
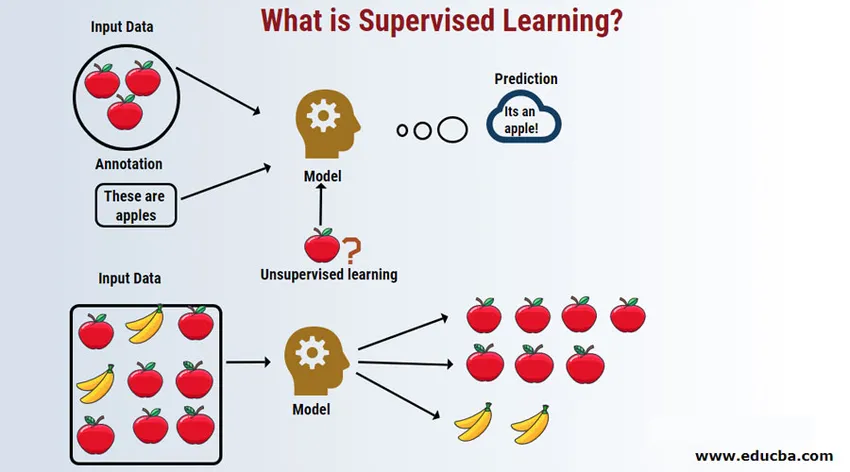
Introducere în învățarea supravegheată
Învățarea supravegheată este un domeniu de învățare automată unde lucrăm la prezicerea valorilor folosind seturi de date etichetate. Seturile de date de intrare etichetate se numesc variabilă independentă, în timp ce rezultatele prezise sunt numite variabilă dependentă, deoarece acestea depind de variabila independentă pentru rezultatele lor. De exemplu, cu toții avem în contul nostru de e-mail (de exemplu, Gmail) dosarul de spam care detectează automat cele mai multe e-mailuri de spam / fraudă cu o precizie mai mare de 95%. Funcționează pe baza unui model de învățare supravegheat, unde avem un set de instruire de date etichetate, care, în acest caz, este un e-mail spam etichetat de utilizatori. Aceste seturi de instruire sunt utilizate pentru învățare, care ulterior vor fi utilizate pentru clasificarea noilor e-mailuri ca spam, dacă se potrivesc categoriei.
Lucrul la învățarea mașinii supravegheate
Să înțelegem învățarea automată supravegheată cu ajutorul unui exemplu. Să zicem că avem coș de fructe care este completat cu diferite specii de fructe. Treaba noastră este să clasificăm fructele în funcție de categoria lor.
În cazul nostru, am avut în vedere patru tipuri de fructe, iar acestea sunt mărul, banana, strugurii și portocalele.
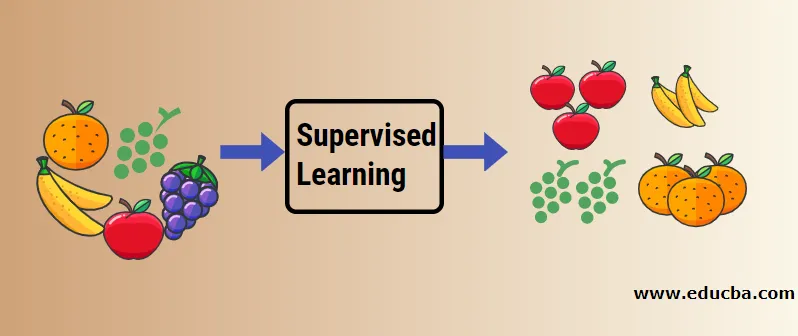
Acum vom încerca să menționăm câteva dintre caracteristicile unice ale acestor fructe care le fac unice.
|
S nu. | mărimea | Culoare | Formă |
Nume |
|
1 | Mic | Verde | Rotund până la oval, în formă de buchet Cilindric |
strugure |
|
2 | Mare | roșu | Formă rotunjită cu o depresiune în vârf |
măr |
|
3 | Mare | Galben | Cilindru lung curb |
Banană |
| 4 | Mare | portocale | Forma rotunjită |
portocale |
Acum să spunem că ați ales un fruct din coșul de fructe, ați examinat caracteristicile acestuia, de exemplu forma, dimensiunea și culoarea acestuia, de exemplu, apoi deduceți că culoarea acestui fruct este roșie, dimensiunea dacă este mare, forma este rotunjită cu depresiune în partea de sus, de unde este un măr.
- La fel, faceți la fel și pentru toate celelalte fructe rămase.
- Coloana din dreapta („Nume fruct”) este cunoscută sub numele de variabilă de răspuns.
- Așa formulăm un model de învățare supravegheat, acum va fi destul de ușor pentru oricine nou (Să zicem un robot sau un extraterestru) cu proprietăți date pentru a grupa ușor același tip de fructe împreună.
Tipuri de algoritm de învățare a mașinilor supravegheate
Să vedem diferite tipuri de algoritmi de învățare automată:
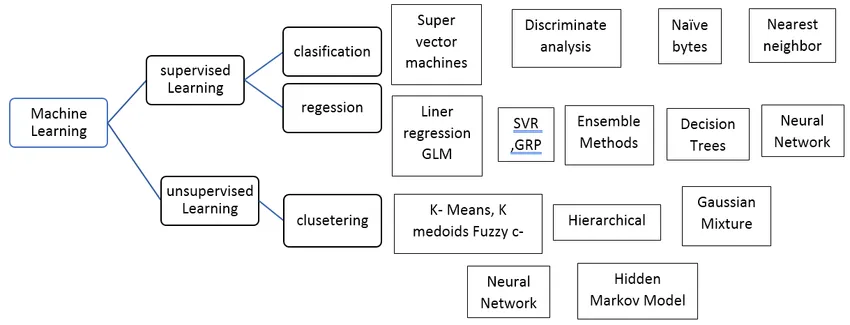
regresie:
Regresia este utilizată pentru a prezice o ieșire de o singură valoare folosind setul de date de instruire Valoarea de ieșire este numită întotdeauna ca variabilă dependentă, în timp ce intrările sunt cunoscute sub numele de variabilă independentă. Avem diferite tipuri de regresie în învățarea supravegheată, de exemplu,
- Regresie liniară - Aici avem o singură variabilă independentă care este utilizată pentru a prezice ieșirea, adică variabila dependentă.
- Regresie multiplă - Aici avem mai mult de o variabilă independentă care este utilizată pentru a prezice ieșirea, adică variabila dependentă.
- Regresie polinomială - Aici graficul dintre variabilele dependente și independente urmărește o funcție polinomială. De exemplu, la început, memoria crește odată cu vârsta, apoi atinge un prag la o anumită vârstă, apoi începe să scadă pe măsură ce îmbătrânim.
Clasificare:
Clasificarea algoritmilor de învățare supravegheată este utilizată pentru a grupa obiecte similare în clase unice.
- Clasificare binară - Dacă algoritmul încearcă să grupeze 2 grupuri distincte de clase, atunci se numește clasificare binară.
- Clasificare multiclasa - Dacă algoritmul încearcă să grupeze obiecte în mai mult de 2 grupuri, atunci se numește clasificare multiclasă.
- Forță - Algoritmii de clasificare funcționează de obicei foarte bine.
- Dezavantaje - predispuse la adaptare excesivă și poate fi neconstruită. De exemplu - Clasificator spam spam
- Regresie / clasificare logistică - Când variabila Y este o categorie binară (adică 0 sau 1), folosim regresia logistică pentru predicție. De exemplu - Prezicerea dacă o tranzacție dată cu un card de credit este o fraudă sau nu.
- Clasificatorii Naïve Bayes - Clasificatorul Naïve Bayes se bazează pe teorema bayesiană. Acest algoritm este de obicei cel mai potrivit atunci când dimensionalitatea intrărilor este mare. Este format din grafice aciclice care au un singur părinte și mulți noduri copii. Nodurile copil sunt independente unele de altele.
- Arborii de decizie - Un arbore de decizie este o structură de arbore ca o structură care constă dintr-un nod intern (test pe atribut), ramură care indică rezultatul testului și nodurile frunze care reprezintă distribuția claselor. Nodul rădăcină este nodul cel mai de sus. Este o tehnică foarte larg utilizată pentru clasificare.
- Mașină de asistență vectorială - O mașină de susținere a vectorului este sau un SVM face treaba de clasificare prin găsirea hiperplanului care ar trebui să maximizeze marja între 2 clase. Aceste aparate SVM sunt conectate la funcțiile kernel-ului. Câmpurile, unde SVM sunt utilizate pe scară largă, sunt biometria, recunoașterea modelului etc.
avantaje
Mai jos sunt câteva dintre avantajele modelelor de învățare automată supravegheate:
- Performanțele modelelor pot fi optimizate prin experiențele utilizatorului.
- Învățarea supravegheată produce rezultate folosind experiența anterioară și vă permite, de asemenea, să colectați date.
- Algoritmii de învățare automată supravegheată pot fi folosiți pentru implementarea mai multor probleme din lumea reală.
Dezavantaje
Dezavantajele învățării supravegheate sunt următoarele:
- Efortul de a pregăti modele de învățare automată supravegheate poate dura mult timp dacă setul de date este mai mare.
- Clasificarea datelor mari prezintă uneori o provocare mai mare.
- S-ar putea ca cineva să fie nevoit să se ocupe de problemele de montare.
- Avem nevoie de multe exemple bune dacă dorim ca modelul să funcționeze bine în timp ce formăm clasificatorul.
Bune practici în timp ce construiești modele de învățare
Este o practică bună în timp ce construiți o mașină de învățare supravegheată Modele: -
- Înainte de a construi un model bun de învățare a mașinilor, procesul de preprocesare a datelor trebuie efectuat.
- Trebuie să decidem algoritmul care ar trebui să fie cel mai potrivit pentru o anumită problemă.
- Trebuie să decidem ce tip de date vor fi utilizate pentru setul de instruire.
- Trebuie să decidă structura și funcția algoritmului.
Concluzie
În articolul nostru, am aflat ce este învățarea supravegheată și am văzut că aici formăm modelul folosind date etichetate. Apoi am intrat în lucrarea modelelor și a diferitelor lor tipuri. În cele din urmă am văzut avantajele și dezavantajele acestor algoritmi de învățare automată supravegheată.
Articole recomandate
Acesta este un ghid pentru ceea ce este învățarea supravegheată ?. Aici discutăm conceptele, modul în care funcționează, tipurile, avantajele și dezavantajele învățării supravegheate. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Ce este învățarea profundă
- Învățare supravegheată vs. învățare profundă
- Ce este Sincronizarea în Java?
- Ce este Web Gazduire?
- Moduri de a crea arborele de decizie cu avantaje
- Regresia polinomială | Utilizări și caracteristici