

Introducere în Python Pandas DataFrame
Mai multe extinderi pentru biblioteca Python, Pandas, pot fi găsite online. Unul dintre acestea este Panoul (pan) Date (das). Acest cuvânt, * Panou * indică în mod subtil o structură de date în două dimensiuni, prezentă în această bibliotecă, abilitându-i imens pe utilizatorii săi. Această structură este numită DataFrame.
Este în esență o matrice de rânduri și coloane, care conține întregul set de date, cu opțiuni foarte elaborate de indexare a aceluiași. DataFrame (DF), poate fi imaginat pictoric foarte similar cu o foaie excel. Dar ceea ce îl face puternic este ușurința cu care operațiunile de analiză și transformare pot fi efectuate pe datele stocate într-un DataFrame.
Ce este exact un fișier de date Python Pandas?
Pagina Pydata poate fi trimisă pentru o definiție oficială.
Dacă este înțeles corect, menționează DataFrame ca o structură columnară, capabilă să stocheze orice obiect python (inclusiv un DataFrame în sine) ca o valoare a unei celule. (O celulă este indexată folosind o combinație unică de rânduri și coloane)
DataFrames constă din trei componente esențiale: date, rânduri și coloane.
- Date: se referă la obiectele / entitățile reale stocate într-o celulă în DataFrame și la valorile reprezentate de aceste entități. Un obiect este de orice tip de date piton valabil, fie încorporat, fie definit de utilizator.
- Rânduri: Referințele utilizate pentru a identifica (sau a indexa) un set particular de observații din datele complete stocate într-un DataFrame se numesc rânduri. Doar pentru a clarifica, reprezintă indicii folosiți și nu doar datele dintr-o anumită observație.
- Coloane: Referințe utilizate pentru identificarea (sau indexarea) unui set de atribute pentru toate observațiile dintr-un DataFrame. Ca și în cazul rândurilor, acestea se referă la indexul coloanelor (sau la anteturile coloanelor) în loc de doar datele din coloană.
Așa că, fără mai multe detalii, haideți să încercăm câteva modalități de a crea aceste structuri extraordinar de puternice.
Pași pentru crearea cadrelor de date Python Pandas
Un fișier de date Python Pandas poate fi creat folosind următoarea implementare a codului,
1. Importați panda
Pentru a crea DataFrames, biblioteca pandas trebuie importată (nu este o surpriză aici). Îl vom importa cu un alias pd pentru a face obiecte de referință în mod convenabil.
Cod:
import pandas as pd
2. Crearea primului obiect DataFrame
Odată importată biblioteca, toate metodele, funcțiile și constructorii sunt disponibili în spațiul de lucru. Deci, să încercăm să creăm un DataFrame vanilat.
Cod:
import pandas as pd
df = pd.DataFrame()
print(df)
ieşire:
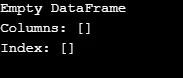
După cum se arată în ieșire, constructorul returnează un DataFrame gol.
Să ne concentrăm acum pe crearea DataFrames din datele stocate în unele dintre reprezentările probabile.
- DataFrame dintr-un dicționar: Să zicem că avem un dicționar care stochează o listă de companii din Domeniul Software și numărul de ani în care au activat.
Cod:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Să vedem reprezentarea obiectului DataFrame returnat prin imprimarea acestuia pe consolă.
ieşire:

După cum se poate vedea, fiecare cheie a dicționarului este tratată ca o coloană din DataFrame, iar indicii rândului sunt generați automat începând cu 0. Destul de ușor, nu!
Acum să zicem că ai vrut să îi dai un index personalizat în loc de 0, 1, .. 4. Trebuie doar să treceți lista dorită ca parametru constructorului și panda va face ce este necesar.
Cod:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
ieşire:
Vârsta companiei
Alpha Google 21
Beta Amazon 23
Infosys Gamma 38
Delta Directi 22
Acum puteți seta indicii de rând la orice valoare dorită.
- DataFrame dintr-un fișier CSV: Să creăm un fișier CSV care conține aceleași date ca în cazul dicționarului nostru. Să apelăm la fișierul CompanyAge.csv
Google, 21
Amazon 23
Infosys, 38
Directi, 22
Fișierul poate fi încărcat într-un cadru de date (presupunând că este prezent în directorul de lucru curent) după cum urmează.
Cod:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
ieşire:
Vârsta companiei
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Setarea numelor parametrilor , ocolind o listă de valori, le atribuie ca antete de coloană în aceeași ordine în care sunt prezente în listă. În mod similar, indicii de rând pot fi setați trecând o listă la parametrul index, așa cum se arată în secțiunea anterioară. Antetul = Nimeni nu indică lipsa anteturilor de coloană din fișierul de date.
Acum să zicem că numele coloanelor făceau parte din fișierul de date. Apoi setarea antetului = False va face treaba necesară.
3. CompanyAgeWithHeader.csv
Companie, Vârsta
Google, 21
Amazon 23
Infosys, 38
Directi, 22
Codul se va schimba la
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
ieşire:
Vârsta companiei
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame dintr-un fișier Excel: Adesea, datele sunt partajate în fișiere excel, deoarece rămân instrumentul cel mai popular folosit de oamenii obișnuiți pentru urmărirea Adhoc. Astfel, discuția noastră nu trebuie ignorată.
Să presupunem că datele, la fel ca în CompanyAgeWithHeader.csv, sunt acum stocate în CompanyAgeWithHeader.xlsx, într-o foaie cu numele Company Age. Același DataFrame ca mai sus va fi creat de următorul cod.
Cod:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
ieşire:
Vârsta companiei
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
După cum puteți vedea, același DataFrame poate fi creat trecând numele fișierului și numele foii.
Citire ulterioară și pașii următori
Metodele prezentate constituie un subset foarte mic în comparație cu toate diferitele moduri în care pot fi create DataFrames. Acestea au fost create cu intenția de a începe unul. Ar trebui să explorați cu siguranță referințele enumerate și să încercați să explorați alte modalități, inclusiv conectarea la o bază de date pentru a citi datele dintr-un DataFrame.
Concluzie
Pandas DataFrame s-a dovedit a fi un schimbător de jocuri în lumea științei datelor și a analizei datelor, precum și este convenabil pentru proiecte ad-hoc pe termen scurt. Vine cu o armată de instrumente capabile să tranșeze și să decupeze setul de date cu ușurință extremă. Sperăm că acest lucru va servi drept un pas în călătoria dvs. înainte.
Articole recomandate
Acesta este un ghid pentru Python-Pandas DataFrame. Aici discutăm pașii pentru crearea cadrului de date python-pandas împreună cu implementarea codului. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Top 15 caracteristici ale Python
- Diferite tipuri de seturi Python
- Top 4 tipuri de variabile în Python
- Top 6 editori ai Python
- Schiri în structura datelor