

Diferența dintre Apache Hive și Apache HBase -
Povestea Apache Hive începe în anul 2007 când programatorul non Java trebuie să se lupte în timp ce folosește Hadoop MapReduce. Cercetătorii și dezvoltatorii au prezis că mâine este o eră a Big Data. Deja s-au acumulat diferite formate de date, cum ar fi structurate, semi-structurate și nestructurate. Chiar și Facebook se lupta cu cantitatea mai mare de procesare a datelor. Cercetătorii de la Facebook au introdus Apache Hive pentru prelucrarea datelor pe Hadoop Cluster. Facebook a fost prima companie care a venit cu Apache Hive.
Povestea Apache HBase începe în 2006, când Powerset-ul de pornire din San Francisco încerca să construiască un motor de căutare a limbajului natural pentru web. HBase este o implementare a Bigtable Google. Ne-am dat seama vreodată, de ce era nevoie să vină cu încă o arhitectură de stocare? Sistemul relațional de gestionare a bazelor de date funcționează încă de la începutul anilor ’70. Există multe cazuri de utilizare pentru care bazele de date relaționale au sens, dar pentru unele probleme specifice, modelul relațional nu se potrivește foarte bine.
Permiteți-mi să explic despre Apache Hive și Apache HBase în mai multe detalii.
Diferențele dintre Apache Hive și Apache HBase
Apache Hive este un proiect open-source Apache construit pe partea de sus a Hadoop pentru interogarea, rezumarea și analizarea seturilor de date mari folosind o interfață asemănătoare SQL. Apache Hive furnizează un limbaj asemănător cu SQL numit HiveQL, care transformă în mod transparent interogările în MapReduce pentru execuție pe seturi de date mari stocate în Sistemul de fișiere distribuit Hadoop (HDFS). Apache Hive este o componentă a clusterului Hadoop care este în mod normal implementată de analiștii de date. Stupul Apache este utilizat pentru procesarea prin loturi a lucrărilor mari ETL. Apache Hive acceptă, de asemenea, interogări SQL pe loturi de date foarte mari. Apache Hive crește flexibilitatea designului schemelor și, de asemenea, serializarea și deserializarea datelor. Apache Hive nu acceptă procesarea tranzacțiilor online (OLTP), deoarece stupul nu acceptă interogări în timp real și actualizări la nivel de rând.
Apache HBase este o bază de date NoSQL open source care oferă acces în timp real, citit și scris la seturi de date mari. NoSQL este o bază de date non-relațională. Apache HBase este o bază de date distribuită orientată pe coloane, care rulează pe partea de sus a sistemului de fișiere distribuite Hadoop (HDFS). Deci, HBase aduce beneficii ale NoSQL la Hadoop. Apache HBase oferă capabilități de acces aleatoriu a datelor prezente în HDFS. Îndeplinește toleranța la erori oferită de HDFS. Utilizatorul poate stoca datele în HDFS fie direct, fie prin intermediul HBase.
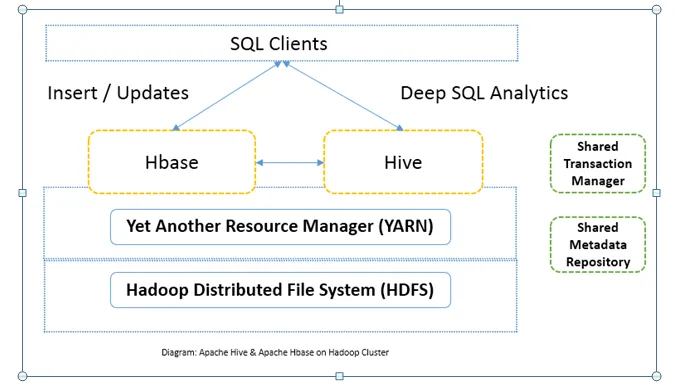
Comparație față în față între Apache Hive și Apache HBase (Infografie)
Mai jos este diferența de top 12 între Apache Hive și Apache HBase

Diferențe cheie - Apache Hive vs Apache HBase
Mai jos sunt listele de puncte, descrieți diferențele cheie între Apache Hive și Apache HBase:
- Apache HBase este o bază de date în timp ce Apache Hive este un motor de baze de date.
- Apache Hive este utilizat în principal pentru procesarea loturilor (OLAP), în timp ce Apache HBase este utilizat în principal pentru procesarea tranzacțională (OLTP).
- Apache Hive execută majoritatea interogărilor SQL în timp ce Apache HBase nu permite interogările SQL direct.
- Apache Hive nu acceptă operațiuni la nivel de înregistrare, cum ar fi actualizarea, inserarea și ștergerea, în timp ce Apache HBase acceptă operațiuni la nivel de înregistrare, cum ar fi actualizarea, inserarea și ștergerea.
- Apache Hive rulează în partea de sus a MapReduce în timp ce Apache HBase rulează în partea superioară a Sistemului de fișiere distribuite Hadoop (HDFS).
Apache Hive interogează fișierele definind un tabel virtual și executând interogări HQL deasupra acestuia. Este un proces în care fișierele sunt conectate practic la o tabelă precum structura și utilizatorul poate executa Hive Query Language (HQL) și aceste interogări sunt convertite în MapReduce Job de către Hive. Utilizatorul nu trebuie să scrie MapReduce job, interogările HQL sunt transformate intern în fișiere jar și aceste fișiere jar vor fi implementate pe seturi de date.
În timp ce în Apache HBase, tabelele sunt împărțite în regiuni și sunt deservite de serverele regiunii. Alte regiuni sunt divizate vertical de familii de coloane în magazine, iar magazinele sunt salvate ca fișiere în HDFS.
Când se utilizează Apache Hive:
- Cerințe de depozitare a datelor
- Întrebări analitice
- Analiza datelor care este familiarizată cu SQL
Când se utilizează Apache HBase:
- Procesarea rapidă și interactivă a datelor
- Interogări în timp real
- Căutări rapide
- Procesare din partea serverului
- Acces aleatoriu la citire / scriere la Big Data
- Scalabilitate a aplicației
Apache Hive poate fi utilizat pentru a calcula tendințele și jurnalele site-ului de comerț electronic pentru o anumită durată, regiune sau fus orar. Poate fi utilizat pentru a prelucra interogarea prin loturi peste date istorice, în timp ce Apache HBase poate fi utilizat de Facebook sau LinkedIn pentru mesagerie și analize în timp real. Poate fi folosit și pentru numărarea aprecierilor.
Tabelul de comparare Apache Hive vs Apache HBase
Discut despre artefacte majore și disting între Apache Hive și Apache HBase.
| Apache Hive | Apache HBase | |
| Procesarea datelor | Apache Hive este folosit pentru
procesare lot, adică prelucrare analitică online (OLAP) | Apache HBase este utilizat pentru procesarea tranzacțională, adică procesare tranzacțională online (OLTP) |
| Viteză de procesare | Apache Hive are o latență mai mare din cauza executării jobului MapReduce în fundal | Apache HBase lucrează la interogarea în timp real și mult mai rapid decât Apache Hive |
| Compatibilitatea cu Hadoop | Apache Hive rulează în topul MapReduce | Apache HBase rulează pe HDFS |
| Definiție | Apache Hive este open source și similar cu SQL utilizat pentru interogări analitice | Apache HBase este o bază de date NoSQL open source folosită pentru interogarea în timp real |
| Metadate partajate | Datele create în Apache Hive sunt vizibile automat pentru Apache HBase | Datele create în Apache HBase sunt vizibile automat pentru Apache Hive |
| Schemă | Apache Hive acceptă Schema pentru introducerea datelor în tabele | Apache HBase este o bază de date fără Schema. |
| Actualizare caracteristică | Funcția de actualizare este complicată în Apache Hive | Utilizatorul poate actualiza foarte ușor datele din Apache HBase |
| Operațiuni | Operațiunile din Apache Hive nu se execută în timp real | Operațiunile în Apache HBase se desfășoară în timp real |
| Tipuri de date | Apache Hive este destinat datelor structurate și semi-structurate | Apache HBase este pentru date nestructurate. |
| Nivel de consecvență | Stupul Apache susține consecvența eventuală | Apache HBase acceptă consecvența imediată |
| Metode de partiție | Apache Hive acceptă funcțiile Sharding | Apache HBase acceptă, de asemenea, caracteristicile Sharding |
| Stocare a datelor | Data este păstrată în Hast Metastore, Partiții și găleți din Apache Hive | Datele sunt stocate în tabele Coloana și Rânduri în tabele din Apache HBase |
Concluzie - Apache Hive vs Apache HBase
În mod obișnuit, Apache Hive vs Apache HBase este utilizat împreună în același grup. Ambele pot fi utilizate împreună pentru a spori puterea de procesare. Deoarece stupul îmbunătățește laturile analitice ale HDFS, în timp ce HBase îmbunătățește tranzacțiile în timp real. Utilizatorul poate utiliza Hive ca instrument ETL pentru inserțiile de lot cu datele în HBase și apoi pentru a executa interogări care pot alătura în continuare datele prezente pe tabelele HBase cu datele care sunt deja prezente pe HDFS. Datele pot fi citite și scrise de la Apache Hive la HBase și din nou. Interfața dintre Apache Hive și Apache HBase este încă în faza de maturizare. Mai sunt multe pentru a veni. Cu toate acestea, pot spune că Apache Hive și Apache HBase fac clusterul Hadoop mai robust și mai puternic.
Articole similare:
Acesta a fost un ghid pentru Apache Hive vs Apache HBase, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparare și concluzii. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Top 5 mari tendințe de date
- 5 provocări ale analizelor de date mari
- Cum să spargi interviul dezvoltatorului Hadoop?
- 5 provocări ale analizelor de date mari