

Introducere în exploatarea datelor
Aceasta este o metodă de extragere a datelor utilizată pentru plasarea elementelor de date în grupurile lor similare. Clusterul este procedura de divizare a obiectelor de date în subclase. Calitatea de clustering depinde de metoda pe care am folosit-o. Clustering-ul se mai numește și segmentare de date, deoarece grupurile mari de date sunt împărțite prin asemănarea lor.
Ce este gruparea în minerirea datelor?
Clustering-ul reprezintă gruparea unor obiecte specifice pe baza caracteristicilor și asemănărilor lor. În ceea ce privește extragerea datelor, această metodologie împarte datele care sunt cele mai potrivite pentru analiza dorită folosind un algoritm special de unire. Această analiză permite unui obiect să nu facă parte sau să facă parte strict dintr-un cluster, ceea ce se numește împărțirea dură a acestui tip. Cu toate acestea, partițiile netede sugerează că fiecare obiect în același grad aparține unui cluster. Pot fi create mai multe divizii specifice ca obiecte ale mai multor clustere, un singur grup poate fi forțat să participe sau chiar arborii ierarhici pot fi construiți în relațiile de grup. Acest sistem de fișiere poate fi pus în aplicare în moduri diferite, bazate pe diverse modele. Acești algoritmi distincți se aplică fiecărui model, distingându-și proprietățile, precum și rezultatele. Un algoritm de clustering bun este capabil să identifice clusterul independent de forma clusterului. Există 3 etape de bază ale algoritmului de clustering, care sunt prezentate mai jos
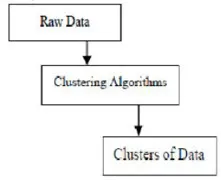
Gruparea algoritmilor în data mining
În funcție de modelele de cluster descrise recent, multe cluster-uri pot fi utilizate pentru a partiționa informațiile într-un set de date. Trebuie spus că fiecare metodă are propriile avantaje și dezavantaje. Selecția unui algoritm depinde de proprietățile și natura setului de date.
Metodele de clustering pentru data mining pot fi afișate mai jos
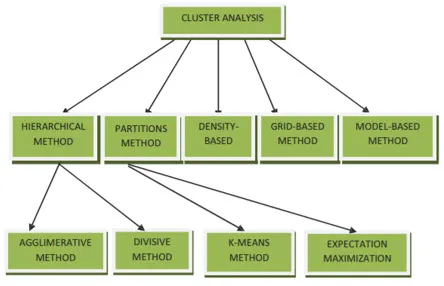
- Metoda bazată pe partiționare
- Metoda bazată pe densitate
- Metoda bazată pe centroid
- Metoda ierarhică
- Metoda bazată pe grilă
- Metoda bazată pe model
1. Metoda bazată pe partiționare
Algoritmul de partiție împarte datele în mai multe subseturi.
Să presupunem că algoritmul de partiționare construiește partiția de date întrucât obiectele k și n sunt prezente în baza de date. Prin urmare, fiecare partiție va fi reprezentată ca k ≤ n.
Aceasta dă o idee că clasificarea datelor este în grupe k, care poate fi arătată mai jos
Figura 1 prezintă puncte originale în grupări

Figura 2 prezintă clusteringul de partiții după aplicarea unui algoritm
Aceasta indică faptul că fiecare grup are cel puțin un obiect, precum și fiecare obiect, trebuie să aparțină exact unui grup.
2. Metoda bazată pe densitate
Acești algoritmi produc clustere într-o locație determinată pe baza densității mari a participanților la setul de date. Agregează o anumită noțiune de intervale pentru membrii grupului din grupuri la un nivel standard de densitate. Astfel de procese pot efectua mai puțin în detectarea suprafețelor grupului.
3. Metoda bazată pe centroid
Aproape fiecare cluster este referit de un vector de valori în acest tip de tehnică de grupare os. În comparație cu alte clustere, fiecare obiect face parte din cluster cu o diferență minimă de valoare. Numărul de clustere ar trebui să fie predefinit și aceasta este cea mai mare problemă de algoritm de acest tip. Această metodologie este cea mai apropiată de subiectul identificării și este utilizată pe scară largă pentru probleme de optimizare.
4. Metoda ierarhică
Metoda va crea o descompunere ierarhică a unui set dat de obiecte de date. Pe baza modului în care se formează descompunerea ierarhică, putem clasifica metodele ierarhice. Această metodă este dată după cum urmează
- Abordare aglomerativă
- Abordare divizivă
Abordarea aglomerativă este, de asemenea, cunoscută sub denumirea de Abordare butonată. Aici începem cu fiecare obiect care constituie un grup separat. Continuă să contopească obiecte sau grupuri strânse
Abordarea divizivă este, de asemenea, cunoscută ca abordarea de sus în jos. Începem cu toate obiectele din același cluster. Această metodă este rigidă, adică nu poate fi anulată niciodată odată ce o fuziune sau divizare este finalizată
5. Metoda bazată pe grilă
Metodele bazate pe grilă funcționează în spațiul obiectului în loc să împartă datele într-o grilă. Grila este împărțită pe baza caracteristicilor datelor. Utilizând această metodă datele care nu sunt numerice sunt ușor de gestionat. Ordinea datelor nu afectează partiționarea grilei. Un avantaj important al unui model bazat pe grilă, asigură o viteză de execuție mai rapidă.
Avantajele grupării ierarhice sunt următoarele
- Se aplică oricărui tip de atribut.
- Oferă flexibilitate legată de nivelul de granularitate.
6. Metoda bazată pe model
Această metodă utilizează un model ipotezat bazat pe distribuția probabilităților. Prin gruparea funcției de densitate, această metodă localizează clusterele. Acesta reflectă distribuția spațială a punctelor de date.
Aplicarea clusteringului în Data Mining
Clusteringul poate ajuta în multe domenii, cum ar fi în Biologie, Plante și animale clasificate atât prin proprietățile lor, cât și în marketing, Clustering va ajuta la identificarea clienților unei anumite înregistrări ale clienților cu o conduită similară. În multe aplicații, precum cercetarea de piață, recunoașterea tiparelor, prelucrarea datelor și a imaginilor, analiza de grup este utilizată în număr mare. Clusteringul poate ajuta, de asemenea, agenții de publicitate din baza lor de clienți să găsească diferite grupuri. Și grupurile lor de clienți pot fi definite prin modele de cumpărare. În biologie, este utilizat pentru determinarea taxonomiilor plantelor și animalelor, pentru clasificarea genelor cu funcționalități similare și pentru cunoașterea structurilor inerente populației. Într-o bază de date de observare a pământului, aglomerarea facilitează, de asemenea, găsirea unor zone de utilizare similară în teren. Ajută la identificarea grupurilor de case și apartamente în funcție de tipul, valoarea și destinația caselor. Gruparea documentelor de pe web este de asemenea utilă pentru descoperirea informațiilor. Analiza clusterului este un instrument pentru a obține o perspectivă asupra distribuției datelor pentru a observa caracteristicile fiecărui cluster ca funcție de extragere a datelor.
Concluzie
Clusteringul este important în minerirea datelor și analiza acestora. În acest articol, am văzut cum se poate face clusteringul aplicând diferiți algoritmi de clustering, precum și aplicarea acesteia în viața reală.
Articol recomandat
Acesta a fost un ghid pentru Ce este clustering în Data Mining. Aici am discutat conceptele, definiția, caracteristicile, aplicarea Clustering în Data Mining. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Ce este procesarea datelor?
- Cum să devii analist de date?
- Ce este SQL Injection?
- Definiția ce este SQL Server?
- Prezentare generală a arhitecturii de extragere a datelor
- Gruparea în învățarea mașinilor
- Algoritmul de agregare ierarhică
- Gruparea Ierarhică | Gruparea aglomerativă și divizivă