
Ce este Cassandra?
Cassandra este o bază de date NoSQL, care este o bază de date distribuită peer to peer. Se rulează pe un cluster care are noduri omogene. Este realizat astfel încât să poată gestiona volume mari de date. Odată cu tratarea acestor date, acesta ar trebui să fie, de asemenea, capabil să ofere o capacitate ridicată. Cassandra oferă un nivel ridicat de operațiuni în ceea ce privește citirea și scrierea. Arhitectura clusterului Cassandra nu are maeștri, sclavi sau lideri specifici. Utilizând acest mod, vă asigurați că nu există un singur punct de eșec. Să aruncăm o privire asupra arhitecturii în detaliu.
Arhitectura Cassandra
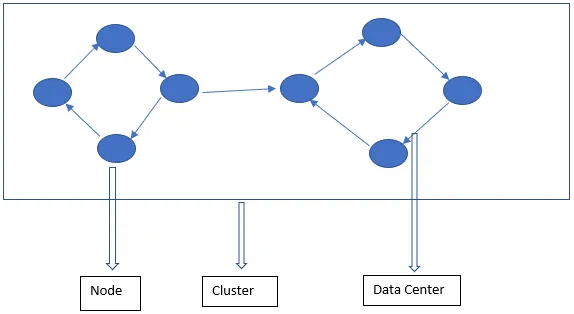
Arhitectura Cassandra constă în principal din Node, Cluster și Data Center. Pe lângă acestea, există și alte componente. Cassandra este o bază de date stocată pe rând. Permite utilizatorilor autorizați să se conecteze la orice nod din orice centru de date folosind CQL.
Structuri cheie în Cassandra
Acestea sunt următoarele structuri cheie în Cassandra:
- Nod - Acesta este locul în care datele sunt stocate. Este cea mai de bază componentă a Cassandra. Poate fi gândit ca un singur server într-un rack. Se asigură că nu există un singur punct de eșec.
- Data Center - Un centru de date este o colecție de noduri. Acesta poate fi unul fizic sau unul virtual. În funcție de volumul de lucru, centrele de date sunt împărțite și alese. Factorul de replicare este decis pe baza centrului de date. În funcție de acest factor de replicare, datele pot fi scrise în centre de date diferite.
- Cluster - Clusterul cuprinde unul sau mai multe centre de date. De obicei, grupurile se întind pe diferite locații fizice.
Pe lângă acestea, celelalte componente care joacă un rol în Cassandra sunt ca mai jos.
1. Jurnal de angajare
Datele care sunt angajate pentru menținerea durabilității datelor sunt stocate în jurnalul de angajare. Datele sunt mutate într-un tabel de șiruri sortat (explicat în continuare) Odată ce această mișcare este făcută, atunci jurnalul de angajare poate fi arhivat, șters sau reciclat.
2. Tabel SS
Acest tabel menționat în punctul precedent stochează jurnalele sau tabelele de memorie la intervale regulate. Este un fișier de date imuabile. Tabelele SS pot stoca datele frecvent într-o manieră secvențială. Acestea adaugă date și mențin informații pentru fiecare tabel Cassandra.
3. Tabelul CQL
Tabelul de interogare Cassandra este o colecție de coloane ordonate care pot prelua un rând din acest tabel. Există coloane stocate în acest tabel în care datele pot fi preluate folosind cheia primară.
4. Filtrul în floare
Este un tip simplu de memorie cache în care există algoritmi non-deterministi stocați pentru testare. Verifică dacă un element este sau nu membru al setului. Aceste filtre sunt de obicei accesate după fiecare interogare care se execută.
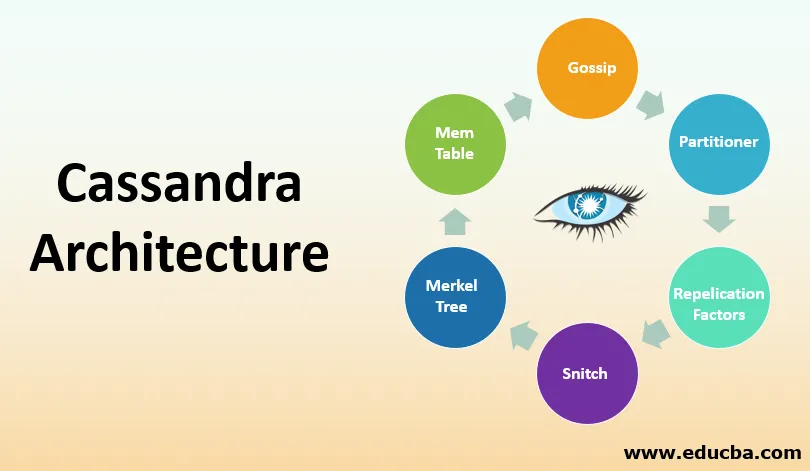
Componente cheie pentru configurarea Cassandra
Există următoarele componente în Cassandra:
1. Bârfa
- După cum sugerează și numele, trebuie să existe o comunicare între colegi pentru a descoperi și a împărtăși locația și starea informațiilor despre toate nodurile.
- Această informație ar trebui să persiste local, astfel încât fiecare nod să poată utiliza informațiile de îndată ce un nod trebuie repornit. Nodurile descoperă informații despre alte noduri schimbând informații.
- Acest lucru se poate face pentru maximum trei noduri. Informațiile nu sunt partajate cu fiecare nod prezent în cluster sau centru de date. Informațiile sunt partajate cu câteva noduri, dar în cele din urmă, informațiile de stare traversează în întregul cluster.
2. Partitioner
- Partitionerul decide ce nod trebuie să primească prima replică a oricăror date. De asemenea, este responsabil să se îngrijească de distribuția acestor replici.
- Acesta va determina ce nod ar trebui să aibă ce replicare în cluster. Fiecare rând de date trebuie identificat în mod unic. Acest lucru se poate face utilizând o cheie primară sau o cheie de partiție.
- Partitionerul este o funcție hash care ajută la obținerea unui jeton de la o cheie primară a oricărui rând. Fiecare nod are atribuită o valoare num_token care poate fi setată ca partiționer.
- Valoarea jetonului generată ajută la determinarea care nod primește replica rândurilor.
3. Factor de replicare
- Acest factor determină numărul total de replici prezente în cluster. Dacă factorul de replicare este 1, atunci există o singură copie a fiecărui rând pe un singur nod.
- În mod similar, dacă factorul de replicare este de două, vor fi menținute două copii în care fiecare copie este prezentă pe un nod diferit. După cum am menționat anterior, nu există o arhitectură master-slave în Cassandra, fiecare copie este importantă.
- Factorul de replicare este definit pentru fiecare centru de date. Acest factor ar trebui să fie mai mare decât unul, dar nu mai mult decât numărul de noduri prezenți în cluster.
4. Snitch
- Strategia de replicare care ajută la obținerea locului unde trebuie să fie plasate replici pentru un grup de mașini din centrul de date și rack este cunoscută sub numele de Snitch.
- Există un strat dinamic care ajută la monitorizare și performanță și ajută la alegerea celei mai bune replici din care se pot citi datele. Snitches-urile trebuie configurate numai atunci când este creat un cluster.
- Are valori implicite activate pentru majoritatea implementărilor. Modificările de configurare pot fi făcute în fișierul Cassandra.yml unde este prezent pragul de snitch dinamic pentru fiecare nod.
5. Arborele Merkle
- Pot exista diferențe în blocurile de date. Pentru a găsi cu ușurință diferențele, Arborele Merkle este un copac care ajută la realizarea acestui lucru.
- Nodurile de frunze ale copacului conțin hash de blocuri de date separate, iar nodurile părinți au informații sau stochează hașa copiilor lor.
- Folosind această tehnică este mai ușor să găsiți diferențe între nodurile care sunt prezente.
6. Tabelul Mem
- Acest tabel conține informații despre memoria cache ale cărui date nu sunt încă curățate și se află în memorie.
Concluzie
Cassandra este o bază de date NoSQL care este utilă în procesarea unor cantități uriașe de date. Nu are o arhitectură tipică master-slave și, prin urmare, toate nodurile sunt la fel de importante. Nodurile au replici în cluster, în funcție de factorul de replicare. Acest lucru asigură coerența și durabilitatea datelor. Cu toate aceste caracteristici este clar că Cassandra este foarte utilă pentru datele mari. Prin urmare, Cassandra este durabilă, rapidă, fiind distribuită și fiabilă.
Articole recomandate
Acesta este un ghid pentru Arhitectura Cassandra. Aici vom discuta Introducerea, arhitectura Cassandra, structura cheilor și componentele cheie ale Cassandra. De asemenea, puteți parcurge și alte articole sugerate -
- Prezentare generală a arhitecturii Kubernetes
- Ce este arhitectura Big Data?
- Caracteristici adăugate la Arhitectura AutoCAD
- Arhitectură în cloud computing