

Introducere în analiza regresiei liniare
Adesea este confuz să înveți un concept care face parte chiar din viața noastră de zi cu zi. Dar aceasta nu este o problemă, ne putem ajuta și să ne dezvoltăm pentru a învăța din activitățile noastre de zi cu zi doar analizând lucrurile și nu ne simți frică să nu punem întrebări. De ce prețul afectează cererea de bunuri, de ce modificarea ratei dobânzii afectează oferta de bani. La toate acestea se poate răspunde printr-o abordare simplă cunoscută sub numele de regresie liniară. Singura complexitate pe care o simțim în timp ce se ocupă de analiza regresiei liniare este identificarea variabilelor dependente și independente.
Trebuie să găsim ce afectează ceea ce și jumătate din problemă este rezolvată. Trebuie să vedem dacă prețul sau cererea se afectează reciproc. După ce am aflat care este variabila independentă și variabila dependentă, este bine să mergem pentru analiza noastră. Există mai multe tipuri de analiză de regresie disponibile. Această analiză depinde de variabilele disponibile.
Cele 3 tipuri de analiză de regresie
Aceste trei analize de regresie au cazuri de utilizare maximă în lumea reală, altfel există mai mult de 15 tipuri de analize de regresie. Tipurile de analiză de regresie despre care vom discuta sunt:
- Analiza regresiei liniare
- Analiza regresiei liniare multiple
- Regresie logistică
În acest articol, ne vom concentra pe analiza regresiei liniare simple. Această analiză ne ajută să identificăm relația dintre factorul independent și factorul dependent. În cuvinte mai simple, modelul de regresie ne ajută să aflăm că modul în care schimbările factorului independent afectează factorul dependent. Acest model ne ajută în mai multe moduri precum:
- Este un model statistic simplu și puternic
- Ne va ajuta să facem predicție și prognoză
- Ne va ajuta să luăm o decizie de afaceri mai bună
- Ne va ajuta să analizăm rezultatele și să corectăm erorile
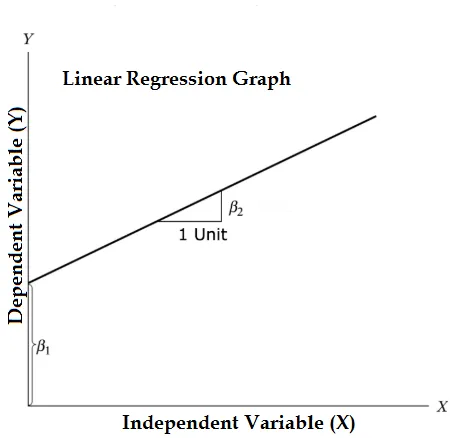
Ecuația regresiei liniare și împărțiți-o în părți relevante
Y = β1 + β2X + ϵ
- Unde β1 în terminologia matematică cunoscută sub denumirea de interceptare și β2 în terminologia matematică cunoscută sub denumirea de pantă. De asemenea, sunt cunoscuți sub denumirea de coeficienți de regresie. ϵ este termenul de eroare, este partea din Y modelul de regresie nu este în măsură să explice.
- Y este o variabilă dependentă (alți termeni care sunt folosiți în mod interschimbabil pentru variabile dependente sunt variabilă de răspuns, regres și variabilă măsurată, variabilă observată, variabilă care răspunde, variabilă explicată, variabilă rezultat, variabilă experimentală și / sau variabilă de ieșire).
- X este o variabilă independentă (regresori, variabilă controlată, manipulată o variabilă, variabilă explicativă, variabilă de expunere și / sau variabilă de intrare).
Problemă: Pentru a înțelege ce este analiza de regresie liniară, luăm setul de date „Mașini” care vine implicit în directoarele R. În acest set de date, există 50 de observații (practic rânduri) și 2 variabile (coloane). Numele coloanelor sunt „Dist” și „Viteză”. Aici trebuie să vedem impactul asupra variabilelor de distanță datorate variabilelor de viteză. Pentru a vedea structura datelor putem executa un cod Str (set de date). Acest cod ne ajută să înțelegem structura setului de date. Aceste funcționalități ne ajută să luăm decizii mai bune, deoarece avem o imagine mai bună în mintea noastră despre structura setului de date. Acest cod ne ajută să identificăm tipul de seturi de date.
Cod:

În mod similar, pentru a verifica punctele de control statistice ale setului de date, putem folosi codul sumar (mașini). Acest cod furnizează o gamă medie, mediană a setului de date, pe care cercetătorul îl poate folosi în timp ce se ocupă cu problema.
ieşire:
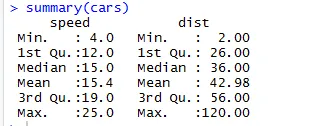
Aici putem vedea rezultatele statistice ale fiecărei variabile pe care o avem în setul de date.
Reprezentarea grafică a seturilor de date
Tipurile de reprezentare grafică care vor acoperi aici sunt și de ce:
- Scatter Plot: Cu ajutorul graficului, putem vedea în ce direcție merge modelul nostru de regresie liniară, dacă există dovezi puternice care să demonstreze sau nu modelul nostru.
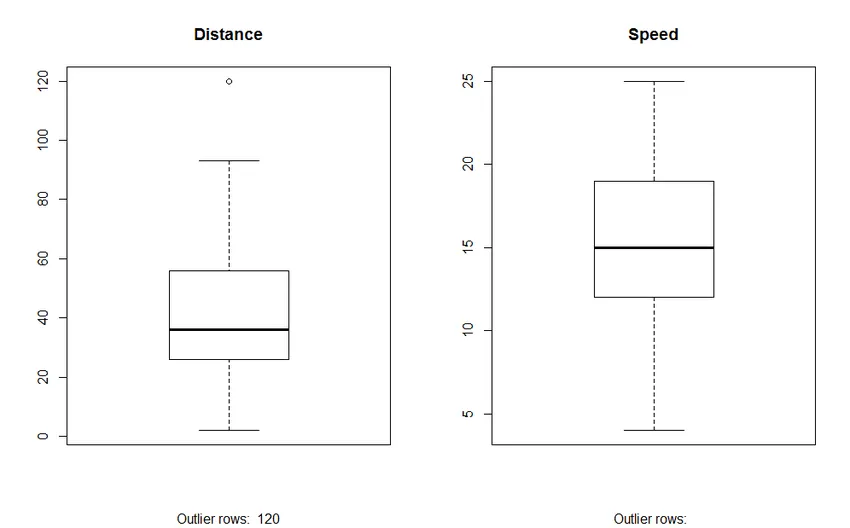
- Caseta de complot: Ne ajută să găsim evidenți.
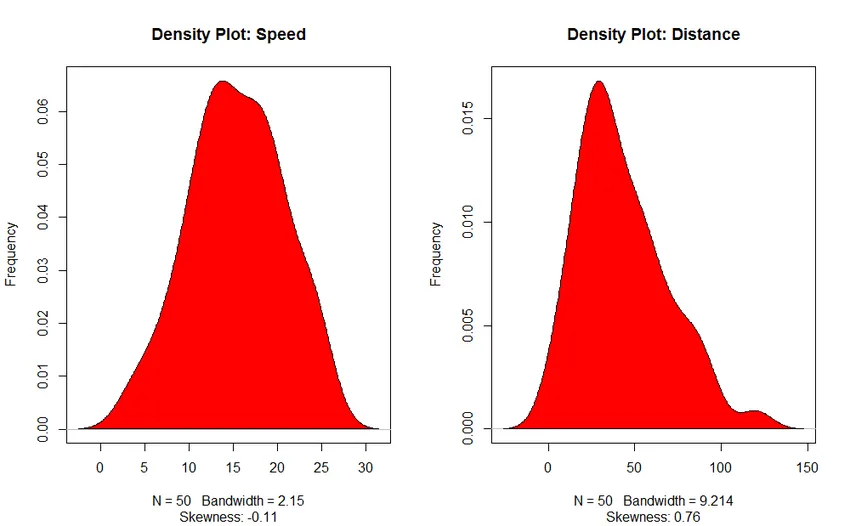
- Density Plot: Ajută-ne să înțelegem distribuția variabilei independente, în cazul nostru, variabila independentă este „Speed”.
Avantajele reprezentării grafice
Aici sunt următoarele avantaje:
- Ușor de înțeles
- Ne ajută să luăm decizii rapide
- Analiza comparativa
- Mai puțin efort și timp
1. Scatter Plot: Va ajuta la vizualizarea oricărei relații între variabila independentă și variabila dependentă.
Cod:

ieşire:
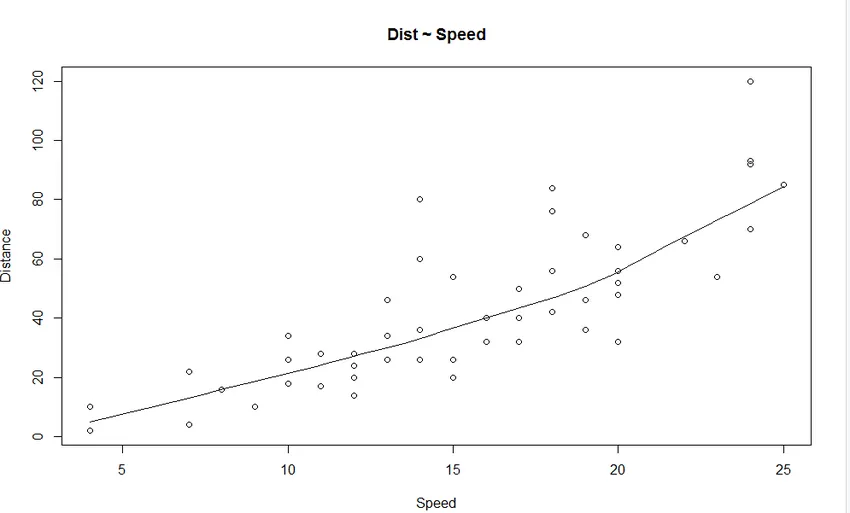
Putem observa din grafic o relație în creștere liniară între variabila dependentă (Distanța) și variabila independentă (Viteză).
2. Caseta complot: Caseta de complot ne ajută să identificăm valorile din seturile de date. Avantajele utilizării unui complot box sunt:
- Afișarea grafică a locației și a răspândirii variabilelor.
- Ne ajută să înțelegem simțimea și simetria datelor.
Cod:

ieşire:
3. Density Plot (pentru a verifica normalitatea distribuției)
Cod:
 ieşire:
ieşire:
Analiza corelațiilor
Această analiză ne ajută să găsim relația dintre variabile. Există în principal șase tipuri de analize de corelație.
- Corelație pozitivă (0, 01 până la 0, 99)
- Corelație negativă (de la -0, 99 la -0, 01)
- Fără corelare
- Corelare perfectă
- Corelație puternică (o valoare mai apropiată de ± 0, 99)
- Corelație slabă (o valoare mai apropiată de 0)
Scatter complot ne ajută să identificăm care tipuri de seturi de date de corelație au între ele și codul pentru găsirea corelației este

ieşire:
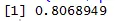
Aici avem o corelație pozitivă puternică între Viteză și Distanță, ceea ce înseamnă că au o relație directă între ei.
Modelul de regresie liniară
Aceasta este componenta de bază a analizei, mai devreme încercam și testam lucrurile dacă setul de date pe care îl avem este suficient de logic pentru a rula o astfel de analiză sau nu. Funcția pe care intenționăm să o utilizăm este lm (). Această funcție conține două elemente care sunt Formula și Datele. Înainte de a atribui acea variabilă este dependentă sau independentă, trebuie să fim foarte siguri de asta, deoarece întreaga noastră formulă depinde de asta.
Formula arată astfel,
Regresie liniară <- lm (Variabilă dependentă ~ Variabilă independentă, date = Date.Frame)
Cod:

ieşire:
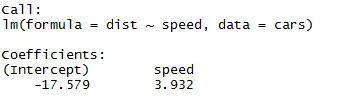
După cum ne putem aminti din segmentul de mai sus al articolului, ecuația de regresie liniară este:
Y = β1 + β2X + ϵ
Acum vom încadra informațiile pe care le-am obținut din codul de mai sus în această ecuație.
dist = −17.579 + 3.932 ∗ viteză
Numai că găsirea ecuației de regresie liniară nu este suficientă, trebuie să verificăm și statisticile sale semnificative. Pentru aceasta, trebuie să trecem un cod „Rezumat” pe modelul nostru de regresie liniară.
Cod:

ieşire:

Există mai multe modalități de a verifica semnificația statistică a unui model, aici folosim metoda valorii P. Putem considera un model adecvat statistic atunci când valoarea P este mai mică decât nivelul statistic semnificativ predeterminat, care este ideal 0, 05. În tabelul nostru de rezumat (linia_regresie) putem vedea că valoarea P este sub 0, 05, deci putem concluziona că modelul nostru este semnificativ statistic. După ce suntem siguri de modelul nostru, putem folosi setul nostru de date pentru a prezice lucrurile.
Articole recomandate
Acesta este un ghid pentru analiza regresiei liniare. Aici discutăm cele trei tipuri de analiză de regresie liniară, reprezentarea grafică a seturilor de date cu avantaje și modele de regresie liniară. Puteți, de asemenea, să parcurgeți alte articole conexe pentru a afla mai multe-
- Formula de regresie
- Testare de regresie
- Regresia liniară în R
- Tipuri de tehnici de analiză a datelor
- Ce este analiza de regresie?
- Cele mai importante diferențe de regresie față de clasificare
- Top 6 diferențe de regresie liniară față de regresia logistică