

Introducere la întrebările și răspunsul la interviu RDBMS
Deci, dacă vă pregătiți pentru un interviu de muncă în RDBMS. Sunt sigur că doriți să cunoașteți cele mai obișnuite întrebări și răspunsuri la interviu RDBMS din 2019 care vă vor ajuta să spargeți cu ușurință Interviul RDBMS. Mai jos este lista cu cele mai bune întrebări și răspunsuri la interviu RDBMS la salvarea dvs.
Prin urmare, avem tendința să adăugăm cele mai bune întrebări pentru interviu RDBMS din 2019, care sunt adresate mai ales într-un interviu
1.Care sunt diferitele caracteristici ale unui RDBMS?
Răspuns:
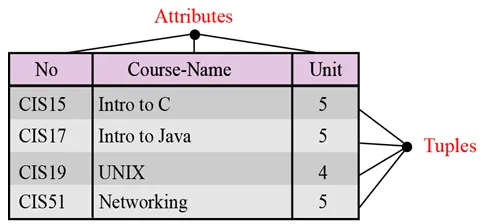
Nume. Fiecare relație dintr-o bază de date relațională ar trebui să aibă un nume care este unic între toate celelalte relații.
Atribute. Fiecare coloană dintr-o relație se numește atribut.
Tupluri. Fiecare rând dintr-o relație se numește tuple. Un tuple definește o colecție de valori de atribut.
2. Explicați modelul ER?
Răspuns:
Modelul ER este un model de entitate-relație. Modelul ER se bazează pe o lume reală care este formată din entități și obiecte de relație. Entitățile sunt ilustrate într-o bază de date printr-un set de atribute.
3.Define modelul orientat pe obiecte?
Răspuns:
Modelul orientat pe obiecte se bazează pe colecții de obiecte. Un obiect găzduiește valori stocate în variabile de instanță în interiorul obiectului. Obiectele care au un tip identic de valori și exact aceleași metode sunt grupate în clase.
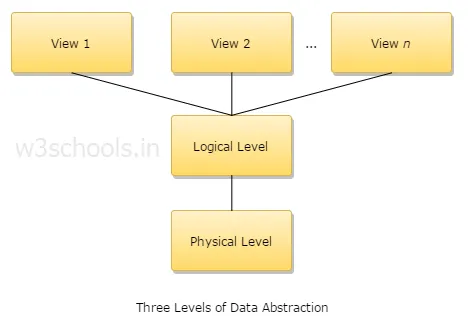
4. Explicați trei niveluri de extragere a datelor?
Răspuns:
1. Nivel fizic: Acesta este cel mai scăzut nivel de abstractizare și descrie modul în care datele sunt stocate.
2. Nivel logic: Următorul nivel de abstractizare este logic, descrie ce tip de date sunt stocate într-o bază de date și care este relația dintre aceste date.
3. View level: Cel mai înalt nivel de abstractizare și descrie singura bază de date întreagă.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Care sunt diferitele 12 reguli Codd pentru baza de date relațională?
Răspuns:
Cele 12 reguli ale Codd sunt un set de treisprezece reguli (de la zero la doisprezece) propuse de Edgar F. Codd.
Regulile Codd: -
Regula 0: Sistemul trebuie să se califice drept relațional, ca bază de date și, de asemenea, ca sistem de management.
Regula 1: Regula informațiilor: Fiecare informație din baza de date trebuie să fie reprezentată în mod unic, în principal valorile de nume în pozițiile coloanelor dintr-un rând diferit al unui tabel.
Regula 2: Regula de acces garantată: Toate datele trebuie să fie ingresive. Se spune că fiecare valoare scalară din baza de date trebuie să fie corectă / logică.
Regula 3: Tratamentul sistematic al valorilor nule: SGBD trebuie să permită fiecărui tuple să rămână nule.
Regula 4: Catalog online activ (structura bazei de date) bazată pe modelul relațional: Sistemul trebuie să susțină o structură online, relațională etc., care este ingresivă pentru utilizatorii autorizați prin interogarea lor obișnuită.
Regula 5: Sub-limbajul complet al datelor: Sistemul trebuie să asiste cel puțin un limbaj relațional care:
1. Are o sintaxă liniară
2.Care poate fi utilizat atât interactiv cât și în cadrul programelor de aplicații,
3.Se acceptă operațiuni de definire a datelor (DDL), operații de manipulare a datelor (DML), restricții de securitate și integritate și operațiuni de gestionare a tranzacțiilor (începe, comite și rollback).
Regula 6: Regula de actualizare a vizualizării: Toate sistemele de îmbunătățiri teoretice trebuie să fie actualizate de către sistem.
Regula 7: Introducerea, actualizarea și ștergerea la nivel înalt: Sistemul trebuie să suporte operatorii de introducere, actualizare și ștergere.
Regula 8: Independența datelor fizice: Modificați nivelul fizic (modul în care datele sunt stocate, folosind tablouri sau liste legate, etc.) nu trebuie să necesite o modificare a unei aplicații.
Regula 9: Independența datelor logice: Modificați nivelul logic (tabele, coloane, rânduri etc.) nu trebuie să necesite o modificare a unei aplicații.
Regula 10: Independența integrității: Restricțiile de integritate trebuie identificate individual din programele de aplicații și stocate în catalog.
Regula 11: Independența distribuției : Distribuția porțiunilor unei baze de date în diferite locații nu trebuie să fie vizibilă pentru utilizatorii bazei de date.
Regula 12: Regula de nonsubversie: Dacă sistemul oferă o interfață de nivel scăzut (adică înregistrări), acea interfață nu poate fi utilizată pentru a subverti sistemul.
6.Care este normalizarea? și ce explică diferite forme de normalizare.
Răspuns:
Normalizarea bazei de date este un proces de organizare a datelor pentru a minimiza redundanța datelor. Care la rândul său asigură coerența datelor. Există multe probleme asociate cu redundanța de date, cum ar fi risipa de spațiu pe disc, inconsistența datelor, interogările DML (Data Manipulation Language) devin lente. Există diferite forme de normalizare: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Datele din fiecare coloană trebuie să aibă un număr atomic de valori multiple, separate printr-o virgulă. Tabelul nu conține grupuri de coloane care se repetă. Identificați fiecare înregistrare folosind cheia principală.
2. 2NF: - Tabelul trebuie să corespundă tuturor condițiilor de 1NF și să mute datele redundante într-un tabel separat. Mai mult, creează o relație între aceste tabele cu ajutorul cheilor străine.
3. 3NF: - pentru un tabel 3NF ar trebui să îndeplinească toate condițiile de la 1NF și 2NF. 3NF nu conține atribute care depind parțial de cheia primară.
7. Definiți cheia primară, cheie străină, cheie de candidat, super cheie?
Răspuns:
Cheie primară: cheia primară este cheia care nu permite duplicarea valorilor și a valorilor nule. O cheie primară poate fi definită la nivel de coloană sau la nivel de tabel. Este permisă o singură cheie primară pe tabelă.
Cheie externă : cheia străină permite doar valorile prezente în coloana referită. Permite valori duplicate sau nule. Poate fi definit ca nivel de coloană sau nivel de tabel. Poate face referire la o coloană cu o cheie unică / primară.
Cheia candidatului: o cheie Candidat este super-cheie minimă, nu există un subgrupo corespunzător de atribute ale cheii Candidate care poate fi o cheie super.
Super cheie: o superkey este un set de atribute ale unei scheme de relații de care toate atributele schemei depind parțial. Niciun rând de două rânduri nu poate avea aceeași valoare a atributelor super-cheie.
8.Care este un tip diferit de indici?
Răspuns:
Indexurile sunt: -
Index indexat - Este indicele la care datele sunt stocate fizic pe disc. Prin urmare, un singur indice grupat poate fi creat într-o tabelă de baze de date.
Indice neaglomerat: - Nu definește date fizice, dar definește o comandă logică. De obicei, B-Tree sau B + tree sunt create în acest scop.
9. Care sunt avantajele RDBMS?
Răspuns:
• Controlul redundanței.
• Integritatea poate fi aplicată.
• Incoerența poate fi evitată.
• Datele pot fi partajate.
• Standardul poate fi aplicat.
10. Numește unele subsisteme ale RDBMS?
Răspuns:
Intrare-ieșire, Securitate, Prelucrare limbă, Management stocare, Logare și recuperare, Control distribuție, Control tranzacții, Gestionare memorie.
11.Care este Buffer Manager?
Răspuns:
Buffer Manager reușește să colecteze date de la stocarea discului în memoria principală și decide ce date să fie în memoria cache pentru o procesare mai rapidă.
Articol recomandat
Acesta a fost un ghid la Lista întrebărilor și răspunsurilor la interviu RDBMS, astfel încât candidatul să poată împărți cu ușurință aceste întrebări de interviu RDBMS. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Cele mai importante întrebări de interviu pentru analiza datelor
- 13 Uimitoare Baza de date Testing Interviu Întrebări și răspuns
- Top 10 Întrebări și răspunsuri la interviu de design
- 5 întrebări utile și răspuns la interviu SSIS