

Introducere în Metodele Kernel
Metodele de kernel sau kernel (numite și funcții Kernel) sunt seturi de diferite tipuri de algoritmi care sunt folosiți pentru analiza modelului. Acestea sunt utilizate pentru a rezolva o problemă neliniară folosind un clasificator liniar. Metodele de sâmbure sunt folosite în SVM (Support Vector Machines) care sunt utilizate în problemele de clasificare și regresie. SVM folosește ceea ce se numește „Kernel Trick” unde datele sunt transformate și se găsește o limită optimă pentru ieșirile posibile.
Nevoia metodei de sâmbure și funcționarea ei
Înainte de a intra în funcționarea Metodelor Kernel, este mai important să înțelegem mașini vectoriale de suport sau SVM-uri, deoarece kernelurile sunt implementate în modele SVM. Așadar, mașinile Vector Support sunt algoritmi de învățare a mașinilor supravegheate, care sunt utilizate în problemele de clasificare și regresie, cum ar fi clasificarea unui măr în fructe de clasă, în timp ce clasificarea unui Leu la animalul clasei.
Pentru a demonstra, mai jos este cum arată mașinile vector de suport:
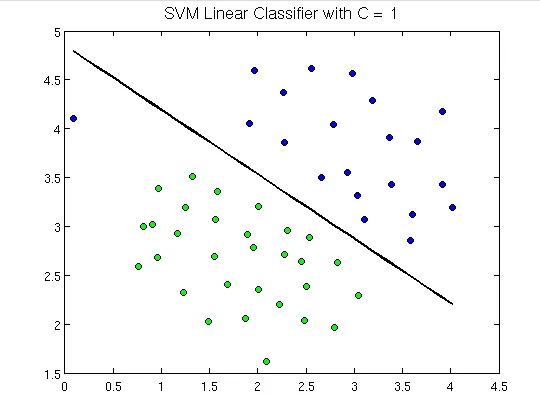
Aici putem vedea un hiperplan care separă punctele verzi de cele albastre. Un hiperplan este cu o dimensiune mai mică decât planul ambiental. De exemplu, în figura de mai sus, avem 2 dimensiuni care reprezintă spațiul ambiental, dar singurul care împarte sau clasifică spațiul este cu o dimensiune mai mică decât spațiul ambiant și se numește hiperplan.
Dar dacă avem inputuri astfel:
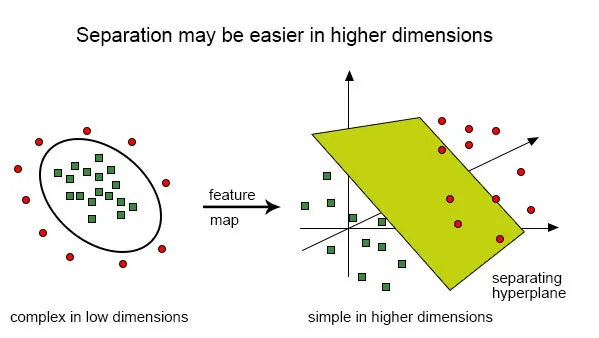
Este foarte dificil să rezolvi această clasificare folosind un clasificator liniar, deoarece nu există o linie liniară bună care să poată clasifica punctele roșii și verzi, deoarece punctele sunt distribuite aleatoriu. Aici intervine utilizarea funcției de kernel care duce punctele la dimensiuni mai mari, rezolvă problema de acolo și returnează ieșirea. Gândiți-vă la acest lucru, putem vedea că punctele verzi sunt închise într-o zonă perimetrală, în timp ce cea roșie se află în afara acesteia, de asemenea, ar putea exista și alte scenarii în care punctele verzi să fie distribuite într-o zonă în formă de trapez.
Deci, ceea ce facem este să convertim planul bidimensional care a fost clasificat pentru prima oară de un hiperplan unidimensional („sau o linie dreaptă”) în zona tridimensională și aici clasificatorul nostru, adică hiperplanul nu va fi o linie dreaptă, ci două -un plan dimensional care va tăia zona.
Pentru a obține o înțelegere matematică a nucleului, să înțelegem ecuația lui Lili Jiang a nucleului care este:
K (x, y) = unde,
K este funcția de sâmbure,
X și Y sunt intrările dimensionale,
f este harta de la n-dimensional la spațiul dimensional m și,
este produsul dot.
Ilustrați cu ajutorul unui exemplu.
Să spunem că avem două puncte, x = (2, 3, 4) și y = (3, 4, 5)
După cum am văzut, K (x, y) =.
Să calculăm mai întâi
f (x) = (x1x1, x1x2, x1x3, x2x1, x2x2, x2x3, x3x1, x3x2, x3x3)
f (y) = (y1y1, y1y2, y1y3, y2y1, y2y2, y2y3, y3y1, y3y2, y3y3)
asa de,
f (2, 3, 4) = (4, 6, 8, 6, 9, 12, 8, 12, 16) și
f (3, 4, 5) = (9, 12, 15, 12, 16, 20, 15, 20, 25)
deci produsul punct,
f (x). f (y) = f (2, 3, 4). f (3, 4, 5) =
(36 + 72 + 120 + 72 +144 + 240 + 120 + 240 + 400) =
1444
Și,
K (x, y) = (2 * 3 + 3 * 4 + 4 * 5) 2 = (6 + 12 + 20) 2 = 38 * 38 = 1444.
Așa cum aflăm, f (x) .f (y) și K (x, y) ne dau același rezultat, dar metoda anterioară a necesitat o mulțime de calcule (din cauza proiectării a 3 dimensiuni în 9 dimensiuni) în timp ce folosim sâmbure, a fost mult mai ușor.
Tipuri de kernel și metode în SVM
Să vedem unele funcții ale kernelului sau tipurile care sunt utilizate în SVM:
1. Linie de linie - Să spunem că avem doi vectori cu numele x1 și Y1, atunci nucleul liniar este definit prin produsul punct al acestor doi vectori:
K (x1, x2) = x1. x2
2. Nucleul polinomial - Un nucleu polinomial este definit prin următoarea ecuație:
K (x1, x2) = (x1. X2 + 1) d,
Unde,
d este gradul polinomului și x1 și x2 sunt vectori
3. Nucleul Gaussian - Acest nucleu este un exemplu de nucleu cu funcție de bază radială. Mai jos este ecuația pentru acest lucru:
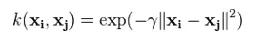
Sigma dată joacă un rol foarte important în performanța sâmburelui Gaussian și nu trebuie nici supraestimată și nici subestimată, trebuie să fie atent ajustată în funcție de problemă.
4. Nucleul exponențial - Acesta este în strânsă relație cu nucleul anterior, adică nucleul Gaussian cu singura diferență este - pătratul normei este eliminat.
Funcția funcției exponențiale este:
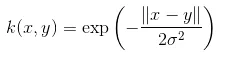
Aceasta este, de asemenea, o funcție de bază a nucleului radial.
5. Nucleul laplacian - Acest tip de sâmbure este mai puțin predispus la schimbări și este total egal cu nucleul funcțional exponențial discutat anterior, ecuația nucleului laplacian este dată ca:
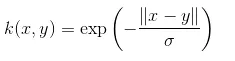
6. Nucleul hiperbolic sau sigmoid - Acest nucleu este utilizat în zonele rețelei neuronale ale învățării automate. Funcția de activare a sâmburelui sigmoid este funcția sigmoidă bipolară. Ecuația funcției nucleului hiperbolic este:
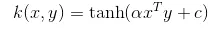
Acest nucleu este foarte utilizat și popular în rândul mașinilor de susținere.
7. Nucleul de bază radială Anova - Se cunoaște că acest nucleu funcționează foarte bine în problemele de regresie multidimensională, la fel ca sâmburele Gauss și Laplațian. Aceasta intră și în categoria nucleului de bază radială.
Ecuația pentru nucleul Anova este:
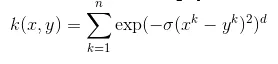
Există mult mai multe tipuri de metode de sâmbure și am discutat despre cele mai utilizate nuclee. Aceasta depinde pur și simplu de tipul de problemă care va decide funcția de sâmbure a fi folosită.
Concluzie
În această secțiune, am văzut definiția nucleului și cum funcționează. Am încercat să explicăm cu ajutorul unor diagrame despre funcționarea sâmburilor. Am încercat apoi să dăm o ilustrare simplă folosind matematica despre funcția nucleului. În partea finală, am văzut diferite tipuri de funcții ale kernel-ului care sunt utilizate pe scară largă astăzi.
Articole recomandate
Acesta este un ghid al Metodelor Kernel. Aici vom discuta despre o introducere, nevoie, este de lucru și tipuri de metode de kernel cu ecuația adecvată. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Algoritmi de extragere a datelor
- K- Înseamnă algoritmul de clustering
- Algoritmul forței brute
- Algoritmul arborelui decizional
- Metode de nucleu în învățarea mașinii
- Arborele decizional în învățarea mașinilor