
Introducere în Regiunea Poisson în R
Regresia Poisson este un tip de regresie care este similară cu regresia liniară multiplă, cu excepția faptului că răspunsul sau variabila dependentă (Y) este o variabilă de număr. Variabila dependentă urmărește distribuția Poisson. Predictorul sau variabilele independente pot fi de natură continuă sau categorice. Într-un fel, este similar cu Regresia logistică, care are și o variabilă de răspuns discret. Înțelegerea prealabilă a distribuției Poisson și a formei sale matematice este foarte esențială pentru a o folosi pentru predicție. În R, regresia Poisson poate fi implementată într-o manieră foarte eficientă. R oferă un set complet de funcționalități pentru implementarea sa.
Implementarea regresiei Poisson
Vom continua acum să înțelegem cum se aplică modelul. Următoarea secțiune oferă o procedură pas cu pas pentru aceeași. Pentru această demonstrație, avem în vedere setul de date „gala” din pachetul „îndepărtat”. Se referă la diversitatea speciilor de pe Insulele Galapagos. Există în total 7 variabile în setul de date. Vom folosi regresia Poisson pentru a defini o relație între numărul de specii de plante (Specie) cu alte variabile din setul de date.
1. Încărcați mai întâi pachetul „îndepărtat”. În caz că pachetul nu este prezent, descărcați-l folosind funcția install.packages ().
2. Odată ce pachetul este încărcat, încărcați setul de date „gala” în R utilizând funcția date () așa cum se arată mai jos.
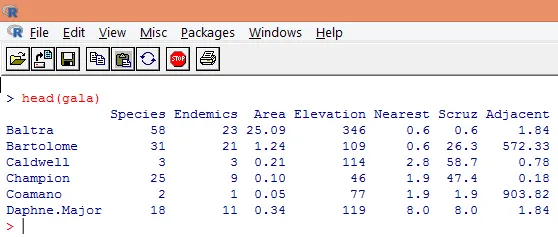
3. Datele încărcate ar trebui vizualizate pentru a studia variabila și pentru a verifica dacă există discrepanțe. Putem vizualiza toate datele sau doar primele rânduri ale acestora folosind funcția head (), așa cum se arată în imaginea de mai jos.
4. Pentru a afla mai multe detalii asupra setului de date, putem folosi funcționalitatea de ajutor în R, ca mai jos. Acesta generează documentația R așa cum se arată în imaginea de fundal ulterioară imaginii de mai jos.


5. Dacă studiem setul de date așa cum este menționat în etapele precedente, atunci putem constata că Specia este o variabilă de răspuns. Vom studia acum un rezumat de bază al variabilelor predictor.
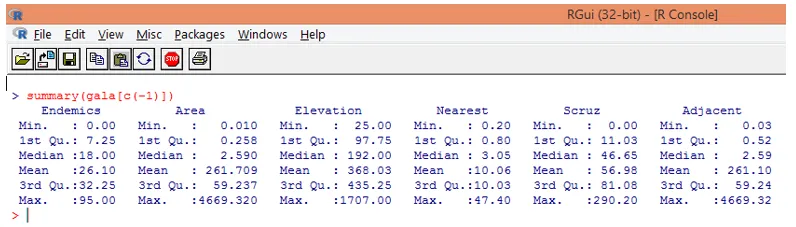
Notă, după cum se poate vedea mai sus, am exclus variabila Specie. Funcția sumară ne oferă informații de bază. Trebuie doar să observați valorile mediane pentru fiecare dintre aceste variabile și putem constata că există o diferență uriașă, în ceea ce privește intervalul de valori, între prima jumătate și a doua jumătate, de exemplu pentru valoarea mediană variabilă Area este 2, 59, dar maximul valoarea este 4669.320.
6. Acum că am terminat cu analiza de bază, vom genera o histogramă pentru Specie pentru a verifica dacă variabila urmărește distribuția Poisson. Acest lucru este ilustrat mai jos.

Codul de mai sus generează o histogramă pentru variabila Species împreună cu o curbă de densitate suprapusă peste ea.
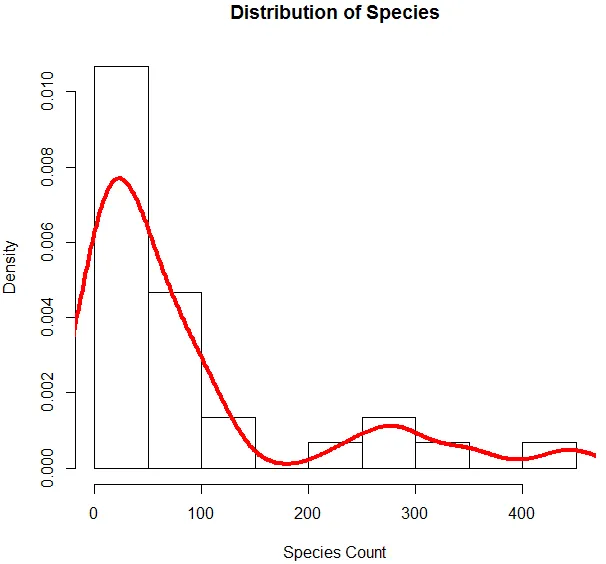
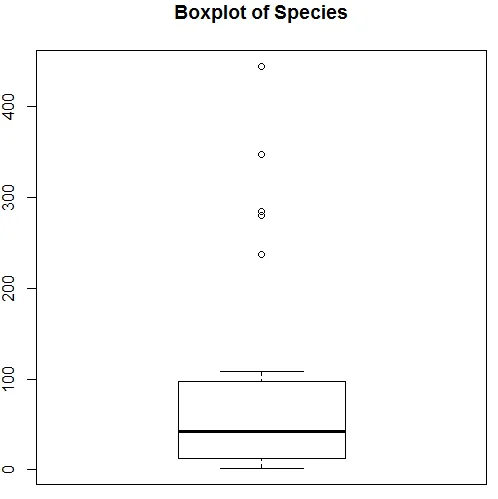
Vizualizarea de mai sus arată că Species urmărește o distribuție Poisson, deoarece datele sunt înclinate spre dreapta. Putem genera și un boxplot, pentru a obține mai multe informații despre modelul de distribuție, așa cum se arată mai jos.
7. După ce am făcut analiza preliminară, vom aplica acum regresia Poisson, după cum se arată mai jos
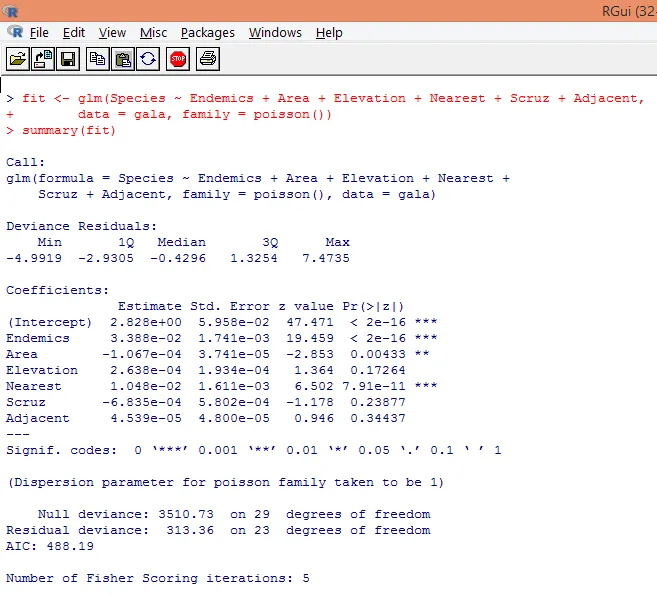
Pe baza analizei de mai sus, descoperim că variabilele Endemics, Area și Near pot fi semnificative și doar includerea lor este suficientă pentru a construi modelul corect de regresie Poisson.
8. Vom construi un model de regresie Poisson modificat, luând în considerare doar trei variabile, adică. Endemică, zonă și cel mai apropiat. Să vedem ce rezultate obținem.
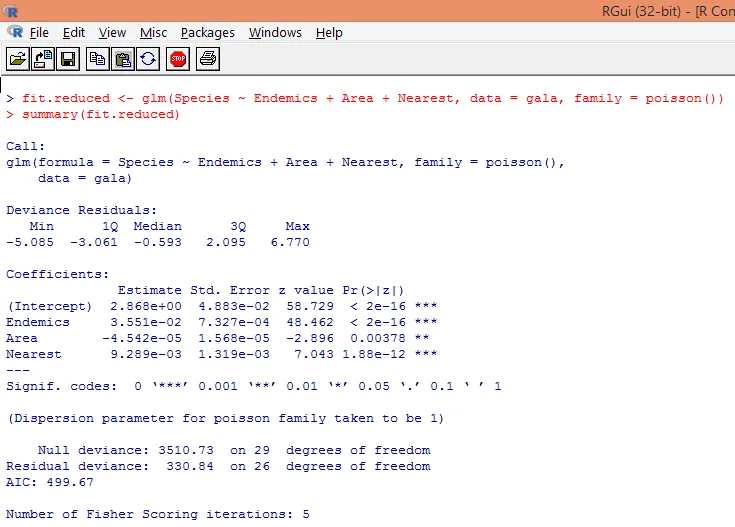
Produsul produce devianțe, parametri de regresie și erori standard. Putem observa că fiecare dintre parametri este semnificativ la nivelul p <0.05.
9. Următorul pas este interpretarea parametrilor modelului. Coeficienții modelului pot fi obținuți fie prin examinarea Coeficienților din ieșirea de mai sus, fie prin utilizarea funcției coef ().
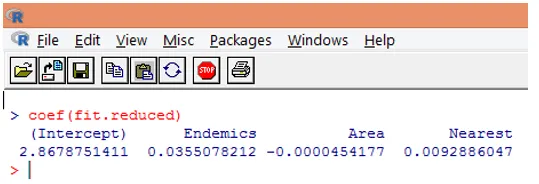
În regresia Poisson, variabila dependentă este modelată ca jurnalul mediei condiționale loge (l). Parametrul de regresie de 0, 0355 pentru Endemics indică faptul că o creștere a unei unități a variabilei este asociată cu o creștere de 0, 04 a numărului mediu de specii de jurnal, menținând alte variabile constante. Interceptarea este un număr mediu logistic de specii atunci când fiecare dintre predictori este egal cu zero.
10. Cu toate acestea, este mult mai ușor să interpretați coeficienții de regresie în scara inițială a variabilei dependente (numărul de specii, mai degrabă decât numărul de jurnal al speciilor). Expunerea coeficienților va permite o interpretare ușoară. Aceasta se face după cum urmează.
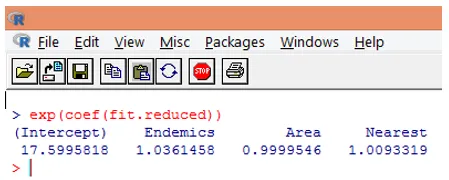
Din concluziile de mai sus, putem spune că o creștere a unității în suprafață înmulțește numărul estimat de specii cu 0, 9999, iar o creștere unitară a numărului de specii endemice reprezentate de Endemics înmulțește numărul de specii cu 1, 0361. Cel mai important aspect al regresiei Poisson este faptul că parametrii exponenți au un efect multiplicativ și nu un efect aditiv asupra variabilei de răspuns.
11. Folosind etapele de mai sus, am obținut un model de regresie Poisson pentru a prezice numărul de specii de plante de pe Insulele Galapagos. Cu toate acestea, este foarte important să verificați dacă există o suprasolicitare. În regresia Poisson, variația și mijloacele sunt egale.
Depresiunea apare atunci când variația observată a variabilei de răspuns este mai mare decât ar fi prevăzut de distribuția Poisson. Analiza suprasolicitării devine importantă, deoarece este comună cu datele de numărare și poate avea un impact negativ asupra rezultatelor finale. În R, supra-dispersia poate fi analizată folosind pachetul „qcc”. Analiza este ilustrată mai jos.
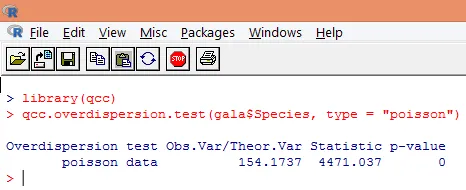
Testul semnificativ de mai sus arată că valoarea p este mai mică de 0, 05, ceea ce sugerează puternic prezența suprasolicitării. Vom încerca să potrivim un model folosind funcția glm (), prin înlocuirea family = „Poisson” cu family = „quasipoisson”. Acest lucru este ilustrat mai jos.
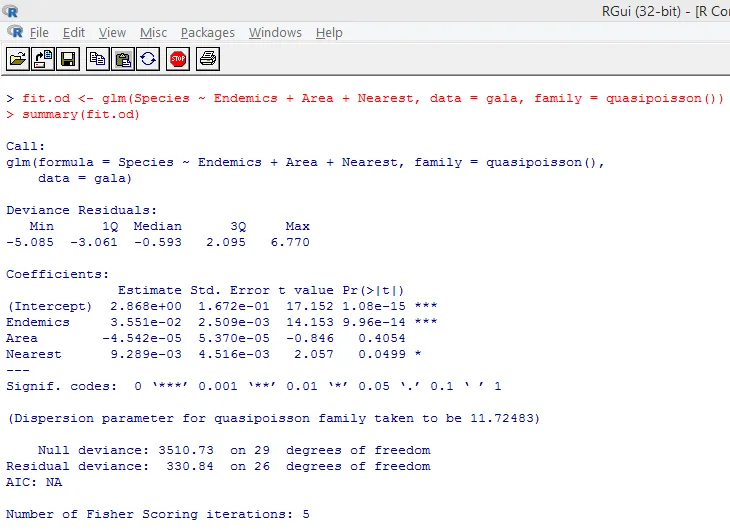
Studiind îndeaproape producția de mai sus, putem observa că estimările parametrilor în abordarea cvasi Poisson sunt identice cu cele produse de abordarea Poisson, deși erorile standard sunt diferite pentru ambele abordări. Mai mult, în acest caz, pentru Area, valoarea p este mai mare de 0, 05, care se datorează erorii standard mai mari.
Importanța regresiei Poisson
- Poisson Regresie în R este utilă pentru predicțiile corecte ale variabilei discrete / număr.
- Ne ajută să identificăm acele variabile explicative care au un efect semnificativ statistic asupra variabilei de răspuns.
- Regresul Poisson în R este cel mai potrivit pentru evenimente de natură „rară”, deoarece tind să urmeze o distribuție Poisson, în raport cu evenimentele obișnuite care urmează de obicei o distribuție normală.
- Este adecvat pentru aplicare în cazurile în care variabila de răspuns este un număr întreg mic.
- Are aplicații largi, deoarece o predicție a variabilelor discrete este crucială în multe situații. În medicină, poate fi folosit pentru a prezice impactul medicamentului asupra sănătății. Este puternic utilizat în analiza supraviețuirii ca moartea organismelor biologice, eșecul sistemelor mecanice etc.
Concluzie
Regresia Poisson se bazează pe conceptul de distribuție Poisson. Este o altă categorie aparținând setului de tehnici de regresie care combină proprietățile atât ale regresiilor liniare cât și ale celor logistice. Cu toate acestea, spre deosebire de regresia logistică care generează numai ieșire binară, este utilizată pentru a prezice o variabilă discretă.
Articole recomandate
Acesta este un ghid al regresiei Poisson din R. Aici vom discuta introducerea Implementării regresiei Poisson și a importanței regresiei Poisson. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- GLM în R
- Generator de număr aleatoriu în R
- Formula de regresie
- Regresie logistică în R
- Regresia liniară vs regresia logistică | Diferențe de top