

Diferența dintre Big Data și Apache Hadoop
Totul este pe Internet. Internetul are o mulțime de date. Prin urmare, totul este Big Data. Știți că 2, 5 Quintillion Bytes Data sunt create în fiecare zi și se acumulează ca Big Data? Activitățile noastre zilnice precum comentarea, aprecierile, postările etc. pe social media precum Facebook, LinkedIn, Twitter și Instagram se adaugă ca Big Data. Se presupune că până în anul 2020 vor fi create aproape 1, 7 megabyte de date în fiecare secundă pentru fiecare persoană de pe Pământ. Vă puteți imagina și lua în considerare cât de multe date sunt generate presupunând fiecare persoană de pe Pământ. Astăzi suntem conectați și ne împărtășim viața online. Cei mai mulți dintre noi suntem conectați online. Locuim într-o casă inteligentă și folosim vehicule inteligente și toate sunt conectate la telefoanele noastre inteligente. Vă imaginați cum devin aceste dispozitive inteligente? Vreau să vă dau un răspuns foarte simplu, deoarece se analizează cantitatea foarte mare de date, adică Big Data. În cinci ani, vor exista peste 50 de miliarde de dispozitive inteligente conectate în lume, toate dezvoltate pentru a colecta, analiza și partaja date pentru a ne face viața mai confortabilă.
Următoarele sunt prezentările Big Data vs Apache Hadoop
Introducerea termenului Big Data
Ce este Big Data? Ce dimensiune a datelor este considerată a fi mare și va fi denumită Big Data? Avem multe ipoteze relative pentru termenul Big Data. Este posibil ca cantitatea de date să spună că 50 terabyte pot fi considerate date mari pentru Start-up's, dar este posibil să nu fie Big Data pentru companii precum Google și Facebook. Se datorează faptului că au infrastructura pentru stocarea și procesarea acelei cantități de date. Aș dori să definesc termenul Big Data ca:
- Big Data este cantitatea de date care depășește capacitatea tehnologiei de a stoca, gestiona și prelucra eficient.
- Big Data sunt date a căror scară, diversitate și complexitate necesită o nouă arhitectură, tehnici, algoritmi și analize pentru a o gestiona și extrage valoarea și cunoștințele ascunse din ea.
- Datele mari reprezintă active de informații de mare volum și de mare viteză și de o varietate ridicată care necesită forme de procesare informațională eficiente și inovatoare care permit o perspectivă îmbunătățită, luarea deciziilor și automatizarea proceselor.
- Big Data se referă la tehnologii și inițiative care implică date prea diverse, care se schimbă rapid sau masiv pentru ca tehnologiile, abilitățile și infrastructura convenționale să se abordeze eficient. Altfel spus, volumul, viteza sau varietatea de date sunt prea mari.
3 V-uri de date mari
- Volum: Volumul se referă la cantitatea / cantitatea la care se creează datele ca în fiecare oră, tranzacțiile clienților Wal-Mart oferă companiei aproximativ 2, 5 petabytes de date.
- Viteza: viteza se referă la viteza cu care se mișcă datele, precum utilizatorii Facebook trimit în medie 31, 25 milioane de mesaje și vizualizează 2, 77 milioane de videoclipuri în fiecare minut pe fiecare zi pe internet.
- Soi: Varietatea se referă la diferite formate de date care sunt create ca date structurate, semi-structurate și nestructurate. Cum ar fi Trimiterea de e-mailuri cu atașamentul pe Gmail sunt date nestructurate în timp ce postarea oricăror comentarii cu unele link-uri externe este denumită, de asemenea, date nestructurate. Partajarea de imagini, clipuri audio, videoclipuri sunt o formă nestructurată de date.
Depozitarea și procesarea acestui volum imens, viteză și varietate de date este o mare problemă. Trebuie să ne gândim la alte tehnologii, altele decât RDBMS pentru Big Data. Se datorează faptului că RDBMS este capabil să stocheze și să proceseze doar date structurate. Deci, aici Apache Hadoop vine ca o salvare.
Prezentarea termenului Apache Hadoop
Apache Hadoop este un cadru software open-source pentru stocarea datelor și rularea aplicațiilor pe clustere de hardware-uri de bază. Apache Hadoop este un cadru software care permite procesarea distribuită a seturilor de date mari prin clustere de computere folosind modele simple de programare. Este conceput pentru a crește de la un singur server la mii de mașini, fiecare oferind calcule și stocare locale. Apache Hadoop este un cadru atât pentru stocarea cât și pentru procesarea Big Data. Apache Hadoop este capabil să stocheze și să proceseze toate formatele de date precum date structurate, semi-structurate și nestructurate. Apache Hadoop este o sursă deschisă și hardware-ul de marfă a adus revoluție industriei IT. Este ușor accesibil pentru toate nivelurile companiilor. Ei nu trebuie să investească mai mult pentru a configura clusterul Hadoop și pe infrastructură diferită. Așadar, ne permite să vedem în detaliu diferența utilă dintre Big Data și Apache Hadoop în această postare.
Cadrul Apache Hadoop
Cadrul Apache Hadoop este împărțit în două părți:
- Sistemul de fișiere distribuit Hadoop (HDFS): Acest strat este responsabil pentru stocarea datelor.
- MapReduce: Acest strat este responsabil pentru procesarea datelor de pe Hadoop Cluster.
Cadrul Hadoop este împărțit în arhitectură master și slave. Stratul de sistem de fișiere distribuit Hadoop (HDFS) Nume nume Nodul este component principal, în timp ce Nodul de date este component Slave în timp ce în stratul MapReduce Job Tracker este componenta principală, în timp ce trackerul de sarcini este componentul slave. Mai jos este diagrama pentru cadrul Apache Hadoop.
De ce este important Apache Hadoop?
- Capacitatea de a stoca și prelucra rapid cantități uriașe de orice fel de date
- Putere de calcul: modelul de calcul distribuit al lui Hadoop procesează rapid datele mari. Cu cât utilizați mai multe noduri de calcul, cu atât aveți mai multă putere de procesare.
- Toleranță la erori: prelucrarea datelor și a aplicațiilor sunt protejate împotriva defecțiunilor hardware. Dacă un nod coboară, lucrările sunt redirecționate automat către alte noduri pentru a vă asigura că calculul distribuit nu reușește. Mai multe copii ale tuturor datelor sunt stocate automat.
- Flexibilitate: puteți stoca cât mai multe date doriți și decide cum să le utilizați mai târziu. Aceasta include date nestructurate, cum ar fi text, imagini și videoclipuri.
- Cost redus: Cadrul open-source este gratuit și folosește hardware-ul de marfă pentru a stoca cantități mari de date.
- Scalabilitate: puteți crește cu ușurință sistemul dvs. pentru a gestiona mai multe date doar prin adăugarea de noduri. Administrare mică este necesară
Comparație dintre capete în cap între Big Data vs Apache Hadoop (Infografie)
Mai jos este Top 4 Comparație între Big Data și Apache Hadoop
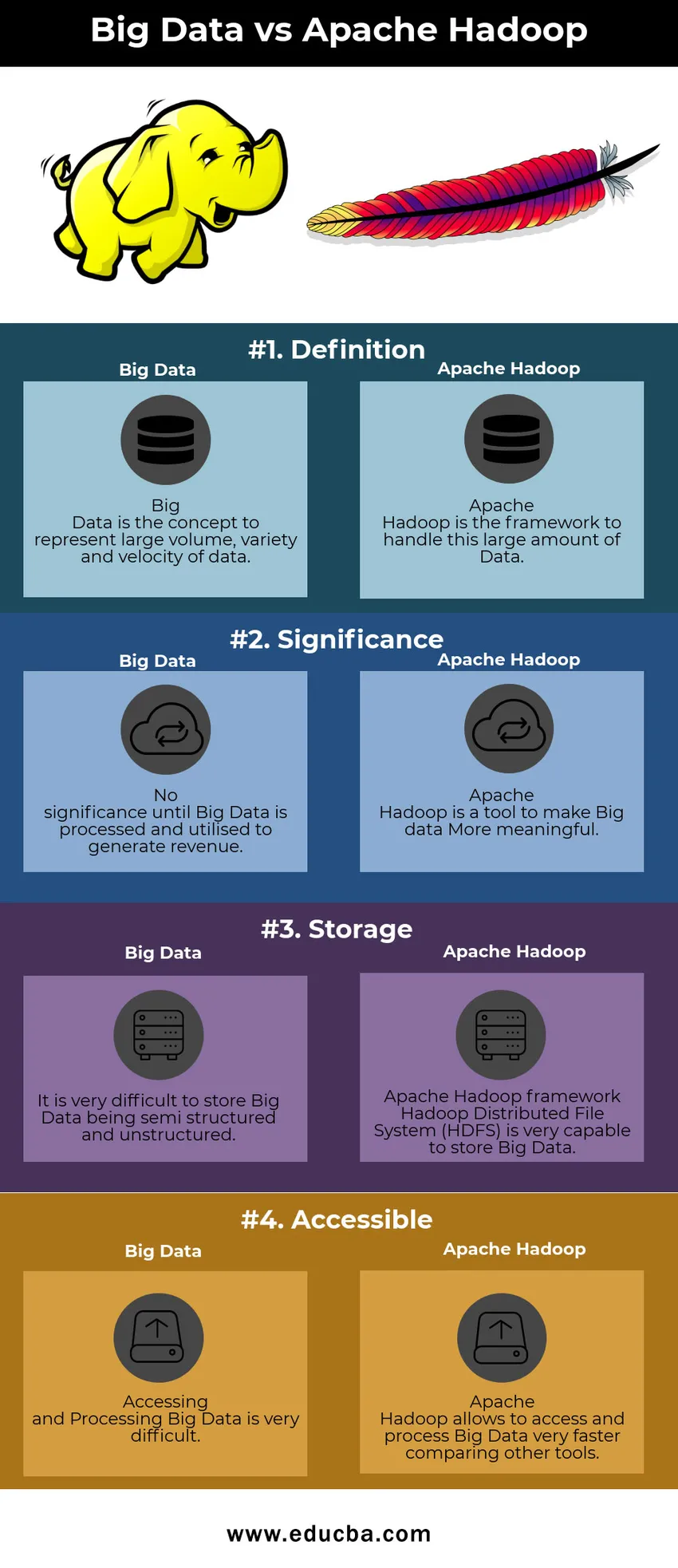
Tabel de comparație Big Data vs Apache Hadoop
Discut despre artefacte majore și disting între Big Data și Apache Hadoop
| Date mare | Apache Hadoop | |
| Definiție | Big Data este conceptul care reprezintă volumul, varietatea și viteza mare a datelor | Apache Hadoop este cadrul pentru gestionarea acestei cantități mari de date |
| Semnificaţie | Nicio importanță până când Big Data nu este procesată și utilizată pentru a genera venituri | Apache Hadoop este un instrument pentru ca datele Big să fie mai semnificative |
| Depozitare | Este foarte dificil să stocați Big Data fiind semi-structurate și nestructurate | Sistemul de fișiere distribuite Hadoop (HDFS) Apache Hadoop este foarte capabil să stocheze Big Data |
| Accesibil | Accesarea și procesarea datelor mari este foarte dificilă | Apache Hadoop permite accesarea și procesarea Big Data comparativ mai rapid cu alte instrumente |
Concluzie - Big Data vs Apache Hadoop
Nu puteți compara Big Data și Apache Hadoop. Se datorează faptului că Big Data este o problemă, în timp ce Apache Hadoop este Soluția. Deoarece cantitatea de date crește exponențial în toate sectoarele, este foarte dificil să stocați și să prelucrați datele dintr-un singur sistem. Deci, pentru a procesa această cantitate mare de date, avem nevoie de procesare distribuită și stocare de date. Prin urmare, Apache Hadoop vine cu soluția de stocare și procesare a unei cantități foarte mari de date. În sfârșit, voi concluziona Big Data este o cantitate mare de date complexe, în timp ce Apache Hadoop este un mecanism de stocare și procesare a Big Data foarte eficient și fără probleme.
Articol recomandat
Acesta a fost un ghid pentru Big Data vs Apache Hadoop, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparare și concluzii. acest articol constă din toată diferența utilă între Big Data și Apache Hadoop. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Big Data vs Știința Datelor - Cum sunt ele diferite?
- Top 5 mari tendințe de date pe care companiile vor trebui să le stăpânească
- Hadoop vs Apache Spark - Lucruri interesante pe care trebuie să le știi
- Apache Hadoop vs Apache Spark | Top 10 comparații pe care trebuie să le știi!