
Prezentare generală a modelării regresiei liniare
Când începeți să aflați despre algoritmii de învățare automată, începeți să aflați despre diverse modalități de algoritmi ML, adică învățare supravegheată, nesupravegheată, semi-supravegheată și de consolidare. În acest articol, ne vom ocupa de învățarea supravegheată și unul dintre algoritmii de bază, dar puternici: Regresia liniară.

Prin urmare, învățarea supravegheată este învățarea în care antrenăm mașina pentru a înțelege relația dintre valorile de intrare și de ieșire furnizate în setul de date de instruire și apoi utilizăm același model pentru a prezice valorile de ieșire pentru setul de date de testare. Deci, practic, dacă avem deja produsul sau etichetarea furnizate în setul nostru de date de formare și suntem siguri că rezultatele furnizate au sens corespunzător intrării, atunci folosim Învățare supravegheată. Algoritmii de învățare supervizați sunt clasificați în regresie și clasificare.
Algoritmii de regresie sunt folosiți atunci când observați că ieșirea este o variabilă continuă, în timp ce algoritmii de clasificare sunt folosiți atunci când ieșirea este împărțită în secțiuni cum ar fi Trecerea / Eșecul, Bunul / Media / Răul, etc. Avem diferiți algoritmi pentru efectuarea regresiei sau clasificării acțiunile cu algoritmul de regresie liniară fiind algoritmul de bază în regresie.
Ajungând la această regresie, înainte de a intra în algoritm, permiteți-mi să stabilesc baza pentru voi. În școală, sper să vă amintiți conceptul de ecuație de linie. Permiteți-mi să dau un scurt despre asta. Vi s-au dat două puncte pe planul XY, adică say (x1, y1) și (x2, y2), unde y1 este ieșirea x1 și y2 fiind ieșirea x2, atunci ecuația de linie care trece prin puncte este (y- y1) = m (x-x1) unde m este panta liniei. Acum, după găsirea ecuației de linie, dacă vi se oferă un punct de spus (x3, y3), atunci puteți fi ușor să puteți prezice dacă punctul se află pe linie sau distanța punctului de la linie. Aceasta a fost regresia de bază pe care am făcut-o în școală fără să-mi dau seama chiar că aceasta ar avea o importanță atât de mare în învățarea mașinii. Ceea ce facem în general în acest sens este să încercăm să identificăm linia sau curba de ecuație care ar putea să se potrivească corect la intrarea și la ieșirea setului de date ale trenului și apoi să utilizăm aceeași ecuație pentru a prezice valoarea de ieșire a setului de date de testare. Aceasta ar avea ca rezultat o valoare dorită continuă.
Definiția Linear Regression
Regresia liniară este de fapt în jur de foarte mult timp (în jur de 200 de ani). Este un model liniar, adică presupune o relație liniară între variabilele de intrare (x) și o singură variabilă de ieșire (y). Y aici se calculează prin combinația liniară a variabilelor de intrare.
Avem două tipuri de regresie liniară
Regresie liniară simplă
Când există o singură variabilă de intrare, adică ecuația de linie este c
considerată ca y = mx + c, atunci este regresie liniară simplă.
Regresie liniară multiplă
Când există mai multe variabile de intrare, adică ecuația de linie este considerată y = ax 1 + bx 2 + … nx n, atunci este regresie liniară multiplă. Se folosesc diverse tehnici pentru pregătirea sau antrenarea ecuației de regresie din date, iar cea mai comună dintre ele este numită pătrățele ordinare. Modelul construit folosind metoda menționată este denumit regresie liniară pătrată minimă sau doar regresie minimă. Modelul este utilizat atunci când valorile de intrare și valoarea de ieșire care urmează să fie determinate sunt valori numerice. Când există o singură intrare și o singură ieșire, ecuația formată este o ecuație liniară, adică
y = B0x+B1
unde se vor determina coeficienții liniei folosind metode statistice.
Modelele de regresie liniară simplă sunt foarte rare în ML, deoarece, în general, vom avea diverși factori de intrare pentru a determina rezultatul. Când există mai multe valori de intrare și o valoare de ieșire, ecuația formată este cea a unui plan sau a unui hiperplan.
y = ax 1 +bx 2 +…nx n
Ideea de bază în modelul de regresie este de a obține o ecuație de linie care se potrivește cel mai bine datelor. Cea mai potrivită linie este cea în care eroarea de predicție totală pentru toate punctele de date este considerată cât mai mică posibil. Eroarea este distanța dintre punctul de pe plan și linia de regresie.
Exemplu
Să începem cu un exemplu de regresie liniară simplă.

Relația dintre înălțimea și greutatea unei persoane este direct proporțională. Un studiu a fost efectuat pe voluntari pentru a determina înălțimea și greutatea ideală a persoanei și valorile au fost înregistrate. Acest lucru va fi considerat setul nostru de date de formare. Folosind datele de antrenament, se calculează o ecuație a liniei de regresie care va produce o eroare minimă. Această ecuație liniară este apoi utilizată pentru a face predicții pe date noi. Adică dacă dăm înălțimea persoanei, atunci greutatea corespunzătoare ar trebui să fie prezisă de modelul dezvoltat de noi cu eroare minimă sau zero.
Y(pred) = b0 + b1*x
Valorile b0 și b1 trebuie alese astfel încât să reducă la minimum eroarea. Dacă suma erorii pătrate este luată ca o măsurătoare pentru a evalua modelul, atunci obiectivul de a obține o linie care să reducă cel mai bine eroarea.
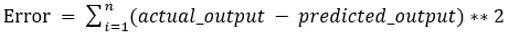
Reducem eroarea astfel încât valorile pozitive și negative să nu se anuleze reciproc. Pentru model cu un predictor:
Calculul interceptului (b0) în ecuația de linie se face prin:
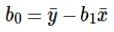
Calculul coeficientului pentru valoarea de intrare x se face prin:
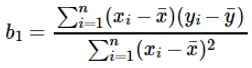
Înțelegerea coeficientului b 1 :
- Dacă b 1 > 0, atunci x (intrare) și y (ieșire) sunt direct proporționale. Aceasta este o creștere a x va crește y cum ar fi creșterea înălțimii, creșterea greutății.
- Dacă b 1 <0, atunci x (predictor) și y (țintă) sunt invers proporționale. Aceasta este o creștere a x va scădea y, cum ar fi viteza unei creșteri a vehiculului, timpul luat scade.
Înțelegerea coeficientului b 0 :
- B 0 preia valoarea reziduală a modelului și se asigură că predicția nu este părtinitoare. Dacă nu avem termenul B 0 atunci ecuația de linie (y = B 1 x) este obligată să treacă prin origine, adică valorile de intrare și ieșire puse în model rezultă în 0. Dar acest lucru nu va fi niciodată cazul, dacă avem 0 la intrare, atunci B 0 va fi media tuturor valorilor preconizate când x = 0. Setarea tuturor valorilor predictorului pe 0 în cazul x = 0 va duce la pierderea datelor și este adesea imposibilă.
În afară de coeficienții menționați mai sus, acest model poate fi calculat și folosind ecuații normale. Voi discuta în continuare despre utilizarea ecuațiilor normale și proiectarea unui model de regresie simplă / multiliniară în articolul meu care urmează.
Articole recomandate
Acesta este un ghid pentru modelarea regresiei liniare. Aici vom discuta definiția, tipurile de regresie liniară care include regresia liniară simplă și multiplă împreună cu unele exemple. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Regresia liniară în R
- Regresie liniară în Excel
- Modelarea predictivă
- Cum se creează GLM în R?
- Comparație de regresie liniară cu regresie logistică