

Introducere în tehnicile de știință a datelor
În lumea de azi în care datele sunt noul aur, există diferite tipuri de analiză disponibile pentru o întreprindere. Rezultatul unui proiect de știință a datelor variază foarte mult în funcție de tipul de date disponibile și, prin urmare, impactul este și variabil. Întrucât există multe alte tipuri de analiză disponibile, devine imperativ să înțelegeți ce tehnici de bază trebuie selectate. Scopul esențial al tehnicilor de știință a datelor este nu numai căutarea de informații relevante, ci și detectarea legăturilor slabe care tind să facă modelul să funcționeze slab.
Ce este știința datelor?
Știința datelor este un domeniu care se răspândește pe mai multe discipline. Incorporează metode științifice, procese, algoritmi și sisteme pentru a aduna cunoștințe și a lucra la aceleași. Acest câmp include o varietate de genuri și reprezintă o platformă comună pentru unificarea conceptelor de statistici, analize de date și învățare automată. În acest sens, cunoașterea teoretică a statisticilor, împreună cu datele și tehnicile în timp real în învățarea mașinii lucrează mână în mână pentru a obține rezultate fructuoase pentru afacere. Folosind diferite tehnici utilizate în știința datelor, noi în lumea de azi putem presupune o mai bună luare a deciziilor care altfel ar putea lipsi din ochiul și mintea umană. Amintiți-vă că mașina nu uită niciodată! Pentru a maximiza profitul într-o lume bazată pe date, magia științei datelor este un instrument necesar.
Diferite tipuri de tehnici de știință a datelor
În următoarele câteva paragrafe, vom analiza tehnicile comune de știință a datelor utilizate în fiecare alt proiect. Deși uneori tehnica de știință a datelor poate fi specifică problemelor de afaceri și s-ar putea să nu se încadreze în categoriile de mai jos, este perfect în regulă să le denumim ca tipuri diverse. La un nivel înalt, împărțim tehnicile în Supervisat (știm impactul țintei) și Nesupervizat (Nu știm despre variabila țintă pe care încercăm să o atingem). La nivelul următor, tehnicile pot fi împărțite în funcție de
- Rezultatul pe care l-am obține sau care este intenția problemei de afaceri
- Tipul de date utilizate.
Să ne uităm mai întâi la segregarea bazată pe intenție.
1. Învățare nesupravegheată
- Detectarea anomaliilor
În acest tip de tehnică, identificăm orice apariție neașteptată în întregul set de date. Deoarece comportamentul diferă de întâmplările reale ale unei date, presupunerile de bază sunt:
- Apariția acestor cazuri este foarte mică în număr.
- Diferența de comportament este semnificativă.
Algoritmii de anomalie sunt explicați, cum ar fi Pădurea de izolare, care oferă un scor pentru fiecare înregistrare dintr-un set de date. Acest algoritm este un model bazat pe arbori. Folosind acest tip de tehnică de detectare și popularitatea acesteia, acestea sunt utilizate în diferite cazuri de afaceri, de exemplu, vizualizări pe pagina web, rata de schimbare, venit pe clic, etc. În graficul de mai jos putem explica cum arată anomalia.
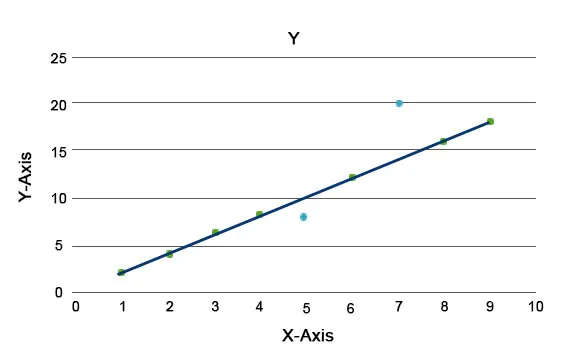
Aici, cele albastre reprezintă o anomalie din setul de date. Acestea diferă de la linia de tendință obișnuită și sunt mai puțin întâlnite.
- Analiza de clustering
Prin această analiză, sarcina principală este separarea întregului set de date în grupuri, astfel încât tendința sau trăsăturile din punctele de date ale unui grup să fie destul de similare între ele. În terminologia științelor datelor le numim cluster. De exemplu, în activitatea de vânzare cu amănuntul, există un plan de scalare a afacerii și devine imperativ să știm cum s-ar comporta noii clienți într-o nouă regiune pe baza datelor din trecut. Devine imposibil să concepeți o strategie pentru fiecare individ dintr-o populație, dar va fi util să încorporați populația în grupuri, astfel încât strategia să fie eficientă într-un grup și să fie scalabilă.
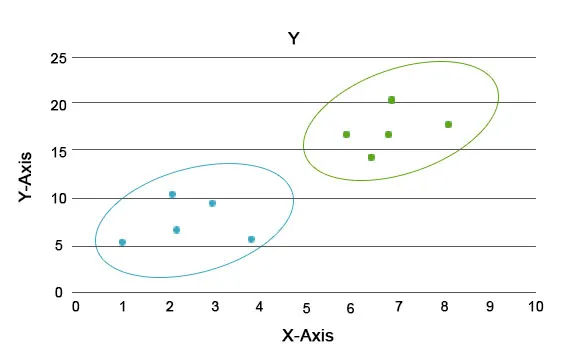
Aici culorile albastru și portocaliu sunt diferite clustere care au trăsături unice în sine.
- Analiza de asociere
Această analiză ne ajută să construim relații interesante între elemente dintr-un set de date. Această analiză descoperă relațiile ascunse și ajută la reprezentarea articolelor din setul de date sub formă de reguli de asociere sau seturi de elemente frecvente. Regula de asociere este defalcată în 2 etape:
- Generare frecventă de articole: În acest caz, este generat un set în care elementele care apar frecvent sunt configurate împreună.
- Generarea regulilor: Setul construit mai sus este trecut prin diferite straturi de formare a regulilor pentru a construi o relație ascunsă între ele. De exemplu, setul se poate încadra în probleme conceptuale sau de implementare sau în aplicații. Acestea sunt apoi ramificate în arbori respectivi pentru a construi regulile de asociere.
De exemplu, APRIORI este un algoritm de construire a regulilor de asociere.
2. Învățare supravegheată
- Analiza regresiei
În analiza de regresie, definim variabila dependentă / țintă și restul variabilelor ca variabile independente și, în cele din urmă, ipoteză modul în care una / mai multe variabile independente influențează variabila țintă. Regresia cu o singură variabilă independentă se numește univariat și cu mai mult de una este cunoscută sub numele de multivariate. Să înțelegem folosirea univariatei și apoi scala pentru multivariate.
De exemplu, y este variabila țintă și x 1 este variabila independentă. Deci, din cunoștința dreptei, putem scrie ecuația ca y = mx 1 + c. Aici „m” determină cât de puternic este influențat y de x1. Dacă „m” este foarte aproape de zero, înseamnă că cu o modificare în x 1, y nu este puternic afectat. Cu un număr mai mare de 1, impactul devine mai puternic și o modificare mică în x 1 duce la o variație mare în y. Similar cu univariate, în multivariate se poate scrie ca y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Aici impactul fiecărei variabile independente este determinat de „m” corespunzător.
- Analiza clasificării
Similar analizei de clustering, algoritmii de clasificare sunt construiți având variabila țintă sub formă de clase. Diferența dintre clustering și clasificare constă în faptul că în grupări nu știm din ce grup se încadrează punctele de date, în timp ce în clasificare știm din ce grup aparține. Și diferă de regresie din perspectiva că numărul grupurilor ar trebui să fie un număr fix spre deosebire de regresie, este continuu. Există o mulțime de algoritmi în analiza clasificării, de exemplu, mașini de suport pentru vector, regresie logistică, arbori de decizie etc.
Concluzie
În concluzie, înțelegem că fiecare tip de analiză este vast în sine, dar aici putem oferi o aromă mică tehnicilor diferite. În următoarele note, le-am lua pe fiecare în parte și am intra în detalii despre sub-tehnici diferite utilizate în fiecare tehnică părinte.
Articol recomandat
Acesta este un ghid pentru tehnicile de știință a datelor. Aici discutăm introducerea și diferite tipuri de tehnici în știința datelor. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Instrumente pentru știința datelor | Top 12 Instrumente
- Algoritmi de știință a datelor cu tipuri
- Introducere în cariera de știință a datelor
- Data Science vs vizualizarea datelor
- Exemple de regresie multivariată
- Creați arborele de decizie cu avantaje
- Scurtă privire a ciclului de știință a datelor