
Ce este GLM în R?
Modelele liniare generalizate este un subset de modele de regresie liniară și acceptă în mod eficient distribuțiile care nu sunt normale. Pentru a sprijini acest lucru, se recomandă utilizarea funcției glm (). GLM funcționează bine cu o variabilă atunci când variația nu este constantă și distribuită normal. O funcție de legătură este definită pentru a transforma variabila de răspuns pentru a se potrivi cu modelul adecvat. Un model LM este realizat atât cu familia, cât și cu formula. Modelul GLM are trei componente cheie numite aleatoare (probabilitate), sistematic (predictor liniar), componentă de legătură (pentru funcția logit). Avantajul folosirii glm este că au flexibilitatea modelului, nu este nevoie de o varianță constantă și acest model se potrivește estimării maxime a probabilității și a raporturilor sale. În acest subiect, vom învăța despre GLM în R.
Funcția GLM
Sintaxa: glm (formulă, familie, date, ponderi, subset, Start = nul, model = ADEVĂRAT, metodă = ””…)
Aici tipurile de familie (include tipurile de model) includ binomul, Poisson, Gaussian, gama, cvas. Fiecare distribuție efectuează o utilizare diferită și poate fi utilizată fie în clasificare cât și în predicție. Și atunci când modelul este gaussian, răspunsul ar trebui să fie un număr întreg întreg.
Iar când modelul este binomial, răspunsul ar trebui să fie clase cu valori binare.
Iar atunci când modelul este Poisson, răspunsul ar trebui să fie non-negativ cu o valoare numerică.
Iar când modelul este gamma, răspunsul ar trebui să fie o valoare numerică pozitivă.
glm.fit () - Pentru a se potrivi unui model
Lrfit () - indică regresie logistică potrivită.
actualizare () - ajută la actualizarea unui model.
anova () - este un test opțional.
Cum se creează GLM în R?
Aici vom vedea cum se poate crea un model liniar ușor generalizat cu date binare folosind funcția glm (). Și continuând setul de date Arbori.
Exemple
// Importarea unei bibliotecilibrary(dplyr)
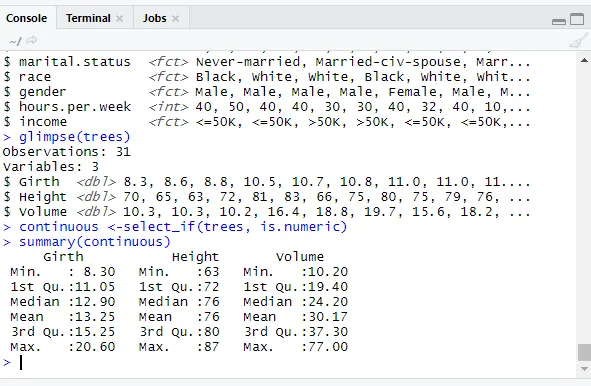
glimpse(trees)

Pentru a vedea valorile categorice sunt alocați factori.
levels(factor(trees$Girth))
// Verificarea variabilelor continue
library(dplyr)
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Includerea setului de date arbore în R căutare Pathattach (copaci)
x<-glm(Volume~Height+Girth)
x
ieşire:
| Apel: glm (formulă = Volum ~ Înălțime + Circumferință)
coeficienţi: (Interceptarea) Înălțimea în jurul -57.9877 0.3393 4.7082 Grade de libertate: 30 total (adică nul); 28 Reziduu Deviant nul: 8106 Abatere reziduală: 421.9 AIC: 176.9 |
summary(x)
| Apel:
glm (formula = Volumul ~ Inaltime + Circumferinta) Reziduuri pentru devianță: Min. 1 Q Median 3Q Max -6.4065 -2.6493 -0.2876 2.2003 8.4847 coeficienţi: Stimate Std. Eroarea valorii t Pr (> | t |) (Interceptare) -57.9877 8.6382 -6.713 2.75e-07 *** Înălțime 0, 3393 0, 1302 2, 607 0, 0145 * Circuitul 4.7082 0.2643 17.816 <2e-16 *** - Semni. coduri: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0, 1 '' 1 (Parametrul de dispersie pentru familia gaussiană a fost 15.06862) Abatere nulă: 8106, 08 pe 30 de grade de libertate Abatere reziduală: 421, 92 pe 28 de grade de libertate AIC: 176.91 Numărul de iterații pentru scoruri de pescuit: 2 |
Ieșirea funcției de sumar indică apelurile, coeficienții și reziduurile. Răspunsul de mai sus indică faptul că atât înălțimea cât și circumferința circumferinței nu sunt semnificative, deoarece probabilitatea acestora este mai mică de 0, 5. Și există două variante de devianță numite nule și reziduale. În cele din urmă, punctajul de pescuit este un algoritm care rezolvă problemele de probabilitate maximă. Cu binomul, răspunsul este un vector sau matrice. cbind () este utilizat pentru a lega vectorii de coloană dintr-o matrice. Și pentru a obține informații detaliate despre rezumatul potrivirii se folosește.
Pentru a face Like test hood este executat următorul cod.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
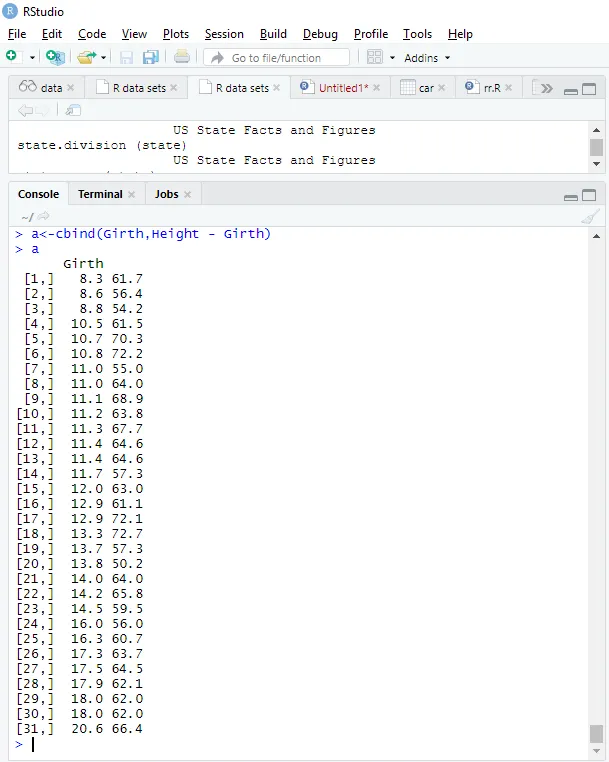
Potrivirea modelului
a<-cbind(Height, Girth - Height)
> a
rezumat (arbori)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
Pentru a obține abaterea standard corespunzătoare
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
În continuare, ne referim la variabila de răspuns de numărare pentru a modela o potrivire de răspuns bună. Pentru a calcula acest lucru, vom folosi setul de date USAccDeath.
Haideți să introducem următoarele fragmente în consola R și să vedem cum se realizează numărul de ani și pătratul anului pe ei.
data("USAccDeaths")
force(USAccDeaths)
// Pentru a analiza anul 1973-1978.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Apel:
glm (formula = numar ~ an + anSqr, familie = "poisson", date = disc) Reziduuri pentru devianță: Min. 1 Q Median 3Q Max -22.4344 -6.4401 -0.0981 6.0508 21.4578 coeficienţi: Stimate Std. Valoarea eroare z Pr (> | z |) (Intercepție) 9.187e + 00 3.557e-03 2582, 49 <2e-16 *** anul -7.207e-03 2.354e-04 -30, 62 <2e-16 *** anul trimestrul 8.841e-05 3.221e-06 27.45 <2e-16 *** - Semni. coduri: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0, 1 '' 1 (Parametrul de dispersie pentru familia Poisson a fost 1) Abatere nulă: 7357, 4 pe 71 de grade de libertate Abatere reziduală: 6358, 0 pe 69 de grade de libertate AIC: 7149.8 Numărul de iterații cu punctaj pentru pescuit: 4 |
Pentru a verifica cea mai bună potrivire a modelului, se poate utiliza următoarea comandă pentru a găsi
reziduurile pentru test. Din rezultatul de mai jos, valoarea este 0.
1 - pchisq(deviance(a1), df.residual(a1))
Utilizarea familiei QuasiPoisson pentru o mai mare variație a datelor date
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Apel:
glm (formula = număr ~ an + anSqr, familie = "quasipoisson", date = disc) Reziduuri pentru devianță: Min. 1 Q Median 3Q Max -22.4344 -6.4401 -0.0981 6.0508 21.4578 coeficienţi: Stimate Std. Eroarea valorii t Pr (> | t |) (Interceptare) 9.187e + 00 3.417e-02 268.822 <2e-16 *** anul -7.207e-03 2.261e-03 -3.188 0.00216 ** anul trimestrul 8.841e-05 3.095e-05 2.857 0.00565 ** - (Parametrul de dispersie pentru familia quasipoisson a fost 92.28857) Abatere nulă: 7357, 4 pe 71 de grade de libertate Abatere reziduală: 6358, 0 pe 69 de grade de libertate AIC: NA Numărul de iterații cu punctaj pentru pescuit: 4 |
Compararea Poisson cu valoarea AIC binomică diferă semnificativ. Pot fi analizate prin precizie și raportul de rechemare. Următorul pas este să verificați că variația reziduurilor este proporțională cu media. Apoi putem complota folosind biblioteca ROCR pentru îmbunătățirea modelului.
Concluzie
Prin urmare, ne-am concentrat pe un model special numit model liniar generalizat, care ajută la focalizarea și estimarea parametrilor modelului. Este în primul rând potențialul unei variabile de răspuns continuu. Și am văzut cum glm se potrivește cu un pachet R încorporat. Ele sunt cele mai populare abordări pentru măsurarea datelor de numărare și un instrument robust pentru tehnicile de clasificare utilizate de un om de știință de date. Limbajul R, desigur, ajută la îndeplinirea funcțiilor matematice complicate
Articole recomandate
Acesta este un ghid pentru GLM în R. Aici discutăm funcția GLM și Cum să creăm GLM în R cu exemple de arbore și date de arbore. De asemenea, puteți consulta articolul următor pentru a afla mai multe -
- R Limbaj de programare
- Arhitectura Big Data
- Regresie logistică în R
- Locuri de muncă pentru analizele de date mari
- Poisson Regression in R | Implementarea regresiei Poisson