
Introducere în învățare de consolidare
Învățarea de consolidare este un tip de învățare automată și, prin urmare, este, de asemenea, o parte a Inteligenței artificiale, atunci când sunt aplicate sistemelor, sistemele efectuează pași și învață pe baza rezultatului pașilor pentru a obține un obiectiv complex care este stabilit pentru sistem.
Înțelegeți consolidarea învățării
Să încercăm să lucrăm la învățarea de consolidare cu ajutorul a 2 cazuri simple de utilizare:
Cazul 1
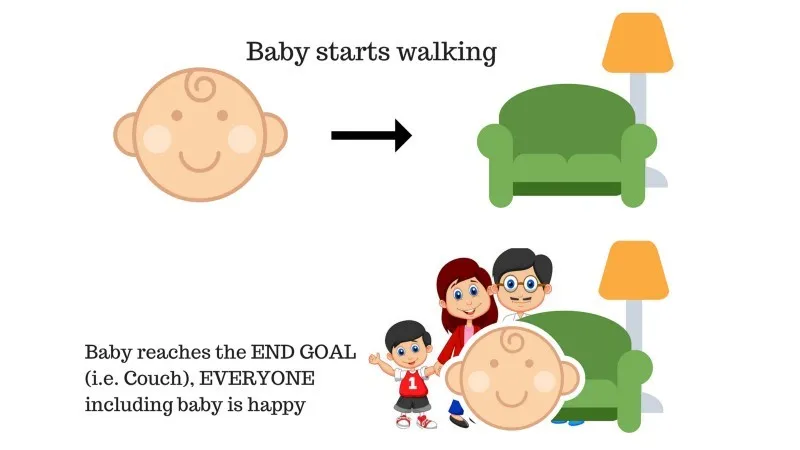
În familie există un copil și tocmai a început să meargă și toată lumea este destul de fericită. Într-o zi, părinții încearcă să își stabilească un obiectiv, lăsați-ne să ajungem pe canapea și să vedem dacă copilul este capabil să facă acest lucru.
Rezultatul cazului 1: Bebelușul ajunge cu succes la canapea și astfel toată lumea din familie este foarte fericită să vadă acest lucru. Calea aleasă vine acum cu o recompensă pozitivă.
Puncte: Recompense + (+ n) → Recompensă pozitivă.
Sursa: https://images.app.goo.gl/pGCXJ1N1bzLAer126
Cazul nr. 2
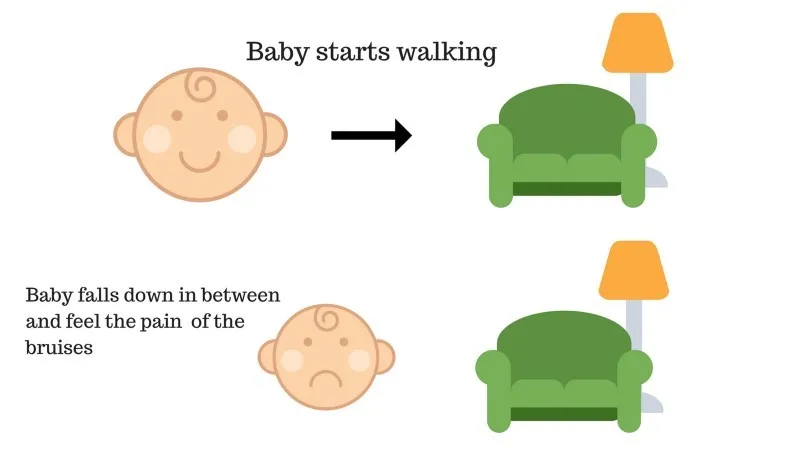
Copilul nu a putut să ajungă pe canapea și copilul a căzut. Doare! Care ar putea fi motivul? S-ar putea să existe unele obstacole în calea către canapea și copilul a căzut în obstacole.
Rezultatul cazului 2: Copilul cade la unele obstacole și plânge! A fost rău, a învățat ea, să nu cadă în capcana obstacolului data viitoare. Calea aleasă vine acum cu o recompensă negativă.
Puncte: Recompense + (-n) → Recompensa negativă.
Sursa: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Acum, am văzut cazurile 1 și 2, învățarea de consolidare, în concept, face același lucru, cu excepția faptului că nu este uman, ci în schimb, efectuat în mod computerizat.
Folosirea armăturii în trepte
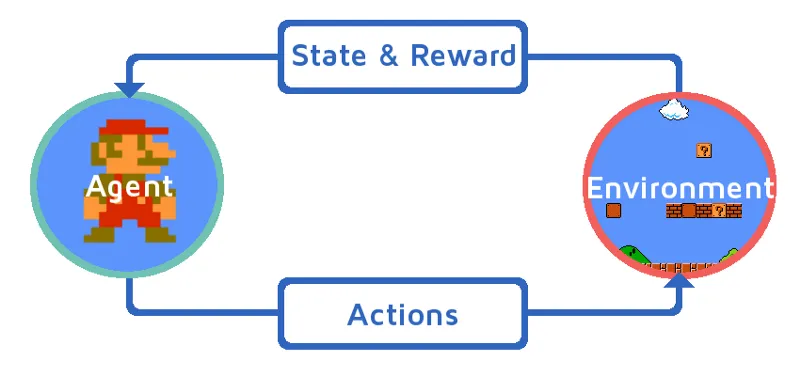
Să înțelegem învățarea consolidării prin aducerea unui agent de armare într-o manieră pasală. În acest exemplu, agentul nostru de învățare pentru consolidare este Mario, care va învăța să joace singur:
Sursa: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Starea actuală a mediului de joc Mario este S_0. Pentru că jocul nu a început încă și Mario este la locul său.
- În continuare, jocul este început și Mario se mișcă, agentul Mario adică RL ia și acționează, să zicem A_0.
- Acum, starea mediului de joc a devenit S_1.
- De asemenea, agentul RL, adică Mario este acum atribuit cu un punct de recompensă pozitiv, R_1, probabil pentru că Mario este încă în viață și nu a existat niciun pericol.
Acum bucla de mai sus va continua să funcționeze până când Mario va fi în sfârșit mort sau Mario va ajunge la destinație. Acest model va produce continuu acțiunea, recompensarea și starea.
Recompense de maximizare
Scopul învățării de consolidare este de a maximiza recompensele, luând în considerare anumiți factori, cum ar fi reducerea recompenselor; vom explica în scurt timp ce se înțelege prin reducere cu ajutorul unei ilustrații.
Formula cumulativă pentru recompense reduse este următoarea:
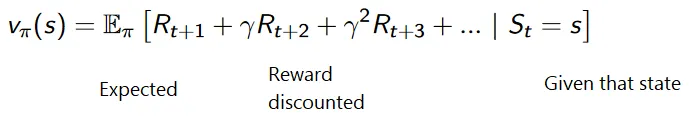
Recompense de reducere
Să înțelegem acest lucru printr-un exemplu:
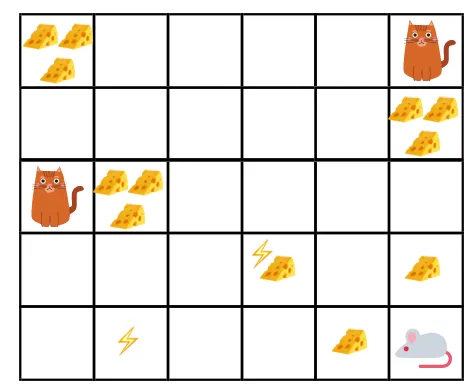
- În figura dată, obiectivul este că mouse-ul din joc trebuie să mănânce cât mai multă brânză înainte de a fi mâncat de o pisică sau fără a fi electrosocat.
- Acum, putem presupune că, cu cât suntem mai apropiați de pisică sau capcana electrică, cu atât este mai mare probabilitatea să permitem ca șoarecele să fie mâncat sau șocat.
- Acest lucru implică, chiar dacă avem brânza completă lângă blocul de electrocutare sau lângă pisică, cu cât este mai riscant să mergem acolo, este mai bine să mâncați brânza care se află în apropiere pentru a evita orice risc.
- Deci, deși, avem un „bloc1” de brânză care este plin și este departe de pisică și blocul de șoc electric, iar celălalt „bloc2”, care este plin, dar este aproape de pisică sau blocul de șoc electric, blocul de brânză de mai târziu, adică „bloc2” va fi mai redus în recompense decât cel precedent.
Sursa: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Sursa: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Tipuri de învățare de armare
Mai jos sunt prezentate cele două tipuri de învățare la armare, cu avantajele și dezavantajele lor:
1. pozitiv
Atunci când rezistența și frecvența comportamentului sunt crescute din cauza apariției unui anumit comportament, este cunoscută sub denumirea de Învățare pozitivă de consolidare.
Avantaje: Performanța este maximizată, iar schimbarea rămâne mai mult timp.
Dezavantaje: Rezultatele pot fi diminuate dacă avem o întărire prea mare.
2. Negativ
Este întărirea comportamentului, mai ales din cauza dispariției termenului negativ.
Avantaje: Comportamentul este crescut.
Dezavantaje: Doar comportamentul minim al modelului poate fi atins cu ajutorul învățării cu întărire negativă.
Unde ar trebui să se folosească învățarea de consolidare?
Lucruri care pot fi realizate cu învățare / exemple de consolidare. Următoarele sunt domeniile în care învățarea de consolidare este folosită în aceste zile:
- Sănătate
- Educaţie
- Jocuri
- Vizionarea computerului
- Managementul afacerilor
- robotică
- Finanţa
- PNL (prelucrarea limbajului natural)
- Transport
- Energie
Cariere în învățare de consolidare
Există într-adevăr un raport de pe site-ul de locuri de muncă, întrucât RL este o ramură a Învățării automate, conform raportului, Machine Learning este cea mai bună treabă din 2019. Mai jos este o imagine a raportului. Conform tendințelor actuale, un Inginerie de învățare în mașini vine cu un salariu minunat de 146.085 USD și cu o rată de creștere de 344 la sută.
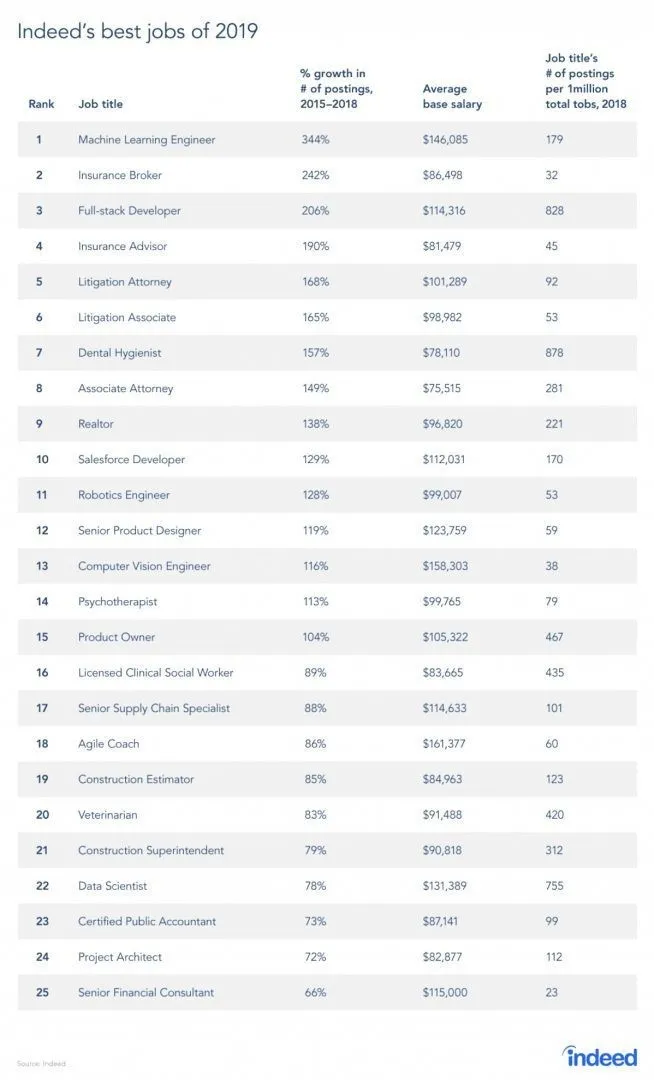
Sursa: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Aptitudini pentru învățare de consolidare
Mai jos sunt abilitățile necesare pentru învățarea de consolidare:
1. Aptitudini de bază
- Probabilitate
- Statistici
- Modelarea datelor
2. Aptitudini de programare
- Bazele programării și informaticii
- Proiectare software
- Capabil să aplice biblioteci și algoritmi de învățare automată
3. Limba de programare a învățării automate
- Piton
- R
- Deși există și alte limbi în care modelele de învățare automată pot fi proiectate precum Java, C / C ++, dar Python și R sunt cele mai preferate limbi utilizate.
Concluzie
În acest articol, am început cu o scurtă introducere despre învățarea prin consolidare și apoi ne-am aprofundat în modul de lucru al RL și diverși factori care sunt implicați în lucrarea modelelor RL. Apoi am pus câteva exemple din lumea reală pentru a înțelege și mai bine despre subiect. Până la sfârșitul acestui articol, cineva ar trebui să înțeleagă bine modul de lucru al învățării de consolidare.
Articole recomandate
Acesta este un ghid pentru Ce este învățarea de consolidare ?. Aici discutăm funcția și diverșii factori implicați în dezvoltarea modelelor de învățare la armare, cu exemple. Puteți parcurge și alte articole conexe pentru a afla mai multe -
- Tipuri de algoritmi de învățare a mașinilor
- Introducere în inteligența artificială
- Instrumente de inteligență artificială
- Platforma IoT
- Top 6 Limbi de programare pentru învățarea mașinii