
Introducere în Hive Group By
Group By după cum sugerează și numele, acesta va grupa înregistrarea care îndeplinește anumite criterii. În acest articol, vom privi grupul prin HIVE. În RDBMS moștenitor, cum ar fi MySQL, SQL, etc, gruparea este una dintre cele mai vechi clauze care sunt utilizate. Acum și-a găsit locul într-un mod similar în stocarea de date bazată pe fișiere cunoscute drept HIVE.
Știm că Hive a depășit multe RDBMS vechi în gestionarea de date uriașe, fără ca un ban să fie cheltuit pentru furnizori pentru a menține bazele de date și serverele. Trebuie doar să configurăm HDFS pentru a gestiona stupul. În general, trecem la tabele, deoarece utilizatorul final poate interpreta din structura sa și poate interoga deoarece fișierele vor fi stângace pentru ele. Dar a trebuit să facem acest lucru plătind furnizorilor să furnizeze servere și să mențină datele noastre în format de tabele. Așadar, Hive oferă un mecanism rentabil în cazul în care profită de sistemele bazate pe fișiere (modul în care stupul își salvează datele), precum și de tabele (structura tabelului pentru care utilizatorii finali să se intereseze).
A se grupa cu
Grupați utilizează coloanele definite din tabelul Hive pentru a grupa datele. Cum ar fi, consideră că ai un tabel cu datele recensământului din fiecare oraș din toate statele în care numele orașului și numele statului sunt una dintre coloane. Acum, în interogare, dacă grupăm după state, atunci toate datele din diferite orașe ale unui anumit stat vor fi grupate și se pot vizualiza mai ușor datele mai bine acum înainte de modul în care grupul a fost aplicat.
Sintaxa Hive Group By
Sintaxa generală a grupului după clauză este următoarea:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
sau pentru întrebări mai simple,
from Group By
Select department, count(*) from the university.college Group By department;
Aici departamentul se referă la una din coloanele tabelului colegiului, care este prezent în baza de date a universității, iar valoarea sa este diferită în departamente precum arte, matematică, inginerie, etc. Acum să vedem un exemplu pentru a demonstra grupul.
Am creat un exemplu de tabel deck_of_cards pentru a demonstra grupul prin. Instrucțiunea sa de creare a tabelului este următoarea:
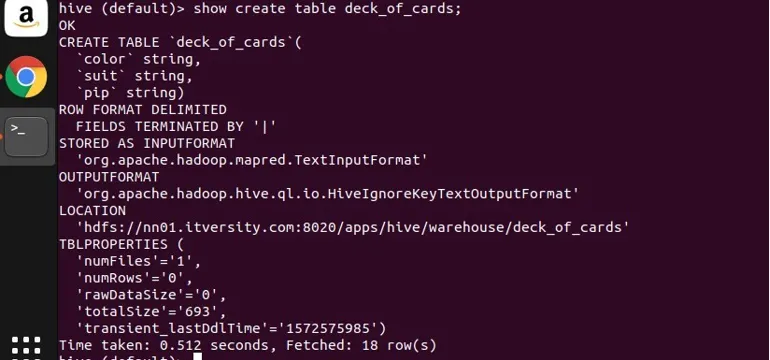
puteți vedea, de sus, că are trei coloane de culoare șir, costum și pip. Permiteți-mi să scriu o interogare pentru a grupa datele după culoarea lor și pentru a obține numărul acestora.
select color, count(*) from deck_of_cards group by color;
Practic, Hive ia interogarea de mai sus pentru a o converti în programul de reducere a hărții prin generarea codului java corespunzător și a fișierului jar și apoi se execută. Acest proces poate dura un pic de timp, dar poate trata cu siguranță datele mari în comparație cu RDBMS tradițional. Consultați imaginea de mai jos cu jurnalul detaliat pentru a executa interogarea de mai sus.
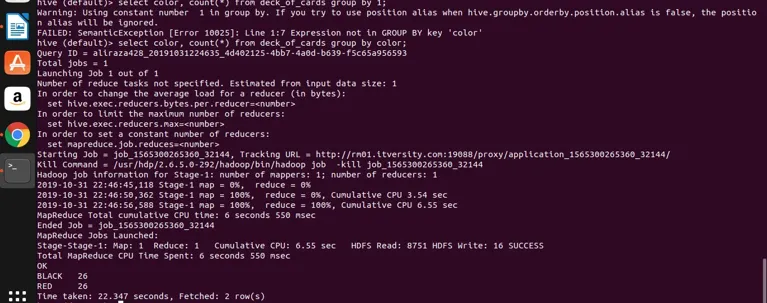
puteți vedea că BLACK este 26 și RED este 26.
acum să aplicăm gruparea pe două coloane (culoare și costum și obținerea numărului de grupuri) și să vedem rezultatul de mai jos.
Select color, suit, count(*) from deck_of_cards group by color, suit
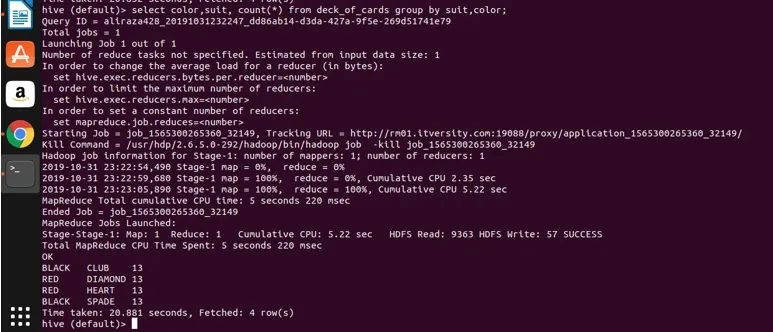
Practic, există patru grupuri distincte deasupra Clubului, Spade care au culoarea negru și Diamantul și inima care sunt de culoare roșie.
Stocarea rezultatului din grup după cauză într-un alt tabel
De asemenea, stupul ca orice alt RDBMS oferă funcția de inserare a datelor cu instrucțiuni create în tabel. Să ne uităm la stocarea rezultatului dintr-o expresie selectă folosind un grup în alt tabel. Permiteți-mi să folosesc însuși interogarea de mai sus unde am folosit două coloane în grup.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
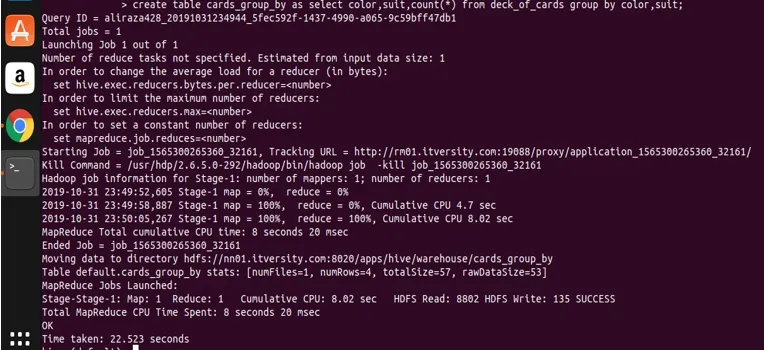
acum să ne întrebăm pe tabelul creat pentru a vedea și valida datele.

Acum să restrângem rezultatul grupului prin utilizarea clauzei. Așa cum este arătat în sintaxa generică, putem aplica restricție asupra grupului, folosind. Aici folosesc tabela ordser_items, iar structura sa este următoarea din instrucțiunea descriere.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
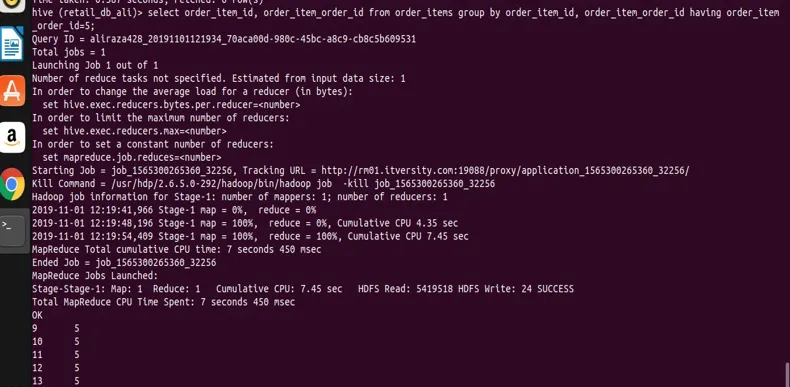
puteți vedea din rezultatul ecranului că avem înregistrări doar cu valoarea de ordine_item_order_id 5.
Grupați împreună cu declarația de caz
Să ne uităm acum la întrebări complexe care implică declarațiile CASE cu grupul. Vom aplica acest lucru în tabelul order_items. Vom vedea mai jos că putem clasifica coloanele neagregate pe care nu putem aplica grupul prin clauză direct.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
hai să-l executăm în stup pentru rezultate
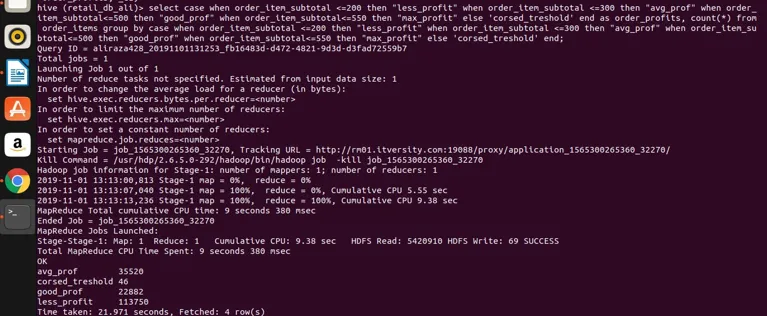
Concluzie - Hive Group By
deci putem vedea că am grupat ordinea_item_subtotală în patru categorii diferite (dacă observați că ordinul_item_subtotal este o coloană neagregantă și un grup direct nu poate fi aplicat la ea) și le-am grupat și le-am obținut și conturile pentru valorile care satisfac intervalul definit în expresia selectă. Aici regula simplă în cazul în care coloana este neagregantă și expresia noastră selectă este complexă, atunci orice există în expresia selectă care ar trebui să fie, de asemenea, prezentă în grup prin expresia clauzei. Prin urmare, am văzut cum o faimoasă clauză grupul de clauze RDBMS poate fi de asemenea aplicată pe stup fără nicio restricție. Poate fi aplicat expresiilor simple de selectare. Agregă și filtrează expresiile, alătură și expresiile și expresiile CASE complexe.
Articole recomandate
Acesta este un ghid pentru Hive Group By. Aici discutăm grupul prin, sintaxă, exemple ale grupului stupi, cu condiții și implementare diferite. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Se alătură în stup
- Ce este un stup?
- Arhitectura stupului
- Funcția stupului
- Ordinul stupului Prin
- Instalarea stupului
- Top 6 tipuri de uniri în MySQL cu exemple