

Introducere pentru a vă înscrie în Spark SQL
După cum știm, unirile în SQL sunt folosite pentru a combina date sau rânduri din două sau mai multe tabele bazate pe un câmp comun între ele. În acest subiect, vom învăța despre Join in Spark SQL Join in Spark SQL.
În Spark SQL, Dataframe sau Dataset sunt o structură tabulară în memorie având rânduri și coloane distribuite pe mai multe noduri. Ca și tabelele SQL normale, putem efectua, de asemenea, operațiuni de unire pe Dataframe sau Dataset prezente în Spark SQL pe baza unui câmp comun între ele.
Există diferite tipuri de operații Join disponibile în SQL. În funcție de cazul de utilizare a afacerii, facem alegerea operațiunii Join. În secțiunea următoare, vom demonstra fiecare tip de unire cu exemplu.
Tipuri de înscriere în Spark SQL
Următoarele tipuri de uniri disponibile în Spark SQL:
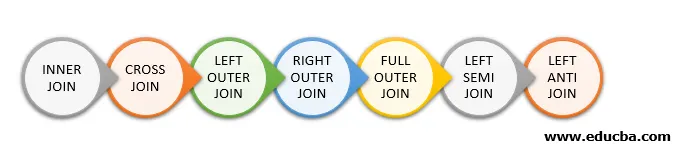
- ÎNSCRIE-TE INTERIOR
- CROSS JOIN
- ÎNCHIRIATEA EXTERIORĂ DE STÂNGĂ
- ÎNREGISTRARE DREPTULUI
- ÎNREGISTRARE COMPLETĂ
- ÎNCHEI SEMI ÎNCHIS
- ÎNCHIRI ANTI ÎNCHEI
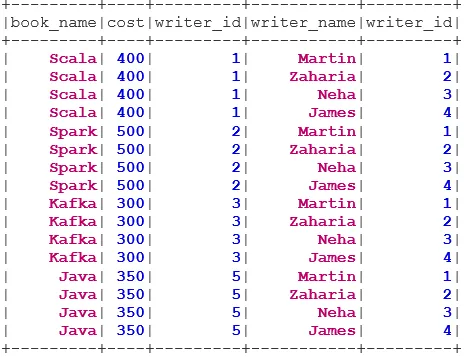
Exemplu de creare a datelor
Vom folosi următoarele date pentru a demonstra diferitele tipuri de uniri:
Set de date pentru carte:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Set de date Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Tipuri de îmbinări
Mai jos sunt menționate 7 tipuri diferite de uniri:
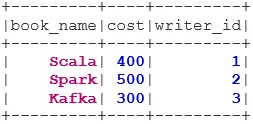
1. ÎNSCRIERE INTERNA
INNER JOIN returnează setul de date care are rândurile care au valori potrivite în ambele seturi de date, adică valoarea câmpului comun va fi aceeași.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
CROSS JOIN returnează setul de date care este numărul de rânduri din primul set de date înmulțit cu numărul de rânduri din al doilea set de date. Un astfel de rezultat se numește Produs cartezian.
Premisă: Pentru a utiliza o alăturare încrucișată, spark.sql.crossJoin.enabled trebuie să fie setat pe true. În caz contrar, excepția va fi aruncată.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. ÎNCHIRIATEA EXTERIORĂ DE STÂNGĂ
LEFT OUTER JOIN returnează setul de date care conține toate rândurile din setul de date din stânga și rândurile potrivite din setul de date din dreapta.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. ÎNREGISTRARE DREPTULUI
RIGHT OUTER JOIN returnează setul de date care conține toate rândurile din setul de date din dreapta și rândurile potrivite din setul de date din stânga.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. ÎNTREPRINDEREA COMPLETĂ
FULL OUTER JOIN returnează setul de date care conține toate rândurile atunci când există o potrivire în setul de date din stânga sau din dreapta.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. ÎNCHEI SEMI ÎNCHIS
LEFT SEMI JOIN returnează setul de date care conține toate rândurile din setul de date din stânga având corespondența lor în setul de date din dreapta. Spre deosebire de LEFT OUTER JOIN, setul de date returnat din LEFT SEMI JOIN conține doar coloanele din setul de date din stânga.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. ÎNCHIRI ANTI STÂNG
ANTI SEMI JOIN returnează setul de date care conține toate rândurile din setul de date din stânga care nu au potrivirea lor în setul de date drept. De asemenea, conține doar coloanele din setul de date din stânga.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Concluzie - Alăturați-vă la Spark SQL
Alăturarea datelor este una dintre cele mai comune și importante operațiuni pentru îndeplinirea cazurilor noastre de utilizare a afacerilor. Spark SQL acceptă toate tipurile fundamentale de uniri. În timp ce ne înscriem, trebuie să luăm în considerare și performanța, deoarece pot necesita transferuri mari de rețea sau chiar să creăm seturi de date peste capacitatea noastră de a ne ocupa. Pentru îmbunătățirea performanței, Spark folosește optimizatorul SQL pentru a ordona sau împinge filtrele. Spark restricționează, de asemenea, unirea periculoasă i. e CROSS JOIN. Pentru a utiliza o alăturare încrucișată, spark.sql.crossJoin.enabled trebuie să fie setat la true în mod explicit.
Articole recomandate
Acesta este un ghid pentru înscrierea în Spark SQL. Aici discutăm diferitele tipuri de uniri disponibile în Spark SQL cu Exemplul. De asemenea, vă puteți uita la articolul următor.
- Tipuri de uniri în SQL
- Tabel în SQL
- Interogare SQL Insert
- Tranzacții în SQL
- Filtre PHP | Cum se validează introducerea utilizatorului folosind diverse filtre?