

Introducere în Instalarea stupului
În Instalarea stupului, unele cerințe preliminare ar trebui făcute înainte de Instalare.
Componentele Hadoop precum Hive, Hbase, Pig, etc, toate acceptă mediul Linux. Prin urmare, este recomandat să ai un sistem de operare Linux pe dispozitivul tău. Dacă nu este cazul și doriți să practicați în stup, în timp ce aveți Windows pe sistemul dvs. Ce poți face este să instalezi mașina CDH pe sistemul tău și să o folosești ca platformă pentru a explora Hadoop. Acest lucru va necesita minimum 4 GB RAM pe sistemul dvs. sau puteți avea o mașină CDH în pen drive și să o utilizați.
În orice caz, puteți avea întotdeauna o soluție la întrebarea dvs. care poate mai devreme decât mai târziu.
Condiții preliminare pentru instalarea stupului
Există câteva condiții prealabile pentru instalarea stupului pe orice mașină:
- Instalare Java
- Instalarea Hadoop
Pasul 1
- Verificați instalarea Java.
- Deschideți terminalul și tastați comanda.
Java Versiunea
- Dacă java este instalat pe sistem, vă va da versiunea sau altceva o eroare. În cazul meu, Java este deja instalat și mai jos este ieșirea comenzii.

- În caz, Java nu este instalat în sistemul dvs. Puteți accesa linkul de mai jos și descărcați Java și instalați-l.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Instalare Java
- Extrageți descărcarea.
- Mută-l pe „/ usr / local /”.
- Configurați variabilele PATH și JAVA_HOME.
Pasul 2
- Verificați că Hadoop este instalat.
- Deschideți terminalul și tastați comanda.
Hadoop-Version
- Dacă Hadoop este deja instalat, această comandă vă va oferi versiunea sau altceva o eroare.
- În cazul meu, Hadoop s-a instalat deja, de aici și ieșirea de mai jos.
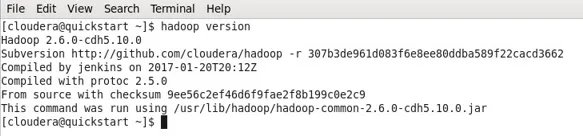
- Acum puteți observa că lucrez cu o mașină CDH5.
- Dacă Hadoop nu este instalat, descărcați Hadoop de la fundația software Apache.
Instalarea Hadoop
1. Configurare Hadoop
2. Configurați Hadoop
Fișierele care trebuie modificate pentru a configura Hadoop sunt:
- core-site.xml
- hdfs-site.xml
- fire-site.xml
- mapred-site.xml
3. Configurați Namenode folosind comanda:
Hdfs namenode -format
4. Porniți dfs folosind următoarea comandă:
start -dfs.sh
5. Începeți firele folosind comanda:
Start -yarn.sh
Cum se instalează stupul?
Mai jos de puncte ajută la instalarea stupului:
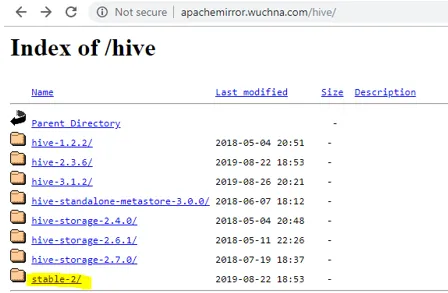
- Primul lucru pe care trebuie să-l facem este să descărcăm lansarea stupului care poate fi efectuată făcând clic pe linkul de mai jos: http://apachemirror.wuchna.com/hive/
- Mai sus, linkul va oferi linkul dintre care trebuie să alegeți stabil-2 evidențiat mai jos în galben:
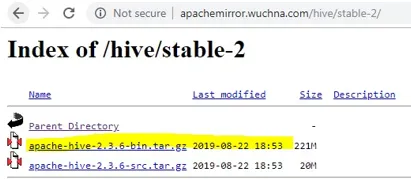
- După deschiderea stable-2, alegeți fișierul bin (evidențiat galben în captură de ecran) și faceți clic dreapta și „adresa de legătură pentru copiere”.
Pași pentru instalarea stupului
Mai jos sunt pașii pentru instalarea stupului:
Pasul 1: Descărcați fișierul tar.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Pasul 2: Extrageți fișierul.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Pasul 3: Mutați fișierele apache în directorul / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Pasul 4: Configurați mediul Hive prin adăugarea următoarelor linii la fișierul ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Pasul 5: Executați fișierul bashrc.
$ source ~/.bashrc
Pasul 6: Configurare Hive - Editați fișierul hive-env.sh pentru a adăuga acest lucru:
export HADOOP_HOME=/usr/local/Hadoop
Pasul 7: Modificați folosind comenzile de mai jos:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Acum, pentru a verifica instalarea stupului sau nu, folosiți versiunea comută stup.
- Aici, versiunea stupului intră în coaja stupului, ceea ce înseamnă că stupul este instalat. Cu toate acestea, în cazul meu, este versiunea mai veche, prin urmare, oferind avertizarea.

Concluzie - Instalarea stupului
Hive deschide datele mari pentru o mulțime de oameni datorită ușurinței și naturii sale similare cu SQL precum limbajul de interogare și interfețele. Stupul este construit pe miezul Hadoop, deoarece folosește Mapreduce pentru execuție. Foarte ușor de a prelua datele și de a prelucra Big Data.
Articole recomandate
Acesta este un ghid pentru Instalarea stupului. Aici discutăm câteva condiții preliminare pentru instalarea stupului pe orice mașină și cum se instalează stupul în pași pentru o mai bună înțelegere. Puteți, de asemenea, să parcurgeți alte articole conexe pentru a afla mai multe-
- Ce este un stup?
- Comenzile stupului
- Cum se instalează stupul
- Ce este Porcul?