
Introducere în Arhitectura stupului
Arhitectura stupului este construită pe vârful ecosistemului Hadoop. Hive are frecvent interacțiuni cu Hadoop. Apache Hive face față atât cu sistemul de baze de date SQL de domeniu, cât și cu Map-reduce. Aplicațiile stup pot fi scrise în diferite limbi precum Java, Python. Arhitectura Hive arată cum se scrie limbajul de interogare a stupului și modul în care interacțiunile dintre programator se realizează folosind interfața liniei de comandă. Limbajul de interogare Hive face treaba de a converti toate sarcinile de cluster Hadoop prin map-reduce. După cum știam cu toții ca Hadoop să proceseze date mari într-un mediu distribuit și formează un cadru open-source. Cu stupul, este flexibil să gestionați și să executați interogarea și un bun suporter să îndeplinească funcții precum încapsulare, interogări ad-hoc. Acest articol oferă o scurtă introducere în arhitectura stupului care se află pe stratul Hadoop pentru a efectua rezumarea datelor mari.
Arhitectura stupului cu componentele sale
Hive joacă un rol major în analiza datelor și integrarea informațiilor de afaceri și suportă formate de fișiere precum fișier text, fișier rc. Hive folosește un sistem distribuit pentru a procesa și executa interogări, iar stocarea se face în final pe disc și în final este procesată folosind un cadru pentru reducerea hărții. Rezolvă problema de optimizare găsită în harta de reducere a mapării și de efectuare a stupului, care sunt explicate clar în fluxul de lucru. Aici un meta-magazin stochează informații despre schemă. Un cadru numit Apache Tez este proiectat pentru performanța interogărilor în timp real.
Componentele majore ale stupului sunt prezentate mai jos:
- Clienți stupi
- Servicii de stup
- Depozitare stup (Meta Storage)
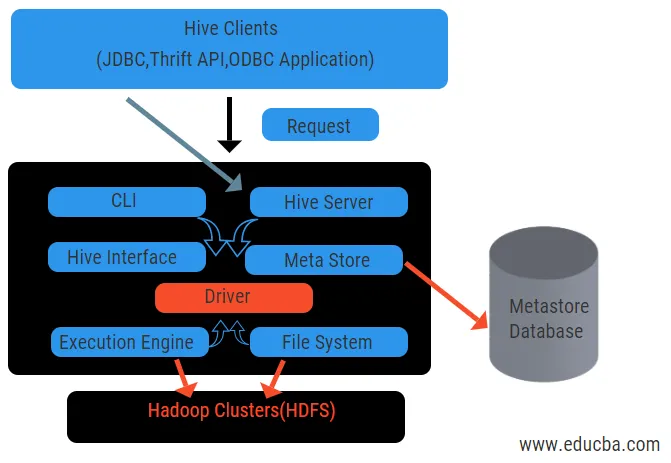
Diagrama de mai sus arată arhitectura stupului și elementele sale componente.
Clienții stupului:
Acestea includ aplicația Thrift pentru a executa comenzi ușoare ale stupului, care sunt disponibile pentru python, ruby, C ++ și drivere. Aceste aplicații client beneficiază pentru executarea de interogări în stup. Hive are trei tipuri de categorizare a clienților: clienți Thrift, JDBC și ODBC.
Servicii stup:
Pentru a procesa toate interogările stupului are diverse servicii. Toate funcțiile sunt ușor de definit de către utilizator în stup. Să vedem pe scurt toate aceste servicii:
- Interfață de linie de comandă (User Interface): Permite interacțiunea dintre utilizator și stup, o coajă implicită. Oferă o GUI pentru executarea liniei de comandă a stupului și a perspectivei stupului. De asemenea, putem folosi interfețe web (HWI) pentru a trimite interogările și interacțiunile cu un browser web.
- Driver Hive: Acesta primește interogări de la diferite surse și clienți, cum ar fi serverul Thrift, și stochează și preluează pe driverul ODBC și JDBC, care sunt conectate automat la stup. Această componentă face analize semantice privind vizualizarea tabelelor din metastarea care analizează o interogare. Driverul ia ajutorul compilatorului și îndeplinește funcții precum un analizor, Planificator, Executarea lucrărilor MapReduce și optimizatorul.
- Compilator: Analiza și procesul semantic al interogării este realizat de compilator. Acesta transformă interogarea într-un arbore de sintaxă abstractă și din nou în DAG pentru compatibilitate. Optimizatorul, la rândul său, împarte sarcinile disponibile. Sarcina executantului este de a rula sarcinile și de a monitoriza programul de conducte al sarcinilor.
- Motor de execuție: toate întrebările sunt procesate de un motor de execuție. Planurile de etapă DAG sunt executate de motor și ajută la gestionarea dependențelor dintre etapele disponibile și la executarea acestora pe o componentă corectă.
- Metastore: acționează ca un depozit central pentru a stoca toate informațiile structurate ale metadatelor, de asemenea este un aspect important pentru stup, deoarece are informații precum tabele și detalii de partiționare și stocarea fișierelor HDFS. Cu alte cuvinte, vom spune că metastore acționează ca un spațiu de nume pentru tabele. Metastore este considerat a fi o bază de date separată care este împărtășită și de alte componente. Metastore are două piese numite serviciu și stocare în întârziere.
Modelul de date stup este structurat în Partiții, găleți, tabele. Toate acestea pot fi filtrate, pot avea chei de partiție și pentru a evalua interogarea. Interogarea Hive funcționează pe cadrul Hadoop, nu pe baza de date tradițională. Serverul Hive este o interfață între interogările unui client la distanță. Motorul de execuție este complet încorporat într-un server stup. În procesul de detectare puteți găsi aplicația stup în învățarea mașinii, informații despre afaceri.
Fluxul de lucru al stupului:
Hive funcționează în două tipuri de moduri: modul interactiv și modul non-interactiv. Modul anterior permite tuturor comenzilor stupului să meargă direct la shell-ul stupului, în timp ce tipul ulterior execută cod în modul consolei. Datele sunt împărțite în partiții care se împart în bucăți. Planurile de execuție se bazează pe agregarea și înclinarea datelor. Un avantaj suplimentar al utilizării stupului este acela că prelucrează cu ușurință o scară largă de informații și are mai multe interfețe de utilizator.
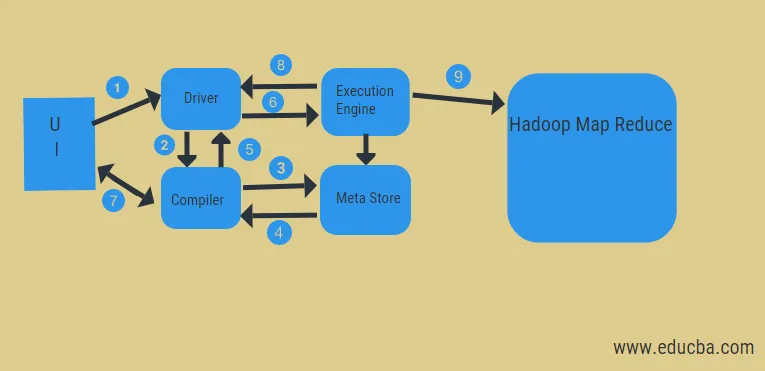
Din diagrama de mai sus, putem vedea o privire a fluxului de date în stup cu sistemul Hadoop.
Pașii includ:
- executați interogarea din UI
- obțineți un plan din etapele DAG pentru sarcinile șoferului
- primiți o solicitare de metadate de la meta-store
- trimiteți metadate de la compilator
- trimiterea planului înapoi șoferului
- Executați planul în motorul de execuție
- preluarea rezultatelor pentru interogarea utilizatorului adecvat
- trimiterea rezultatelor bidirecțional
- procesarea motorului de execuție în HDFS cu rezultatele map-reduce și preluare din nodurile de date create de trackerul de lucru. acționează ca un conector între stup și Hadoop.
Sarcina motorului de execuție este de a comunica cu noduri pentru a obține informațiile stocate în tabel. Aici operațiile SQL cum ar fi create, drop, alter sunt efectuate pentru a accesa tabelul.
Concluzie:
Am trecut prin arhitectura Hive și fluxul lor de lucru, stupul realizează practic cantitate de date petabyte și, prin urmare, este un pachet de depozite de date pe platforma Hadoop. Întrucât stupul este o alegere bună pentru gestionarea volumului mare de date, ajută la pregătirea datelor cu ghidul interfeței SQL pentru a rezolva problemele MapReduce. Apache hive este un instrument ETL pentru procesarea datelor structurate. Cunoașterea funcționării arhitecturii stupului îi ajută pe oameni să înțeleagă principiul funcționării stupului și are un început bun cu programarea stupului.
Articole recomandate:
Acesta a fost un ghid pentru Arhitectura stupului. Aici vom discuta despre arhitectura stupului, diferite componente și fluxul de lucru al stupului. este posibil să vă uitați și la următoarele articole pentru a afla mai multe-
- Arhitectura Hadoop
- Utilizări ale rubinului
- Ce este C ++
- Ce este baza de date MySQL
- Ordinul stupului Prin