

Ce este funcția stupului?
După cum știm astăzi, Hadoop este una dintre tehnologiile versatile din datele mari. Hadoop are capacitatea de a face față cu setul de date mari, dar întrucât creșterea datelor este proporțională, programele de reducere a hărților devin dificile. Pentru a efectua interogări SQL, prezentă în HDFS o astfel de tehnologie a fost introdusă de Hadoop, numită apache Hive, începută de Facebook. Stupul este foarte utilizat de analistul de date. Acestea sunt implementate pentru trei funcționalități și anume: Rezumarea datelor, analiza datelor pe fișierul distribuit și interogarea de date. Hive furnizează interogări de tip SQL numite HQL - limbajul de interogare înaltă acceptă funcții DML, definite de utilizator. Compilatorul Hive transformă în interior această interogare în locuri de muncă pentru reducerea hărții, ceea ce simplifică munca lui Hadoop în scrierea de programe complexe. Am putea găsi un stup în aplicație precum Depozitarea datelor, vizualizarea datelor și analiza ad-hoc, analiza Google. Avantajul esențial este că folosesc cunoștințele SQL care este o abilitate de bază implementată în oamenii de știință de date și în profesioniștii de software.
Diferite funcții ale stupului în detaliu
Hive acceptă diferite tipuri de date care nu se regăsesc în alte sisteme de baze de date. include o hartă, matrice și struct. Hive are unele funcții încorporate pentru a îndeplini mai multe funcții matematice și aritmetice într-un scop special. Funcțiile din stup pot fi clasificate în următoarele tipuri. Sunt funcții încorporate și funcții definite de utilizator.
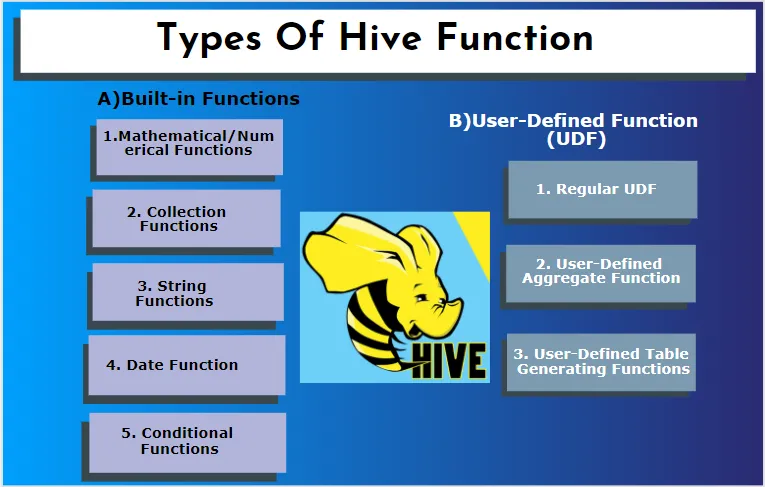
A) Funcții încorporate
Aceste funcții extrag date din tabelele stupului și procesează calculele. Unele dintre funcțiile încorporate sunt:
1. Funcții matematice / numerice
Aceste funcții sunt utilizate în principal pentru calcule matematice. Aceste funcții sunt utilizate în interogările SQL.
| Numele funcției | Exemplu | Descriere |
| ABS (dublu x) | Stup> selectați ABS (-200) din tmp; | Se va returna valoarea absolută a unui număr. |
| CEIL (dublu x) | Stup> selectați CEIL (8.5) din tmp; | Va obține cel mai mic număr întreg mai mare sau egal cu valoarea x. |
| Rand (), rand (int seed) | Stup> selectați Rand () din tmp;
Rand (0-9) | Se returnează un număr aleatoriu, depinde de valoarea semințelor, numerele aleatoare generate ar fi deterministe. |
| Pow (dublu x, dublu y) | Stup> selectați Pow (5, 2) din tmp; | Se returnează x valoarea ridicată la puterea y. |
| PISCĂ (dublu y) | Stup> selectați FLOOR (11.8) din tmp; | Acesta returnează un număr întreg maxim mai mic sau egal pentru a da valoarea y. |
| EXP (dublu a) | Stup> selectați Exp (30) din tmp; | Se va întoarce valoarea exponentă a 30. valorile algoritmului natural. |
| PMOD (int a, int b) | Stup> selectați PMOD (2, 4) din tmp; | Dă modulul pozitiv al numărului. |
2. Funcții de colectare
Depunerea tuturor elementelor împreună și returnarea elementelor unice depind de tipul de date inclus.
| Numele funcției | Exemplu | Descriere |
| Map_values (Map) | Hive> selectați valori Map ('hi', 45) | Acesta aduce elemente de tablă neordonate. |
| Mărime (hartă) | Stup> selectare dimensiune (hartă) | Returnează numărul de elemente din harta tipului de date. |
| Array_contains (Array b) | Hive> selectați array_contains (a (10)) | Returnează TRUE dacă tabloul conține valoarea. |
| Sort_array (Array a) | Hive> select sort_array ((10, 3, 6, 1, 7)) | Sortează tabloul de intrare în ordine crescătoare în funcție de ordonarea naturală a elementelor tabloului și returnează valoarea. |
3. Funcții cu șiruri
Utilizarea funcțiilor șir analiza datelor se realizează excelent.
| Split (string s, string pat) | Rive> selectați split ('educba ~ hive ~ Hadoop, ' ~ ') output ("educba", "stup", "Hadoop") | Împărțește șirul în jurul expresiilor pat și returnează un tablou. |
| load (string s, int Len, string pad) | Stup> selecta sarcină ('EDUCBA', 6, 'H') | Întoarce șiruri cu căptușire dreaptă cu lungimea șirului. (caracter pad). |
| Lungime (coardă) | Stup> selectează lungimea („educba”) | Această funcție returnează lungimea șirului. |
| Rtrim (șirul a) | Hive> selectați rtrim ('TOPIC');
Rezultat: „Subiect” | Întoarce rezultatul prin tăierea spațiilor de la capetele drepte. |
| Concat (șir m, șir n) | Hive> select concat ('date', 'ware') Rezultat: Dataware | Rezultă șirul prin concatenarea a două șiruri, ceea ce poate lua orice număr de intrări. |
| Invers (șiruri) | Stup> selectați invers ('mobil') | Returnează rezultatul unui șir inversat. |
4. Funcția datei
Este necesar să existe un format de date în stup pentru a preveni eroarea nulă la ieșire. Este necesară compatibilitatea de date pentru a merge cu funcțiile de date introduse din stup.
| Unix_timestamp (data șirului, modelul șirului) | Hive> selectați marcajul de timp Unix_ ('2019-06-08', 'aaaa-mm-dd'); Rezultat: 124576 400 timp: 0, 146 secunde | Această funcție returnează data la formatul specific și restituie secunde între ora și data Unix. |
| Unix_timestamp (data șirului) | Hive> selectați marcajul de timp Unix_ ('2019-06-08 09:20:10', 'aaaa-mm-dd'); | Întoarce data în format „aaaa-MM-dd HH: mm: ss” în cronograma Unix. |
| Ora (data șirului) | Hive> selectează ora ('2019-06-08 09:20:10'); Rezultat: 09 ore | Se întoarce ora de marcă |
5. Funcții condiționale
| Dacă (test boolean, valoarea T adevărat, t fals) | Rive> selectați IF (1 = 1, 'TRUE', 'FALSE') ca IF_CONDITION_TEST; | Verifică cu condiția dacă valoarea este true returnează 1 și false returnează 0. |
| Nu este nul (b) | Hive> Select nu este nul (null); | Aceasta nu aduce declarații nule. dacă null returnează fals. |
| Coalesce (valoare1, valoare2) | Exemplu: stup> selectare coalesce (Null, null, 4, null, 6). se întoarce 4. | Primează în primul rând valori nu nule din lista de valori. |
B) Funcția definită de utilizator (UDF)
Hive utilizează funcții specifice utilizatorului în funcție de cerințele clientului, este scris în programarea Java. Este implementat de două interfețe și anume API simplă și API complexă. Acestea sunt invocate din interogarea stupului. Trei tipuri de UDF:
1. UDF regulat
Funcționează pe o masă cu un singur rând. Este creat prin crearea unei clase Java, apoi ambalarea lor într-un fișier .jar, următorul pas este verificarea cu un traseu de clasă stup. apoi executându-le în cele din urmă într-o interogare stup.
2. Funcție agregată definită de utilizator
Ei folosesc funcții agregate ca avg / mediu prin implementarea a cinci metode init (), iterare (), parțiale (), îmbinare (), terminare ().
3. Funcții de generare a tabelelor definite de utilizator
Funcționează cu un singur rând într-un tabel și are ca rezultat mai multe rânduri.
Concluzie
În concluzie, am învățat cum să lucrăm în platforma stupului cu funcții încorporate și funcții definite de utilizator în detaliu prin acest articol. Majoritatea organizațiilor au programator și dezvoltator SQL pentru a lucra la procesul serverului, dar un stup apache este un instrument puternic care îi ajută să folosească cadrul Hadoop fără cunoștințe prealabile despre programe și reducerea hărții. Hive ajută noii utilizatori să înceapă și să exploreze analiza datelor fără bariere.
Articole recomandate
Acesta este un ghid pentru funcția stup. Aici vom discuta Conceptul, două tipuri diferite de funcții și sub-funcții în stup. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Funcții de șir de top în stup
- Întrebări la interviu stup
- Ce este RMAN Oracle?
- Ce este modelul cascadă?
- Introducere în Arhitectura stupului
- Ordinul stupului Prin