
Introducere în tehnici de ansamblare
Ensemble learning este o tehnică de învățare automată, care necesită ajutorul mai multor modele de bază și combină producția lor pentru a produce un model optimizat. Acest tip de algoritm de învățare automată ajută la îmbunătățirea performanței generale a modelului. Aici modelul de bază care este cel mai des utilizat este clasificatorul de arbori de decizie. Un arbore de decizii funcționează practic pe mai multe reguli și oferă un rezultat predictiv, în care regulile sunt nodurile și deciziile lor vor fi copiii lor și nodurile frunze vor constitui decizia finală. După cum se arată în exemplul unui arbore de decizie.
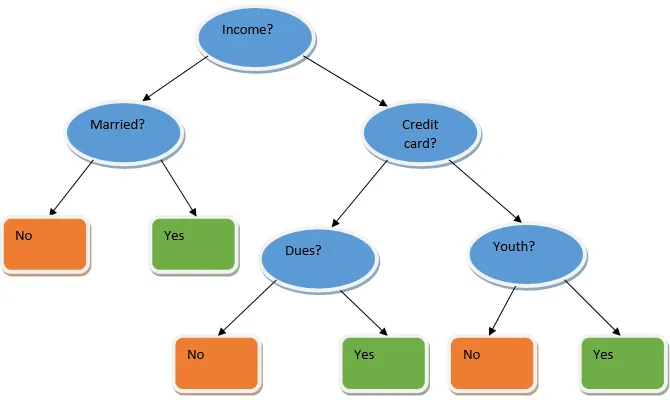
Arborele decizional de mai sus vorbește practic despre dacă o persoană / client poate primi un împrumut sau nu. Una dintre regulile de eligibilitate a împrumutului da este că, dacă (venitul = Da && căsătorit = Nu), atunci Împrumutul = Da, așa este modul în care funcționează un clasificator al arborelor de decizie. Vom încorpora aceste clasificatoare ca un model de bază multiplu și le vom combina producția pentru a construi un model optim predictiv. Figura 1.b prezintă imaginea de ansamblu a unui algoritm de învățare a ansamblului.
Tipuri de tehnici de ansambluri
Diferite tipuri de ansambluri, dar accentul nostru principal va fi pe următoarele două tipuri:
- Bagging
- stimularea
Aceste metode ajută la reducerea variației și prejudecății într-un model de învățare automată. Acum să încercăm să înțelegem ce este prejudecata și variația. Prejudecata este o eroare care apare din cauza ipotezelor incorecte din algoritmul nostru; o părtinire ridicată indică faptul că modelul nostru este prea simplu / îmbrăcat. Variația este eroarea care este cauzată de sensibilitatea modelului la fluctuații foarte mici din setul de date; o variație mare indică faptul că modelul nostru este extrem de complex / de îmbrăcat. Un model ML ideal ar trebui să aibă un echilibru adecvat între prejudecată și variație.
Cizmă de agregare / Bagging
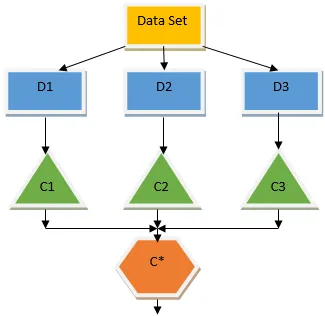
Baggingul este o tehnică de ansamblu care ajută la reducerea variației în modelul nostru și, prin urmare, evită supraîncadrarea. Bagajul este un exemplu al algoritmului de învățare paralel. Bagajul funcționează pe baza a două principii.
- Bootstrapping: Din setul de date inițiale, diferite populații de eșantion sunt considerate cu înlocuire.
- Agregarea: medierea rezultatelor tuturor clasificatorilor și asigurarea unui rezultat unic, pentru aceasta se folosește votul majorității în cazul clasificării și medierea în cazul problemei de regresie. Unul dintre faimoșii algoritmi de învățare a mașinilor care folosesc conceptul de bagaj este o pădure întâmplătoare.
Pădurea întâmplătoare
În pădure aleatorie din eșantionul aleator retras din populație cu înlocuire și un subset de caracteristici este selectat din setul tuturor caracteristicilor este construit un arbore de decizie. Din aceste subseturi de caracteristici, oricare dintre caracteristici oferă cea mai bună divizare este selectată ca rădăcină pentru arborele de decizie. Subsetul de caracteristici trebuie ales în mod aleatoriu cu orice preț, altfel vom ajunge să producem doar o corelare corelată, iar variația modelului nu va fi îmbunătățită.
Acum ne-am construit modelul cu probele prelevate de la populație, întrebarea este cum validăm modelul? Deoarece avem în vedere eșantioanele cu înlocuire, prin urmare, toate eșantioanele nu vor fi luate în considerare și unele dintre ele nu vor fi incluse în nicio pungă, acestea se numesc din eșantioane. Putem valida modelul nostru cu aceste probe OOB (din pungă). Parametrii importanți care trebuie luați în considerare într-o pădure aleatorie sunt numărul de eșantioane și numărul de arbori. Să considerăm „m” ca subsetul de caracteristici și „p” este setul complet de caracteristici, acum ca regulă de degetul mare, este întotdeauna ideal să alegeți
- m as√ și o dimensiune minimă a nodului ca 1 pentru o problemă de clasificare.
- m ca P / 3 și dimensiunea minimă a nodului să fie 5 pentru o problemă de regresie.
M și p trebuie tratate ca parametri de reglare atunci când avem de-a face cu o problemă practică. Antrenamentul poate fi încheiat odată ce stabilizarea erorii OOB. Un dezavantaj al pădurii aleatorii este că atunci când avem 100 de caracteristici în setul nostru de date și doar câteva caracteristici sunt importante, atunci acest algoritm se va comporta slab.
stimularea
Boosting este un algoritm de învățare secvențial care ajută la reducerea prejudecății în modelul nostru și variația în unele cazuri de învățare supravegheată. De asemenea, ajută la convertirea cursanților slabi în studenți puternici. Îmbunătățirea funcționează pe principiul plasării secvențial a cursanților slabi și atribuie o greutate fiecărui punct de date după fiecare rundă; mai multă greutate este atribuită punctului de date clasificat greșit în runda anterioară. Această metodă ponderată secvențială de formare a setului nostru de date este diferența cheie față de cea a bagajului.
Fig3.a prezintă abordarea generală în stimularea
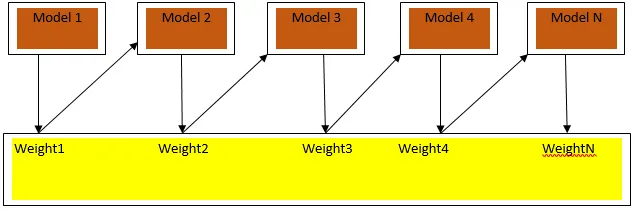
Predicțiile finale sunt combinate pe baza votului majorității ponderate în cazul clasificării și al sumei ponderate în cazul regresiei. Cel mai utilizat algoritm de impulsionare este amplificarea adaptivă (Adaboost).
Boosting adaptiv
Pașii implicați în algoritmul Adaboost sunt următorii:
- Pentru n punctele date, definim clasicul țintă și inițializăm toate greutățile la 1 / n.
- Ne adaptăm clasificatorii la setul de date și alegem clasificarea cu cea mai mică pondere de eroare de clasificare
- Alocăm greutăți pentru clasificator printr-o regulă de deget mare, bazată pe precizie, dacă precizia este mai mare de 50%, atunci greutatea este pozitivă și invers.
- Actualizăm ponderile clasificatoarelor la sfârșitul iterației; actualizăm mai multă greutate pentru punctul clasificat greșit, astfel încât în iterația următoare îl clasificăm corect.
- După toată iterația obținem rezultatul predicției finale pe baza votului majoritar / media ponderată.
Adaboosting-ul funcționează eficient cu studenții slabi (mai puțin complexi) și cu clasificatori cu prejudecăți mari. Avantajele majore ale Adaboosting sunt că este rapid, nu există parametri de reglare similare cu cazul bagajului și nu facem niciun fel de presupuneri cu privire la studenții slabi. Această tehnică nu oferă un rezultat precis când
- Există mai multe evidențe în datele noastre.
- Setul de date este insuficient.
- Elevii slabi sunt extrem de complexi.
De asemenea, sunt susceptibile la zgomot. Arborii de decizie care sunt produși în urma impulsionării vor avea o adâncime limitată și o precizie ridicată.
Concluzie
Tehnicile de învățare a ansamblurilor sunt utilizate pe scară largă pentru îmbunătățirea preciziei modelului; trebuie să decidem ce tehnică să folosim pe baza setului nostru de date. Dar aceste tehnici nu sunt preferate în unele cazuri în care interpretabilitatea are importanță, deoarece pierdem interpretabilitatea cu prețul îmbunătățirii performanței. Acestea au o semnificație extraordinară în industria asistenței medicale, unde o îmbunătățire mică a performanței este foarte valoroasă.
Articole recomandate
Acesta este un ghid pentru tehnici de asamblare. Aici discutăm introducerea și două tipuri majore de tehnici de ansamblare. Puteți, de asemenea, să parcurgeți alte articole conexe pentru a afla mai multe-
- Tehnici de steganografie
- Tehnici de învățare a mașinilor
- Tehnici de construire a echipei
- Algoritmi de știință a datelor
- Cele mai utilizate tehnici de învățare a ansamblurilor