilizate frecvent pentru reducerea dimensionalității.
- PCA - Creează un număr mai mic de noi variabile dintr-un număr mare de predictori. Noile variabile sunt independente una de cealaltă, dar mai puțin interpretabile.
- TSNE - Oferă încorporarea dimensiunilor inferioare a punctelor de date cu dimensiuni superioare.
- SVD - descompunerea valorii unice este utilizată pentru a descompune matricea în părți mai mici, pentru a calcula eficient.
5) Învățare profundă
Învățarea profundă este un subset de învățare automată care se ocupă de rețelele neuronale. Pe baza arhitecturii rețelelor neuronale, vom enumera importante modele de învățare profundă:
- Perceptron cu mai multe straturi
- Revoluții neuronale de evoluție
- Rețele neuronale recurente
- Mașină Boltzmann
- Auto-codificatoare etc.
Care model este cel mai bun?
Mai sus am luat idei despre o mulțime de modele de învățare automată. Acum ne vine în minte o întrebare evidentă „Care este cel mai bun model dintre ei?” Depinde de problema existentă și de alte atribute asociate, cum ar fi valorile exterioare, volumul de date disponibile, calitatea datelor, ingineria caracteristicilor, etc. În practică, este întotdeauna de preferat să începi cu cel mai simplu model aplicabil problemei și să crești complexitatea. treptat prin reglarea corectă a parametrilor și validarea încrucișată. Există un proverb în lumea științei datelor - „validarea încrucișată este mai de încredere decât cunoașterea domeniului”.
Cum să construiți un model?
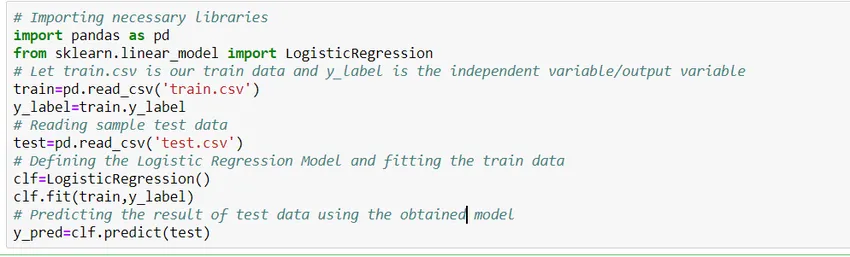
Să vedem cum se construiește un model de regresie logistică simplă folosind biblioteca Scikit Learn din python. Pentru simplitate, presupunem că problema este un model de clasificare standard, iar „train.csv” este trenul, respectiv „test.csv” este trenul și respectiv datele de testare.
Concluzie
În acest articol, am discutat despre modelele importante de învățare a mașinilor utilizate în scopuri practice și cum să construim un model simplu de învățare automată în python. Alegerea unui model adecvat pentru un anumit caz de utilizare este foarte importantă pentru a obține rezultatul adecvat al unei sarcini de învățare automată. Pentru a compara performanța dintre diverse modele, valorile de evaluare sau IPC sunt definite pentru anumite probleme de afaceri și cel mai bun model este ales pentru producție după aplicarea verificării statistice a performanței.
Articole recomandate
Acesta este un ghid pentru modelele de învățare automată. Aici discutăm principalele 5 tipuri de modele de învățare a mașinilor cu definiția sa. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Metode de învățare a mașinilor
- Tipuri de învățare automată
- Algoritmi de învățare a mașinilor
- Ce este învățarea automată?
- Hyperparameter Machine Learning
- KPI în Power BI
- Algoritmul de agregare ierarhică
- Gruparea Ierarhică | Gruparea aglomerativă și divizivă