
Prezentare generală a algoritmilor rețelei neuronale
- Să știm mai întâi ce înseamnă o rețea neuronală? Rețelele neuronale sunt inspirate de rețelele neuronale biologice din creier sau putem spune sistemul nervos. A generat o mulțime de entuziasm și cercetările continuă în continuare pe acest subset de învățare automată în industrie.
- Unitatea de bază de calcul a unei rețele neuronale este un neuron sau un nod. Primește valori de la alți neuroni și calculează ieșirea. Fiecare nod / neuron este asociat cu greutatea (w). Această greutate este dată pe importanța relativă a acelui anumit neuron sau nod.
- Deci, dacă luăm f ca funcție de nod, atunci funcția de nod f va oferi ieșire așa cum se arată mai jos: -
Ieșirea neuronului (Y) = f (w1.X1 + w2.X2 + b)
- În cazul în care w1 și w2 au greutate, X1 și X2 sunt intrări numerice, în timp ce b este prejudecata.
- Funcția de mai sus f este o funcție neliniară numită și funcție de activare. Scopul său de bază este de a introduce neliniaritatea, deoarece aproape toate datele din lumea reală sunt neliniare și dorim ca neuronii să învețe aceste reprezentări.
Algoritmi diferiți ai rețelei neuronale
Să analizăm acum patru algoritmi de rețele neuronale diferite.
1. Coborârea gradientului
Este unul dintre cei mai populari algoritmi de optimizare în domeniul învățării automate. Este utilizat în timp ce antrenează un model de învățare automată. În cuvinte simple, se folosește practic pentru a găsi valori ale coeficienților care reduce pur și simplu funcția de cost cât mai mult posibil. În primul rând, începem prin definirea unor valori ale parametrilor și apoi folosind calculul începem să reglăm iterativ valorile astfel încât funcția pierdută este redusă.
Acum, să venim la partea ce este gradient ?. Deci, un gradient înseamnă că, în mare măsură, ieșirea oricărei funcții se va schimba dacă micșorăm intrarea puțin sau, cu alte cuvinte, o putem apela la panta. Dacă panta este abruptă, modelul va învăța mai repede în mod similar, un model nu va mai învăța când panta este zero. Acest lucru se datorează faptului că este un algoritm de minimizare care minimizează un algoritm dat.
Mai jos formula pentru găsirea poziției următoare este prezentată în cazul coborârii gradientului.
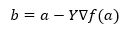
Unde b este următoarea poziție
a este poziția curentă, gama este o funcție de așteptare.
Deci, după cum puteți vedea coborârea în gradient este o tehnică foarte sonoră, dar există multe zone în care coborârea în gradient nu funcționează corect. Mai jos sunt prezentate câteva dintre acestea:
- Dacă algoritmul nu este executat în mod corespunzător, atunci putem întâmpina ceva precum problema dispariției gradientului. Acestea apar atunci când gradientul este prea mic sau prea mare.
- Problemele apar atunci când aranjarea datelor prezintă o problemă de optimizare non-convexă. Gradient decent funcționează numai cu probleme care sunt problema optimizată convex.
- Unul dintre factorii foarte importanți pe care trebuie să îi căutați în timpul aplicării acestui algoritm este resursele. Dacă avem mai puțină memorie alocată aplicației, ar trebui să evităm algoritmul de coborâre a gradientului.
2. Metoda lui Newton
Este un algoritm de optimizare de ordinul doi. Se numește un al doilea ordin, deoarece folosește matricea Hessiană. Așadar, matricea Hessiană nu este altceva decât o matrice pătrată a derivatelor parțiale de ordinul doi ale unei funcții valorice scalare. În algoritmul de optimizare a metodei lui Newton, se aplică la prima derivată a unei funcții dublu diferențiable f, astfel încât să poată găsi rădăcinile / puncte staționare. Haideți să trecem acum la etapele cerute de metoda lui Newton pentru optimizare.
Mai întâi evaluează indicele de pierderi. Apoi verifică dacă criteriile de oprire sunt adevărate sau false. Dacă este fals, atunci calculează direcția de antrenament a lui Newton și rata de antrenament și apoi îmbunătățește parametrii sau greutățile neuronului și din nou același ciclu continuă. Deci, puteți spune că este nevoie de mai puțini pași în comparație cu coborârea gradientului pentru a obține minimul. valoarea funcției. Deși durează mai puțini pași în comparație cu algoritmul de coborâre a gradientului, totuși, acesta nu este utilizat pe scară largă, deoarece calculul exact al hessianului și inversul său sunt foarte scumpe din punct de vedere al calculului.
3. Gradient conjugat
Este o metodă care poate fi privită ca ceva între descendența gradientului și metoda lui Newton. Principala diferență este că accelerează convergența lentă pe care o asociem în general cu descendență în gradient. Un alt fapt important este faptul că poate fi utilizat atât pentru sisteme liniare, cât și pentru cele neliniare și este un algoritm iterativ.
A fost dezvoltat de Magnus Hestenes și Eduard Stiefel. Așa cum am menționat deja mai sus, că produce convergență mai rapidă decât descendența gradientului, Motivul pentru care este capabil să o facă este că în algoritmul Conjugat Gradient, căutarea se face împreună cu direcțiile conjugate, datorită cărora converg mai rapid decât algoritmii de descendență. Un punct important de remarcat este faptul că γ se numește parametru conjugat.
Direcția de antrenament este resetată periodic la negativul gradientului. Această metodă este mai eficientă decât descendența în gradient în formarea rețelei neuronale, deoarece nu necesită matricea Hessian care crește sarcina de calcul și, de asemenea, convergență mai repede decât descendența gradientului. Este adecvat să se utilizeze în rețele neuronale mari.
4. Metoda Quasi-Newton
Este o abordare alternativă la metoda lui Newton, deoarece suntem conștienți acum că metoda lui Newton este costisitoare din punct de vedere al calculului. Această metodă rezolvă aceste dezavantaje într-o măsură astfel încât, în loc să calculeze matricea Hessian și apoi să calculeze invers invers, această metodă creează o aproximare la Hessian invers la fiecare iterație a acestui algoritm.
Acum, această aproximare este calculată folosind informațiile din prima derivată a funcției de pierdere. Așadar, putem spune că este probabil cea mai potrivită metodă de a face față rețelelor mari, deoarece economisește timp de calcul și, de asemenea, este mult mai rapid decât descendența sau metoda gradientului conjugat.
Concluzie
Înainte de a încheia acest articol, Să comparăm viteza de calcul și memoria pentru algoritmii menționați mai sus. În conformitate cu cerințele de memorie, coborârea în gradient necesită cea mai mică memorie și este, de asemenea, cea mai lentă. Dimpotrivă, metoda lui Newton necesită mai multă putere de calcul. Prin urmare, luând în considerare toate acestea, metoda Quasi-Newton este cea mai potrivită.
Articole recomandate
Acesta a fost un ghid pentru algoritmii rețelei neuronale. Aici vom discuta, de asemenea, privire de ansamblu a algoritmului rețelei neuronale împreună cu patru algoritmi diferiți. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Învățare de mașini și rețea neuronală
- Cadre de învățare automată
- Rețele neuronale vs învățare profundă
- K- Înseamnă algoritmul de clustering
- Ghid pentru clasificarea rețelei neuronale