

Diferența dintre Apache Nifi și Apache Spark
Până mult timp, când a fost nevoie de o muncă grea care trebuia finalizată, oamenii s-au bazat pe cai pentru a trage sarcini grele, pentru a menține viteza sau orice altceva între ei. Cu toate acestea, nu toți caii erau potriviți pentru fiecare sarcină. La fel se întâmplă și cu tehnologia de astăzi. Odată cu apariția noilor tehnologii care se revarsă în fiecare zi, devine extrem de important să cunoaștem aplicațiile lor reale. Două astfel de tehnologii sunt Apache Nifi și Apache Spark și vom studia despre ele în acest post.
Apache Spark este un cadru de calcul open source, care își propune să furnizeze o interfață pentru programarea întregului set de clustere cu toleranță implicită la erori și paralelismul de date. Acesta folosește RDD-urile (seturi de date distribuite rezistente) și prelucrează datele sub formă de fluxuri discretizate care sunt utilizate în continuare în scopuri analitice.
Apache Nifi (care este forma scurtă a NiagaraFiles) este un alt proiect software care are drept scop automatizarea fluxului de date între sistemele software. Proiectarea se bazează pe un model de programare bazat pe flux care oferă funcții care includ funcționarea cu capacitate de cluster. Este un sistem ușor de utilizat, fiabil și un sistem puternic pentru procesarea și distribuirea datelor. Suporta grafice directionate scalabile pentru rutarea datelor, medierea sistemului si logica de transformare. Haideți să discutăm comparațiile ambelor subiecte.
Comparație față în față între Apache Nifi și Apache Spark (Infografie)
Mai jos se află topul 9 Comparație între Apache Nifi și Apache Spark
Diferențe cheie între Apache Nifi și Apache Spark
Diferențele dintre Apache Nifi și Apache Spark sunt explicate în punctele prezentate mai jos:
- Apache Nifi este un instrument de ingerare a datelor care este utilizat pentru a furniza un sistem ușor de utilizat, puternic și fiabil, astfel încât procesarea și distribuirea datelor peste resurse să devină ușoare, în timp ce Apache Spark este o tehnologie de calcul extrem de rapidă, care este concepută pentru calcularea mai rapidă de către Folosind eficient interogări interactive, în gestionarea memoriei și în procesarea fluxurilor.
- Apache Nifi funcționează în modul autonom și în modul cluster, în timp ce Apache Spark funcționează bine în modul local sau autonom, Mesos, Fire și alte tipuri de moduri de cluster de date mari.
- Caracteristicile Apache Nifi include furnizarea de date, buffering eficient de date, coadă prioritară, QoS specifică fluxului, proveniență de date, recuperare buffer roll, comandă vizuală și control, șabloane de flux, securitate, funcții de streaming paralel, în timp ce caracteristicile apache scânteii includ fulgere rapide Capacitate de procesare rapidă, multilingvă, calculare în memorie, utilizarea eficientă a sistemelor hardware de marfă, analiză avansată, capacitate de integrare eficientă.
- Apache Nifi permite o mai bună lizibilitate și o mai bună înțelegere a sistemului, oferind capacități de vizualizare și caracteristici de drag and drop. Fluxul de date poate fi gestionat și guvernat cu ușurință folosind tehnici și procese convenționale, în timp ce în cazul Apache Spark pentru a vizualiza aceste tipuri de vizualizări este necesar un sistem de gestionare a clusterului precum Ambari. Apache Spark în sine nu oferă capabilități de vizualizare și este bun doar în ceea ce privește programarea. Este de departe un sistem foarte convenabil și stabil pentru procesarea unor cantități imense de date.
- Limitarea cu Apache Nifi este legată de avantajele sale. Singura caracteristică drag and drop oferă o limitare a imposibilității de a nu se putea scalda și de a oferi robustete atunci când vine vorba de integrarea acesteia cu alte componente și instrumente, în timp ce în cazul Apache Spark, limitarea principală vine împreună cu utilizarea hardware-ului extins de mărfuri și gestionarea acestora devine uneori o sarcină obositoare. Cealaltă limitare raportată vine împreună cu capacitățile sale de streaming legate de fluxul discret și Window sau fluxul de lot, în care transformarea RDD-urilor în cadru de date și seturi de date oferă uneori o cauză de instabilitate.
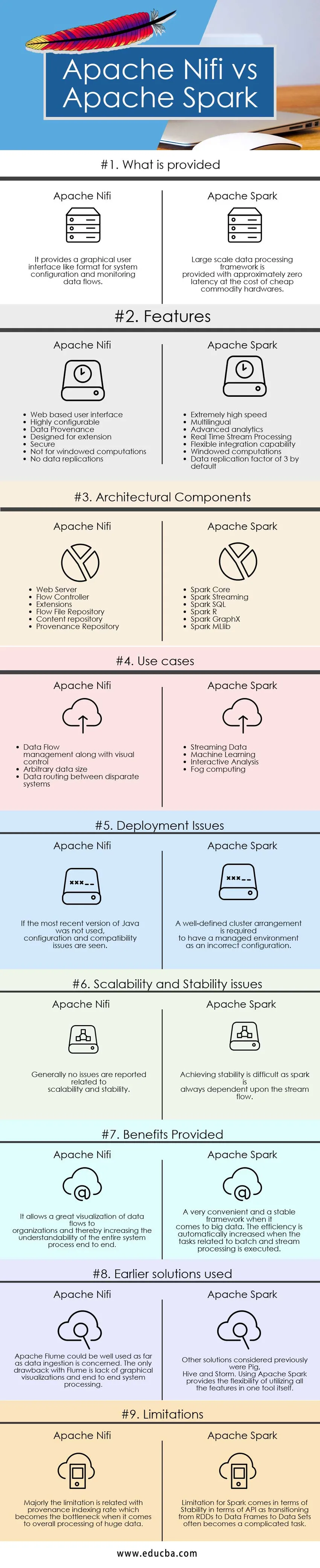
Tabelul de comparare Apache Nifi vs Apache Spark
| Bazele comparației | Apache Nifi | Scânteie Apache |
| Ce este oferit | Oferă o interfață grafică de utilizator precum un format pentru configurarea sistemului și monitorizarea fluxurilor de date. | Cadrul de prelucrare a datelor la scară largă este prevăzut cu o latență aproximativ zero la costul hardware-ului de marfă ieftin. |
| Caracteristici |
|
|
| Componente arhitecturale |
|
|
| Cazuri de utilizare |
|
|
| Probleme de implementare | Dacă cea mai recentă versiune a Java nu a fost utilizată, se văd probleme de configurare și compatibilitate | Un aranjament de cluster bine definit este necesar pentru a avea un mediu gestionat ca o configurație incorectă |
| Probleme de scalabilitate și stabilitate | În general, nu sunt raportate probleme legate de scalabilitate și stabilitate | Obținerea stabilității este dificilă, întrucât o scânteie depinde întotdeauna de fluxul fluxului. |
| Beneficiile oferite | Permite o vizualizare excelentă a fluxurilor de date către organizații și, prin urmare, creșterea înțelegerii întregului proces de sistem de la capăt la sfârșit | Un cadru foarte convenabil și stabil când vine vorba de date mari. Eficiența este crescută automat atunci când se execută sarcinile legate de procesarea lotului și fluxului. |
| Soluții anterioare utilizate | Apache Flume ar putea fi bine folosită în ceea ce privește ingestia de date. Singurul dezavantaj cu Flume este lipsa vizualizărilor grafice și procesarea sistemului end-to-end | Alte soluții luate în considerare anterior au fost Porcul, stupul și Furtuna. Utilizarea Apache Spark oferă flexibilitatea utilizării tuturor funcțiilor într-un singur instrument. |
| limitări | Limitarea este în mare parte legată de rata de indexare a provenienței, care devine gâtul de blocare atunci când vine vorba de procesarea generală a datelor uriașe | Limitarea pentru scânteie vine în termeni de stabilitate în termeni de API, deoarece tranziția de la RDD la cadre de date la seturi de date devine adesea o sarcină complicată. |
Concluzie - Apache Nifi vs Apache Spark
Pentru a încheia postarea, se poate spune că Apache Spark este un cal de război greu, în timp ce Apache Nifi este un cal de curse. Ambele au propriile avantaje și limitări pentru a fi utilizate în domeniile respective. Trebuie să decideți instrumentul potrivit pentru afacerea dvs. Rămâneți la curent cu blogul nostru pentru mai multe articole legate de tehnologiile mai noi de date mari.
Articol recomandat
Acesta a fost un ghid pentru Apache Nifi și Apache Spark, semnificația lor, Comparația dintre cap și cap, diferențele cheie, tabelul de comparare și concluzii. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Apache Hadoop vs Apache Spark | Top 10 comparații pe care trebuie să le știi!
- Apache Storm vs Apache Spark - Aflați 15 diferențe utile
- 7 lucruri importante despre Apache Spark (Ghid)
- Cele mai bune 15 lucruri pe care trebuie să le știi despre MapReduce vs Spark