

Introducere în Arhitectura Hadoop
Hadoop Architecture este un cadru open source care ajută la procesarea cu ușurință a seturilor de date mari. Ajută la crearea de aplicații care procesează date uriașe cu mai multă viteză. Utilizează conceptele de calcul distribuite în care datele sunt distribuite pe diferite noduri ale unui cluster. Aplicațiile care sunt create cu Hadoop folosesc calculatoarele de bază. Aceste computere sunt disponibile cu ușurință pe piață la tarife ieftine. Acest rezultat obține o putere de calcul mai mare la un cost redus. Toate datele prezente în Hadoop se află pe HDFS în loc de un sistem de fișiere local. HDFS este un sistem de fișiere distribuit Hadoop. Acest model se bazează pe Locația datelor unde logica de calcul este trimisă nodurilor prezente într-un cluster care conține datele. Această logică nu este decât o logică care compila programul.
Arhitectura Hadoop
Ideea de bază a acestei arhitecturi este că întreaga stocare și procesare se face în doi pași și prin două moduri. Primul pas este procesarea, care se realizează prin programarea Map reduce, iar al doilea pas este stocarea datelor care se fac pe HDFS. Are o arhitectură master-slave pentru stocare și procesare de date. Nodul principal pentru stocarea datelor în Hadoop este nodul nume. Există, de asemenea, un nod principal care lucrează în monitorizare și paralel prelucrarea datelor, folosind Hadoop Map Reduce. Sclavii sunt alte mașini din clusterul Hadoop care ajută la stocarea datelor și, de asemenea, efectuează calcule complexe. Fiecare nod sclav a fost atribuit cu un tracker de sarcini și un nod de date are un tracker de job care ajută la rularea proceselor și la sincronizarea lor eficientă. Acest tip de sistem poate fi configurat fie pe cloud, fie pe premisă. Nodul Nume este un singur punct de eșec atunci când nu se execută pe modul de disponibilitate ridicată. Arhitectura Hadoop are, de asemenea, prevederi pentru menținerea unui nod stand by Name, pentru a proteja sistemul de eșecuri. Anterior, au existat noduri secundare de nume care au acționat ca o copie de rezervă atunci când nodul de nume principal a fost redus.
FSimage și Editare jurnal
FSimage and Edit Log asigură persistența Metadatelor sistemului de fișiere pentru a ține pasul cu toate informațiile și nodul de nume stochează metadatele în două fișiere. Aceste fișiere sunt FSimage și jurnalul de editare. Sarcina FSimage este de a păstra o imagine completă a sistemului de fișiere la un moment dat. Modificările care sunt făcute în mod constant într-un sistem trebuie să fie înregistrate. Aceste modificări incrementale, cum ar fi redenumirea sau adăugarea detaliilor la fișier, sunt stocate în jurnalul de editare. Cadrul oferă o opțiune mai bună decât crearea unui nou FSimage de fiecare dată, o opțiune mai bună putând stoca datele în timp ce un nou fișier pentru FSimage. FSimage creează o instantanee nouă de fiecare dată când se fac modificări Dacă nodul Nume nu reușește, poate restabili starea anterioară. Nodul de nume secundar poate, de asemenea, să-și actualizeze copia ori de câte ori există modificări în FSimage și editează jurnalele. Astfel, se asigură că, deși nodul este scăzut, în prezența unui nod secundar nu va exista nicio pierdere de date. Nodul nume nu necesită ca aceste imagini să fie reîncărcate pe nodul secundar.
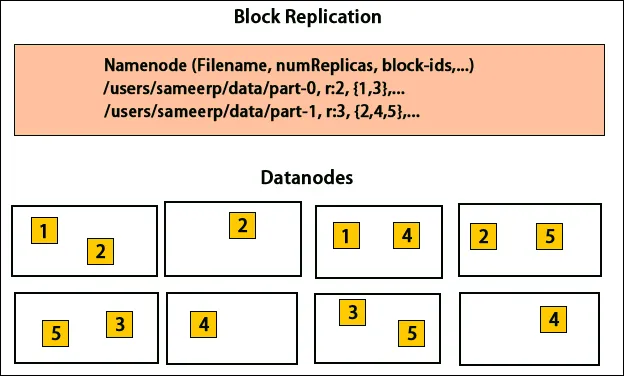
Replicarea datelor
HDFS este proiectat pentru procesarea rapidă a datelor și furnizarea de date fiabile. Stochează date pe mașini și în clustere mari. Toate fișierele sunt stocate într-o serie de blocuri. Aceste blocuri sunt replicate pentru toleranță la erori. Dimensiunea blocului și factorul de replicare pot fi decise de utilizatori și configurate conform cerințelor utilizatorului. În mod implicit, factorul de replicare este 3. Factorul de replicare poate fi specificat la momentul creării fișierelor și poate fi modificat ulterior. Toate deciziile cu privire la aceste replici sunt luate de nodul nume. Nodul nume continuă să trimită bătăi cardiace și să raporteze blocul la intervale regulate pentru toate nodurile de date din cluster. Primirea bătăilor inimii implică faptul că nodul de date funcționează corect. Raportul bloc specifică lista tuturor blocurilor prezente pe nodul de date.
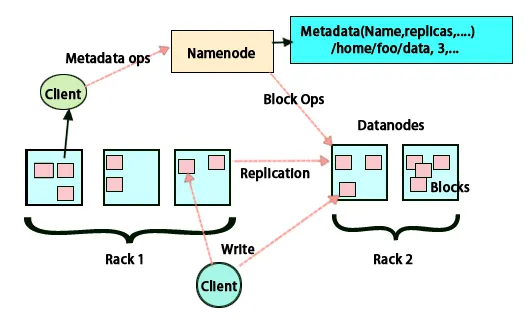
Plasament de replici
Amplasarea de replici este o sarcină foarte importantă în Hadoop pentru fiabilitate și performanță. Toate blocurile de date diferite sunt plasate pe diferite rafturi. Implementarea plasării replicilor se poate face conform fiabilității, disponibilității și utilizării lățimii de bandă a rețelei. Clusterul de calculatoare poate fi răspândit pe diferite rafturi. Nu mai mult de două noduri pot fi plasate pe același suport. A treia replică trebuie plasată pe un rack diferit pentru a asigura o mai mare fiabilitate a datelor. Cele două noduri de pe rack comunică prin comutatoare diferite. Nodul nume are ID-ul rack pentru fiecare nod de date. Dar plasarea tuturor nodurilor pe diferite rafturi previne pierderea oricăror date și permite utilizarea lățimii de bandă de la mai multe rafturi. De asemenea, reduce traficul inter-rack și îmbunătățește performanța. De asemenea, șansa de eșec a rack-ului este foarte mică comparativ cu cea a defectării nodului. Reduce lățimea de bandă totală a rețelei atunci când datele sunt citite din două rachete unice, mai degrabă decât din trei.
Reduceți harta
Map Reduce este utilizat pentru procesarea datelor stocate pe HDFS. Scrie date distribuite în aplicații distribuite, ceea ce asigură procesarea eficientă a unor cantități mari de date. Procesează pe grupe mari și necesită marfă care este fiabilă și tolerantă la erori. Nucleul Map-reduce poate fi trei operațiuni precum maparea, colectarea perechilor și amestecarea datelor rezultate.
Concluzie - Arhitectură Hadoop
Hadoop este un cadru open source care ajută într-un sistem tolerant la erori. Poate stoca cantități mari de date și ajută la stocarea datelor fiabile. Cele două părți ale stocării datelor în HDFS și procesarea acestora prin hartă reduc ajutorul pentru funcționarea corectă și eficientă. Are o arhitectură care ajută la gestionarea tuturor blocurilor de date și are, de asemenea, cea mai recentă copie prin stocarea în FSimage și editarea jurnalelor. Factorul de replicare ajută, de asemenea, la a avea copii de date și a le recupera înapoi, ori de câte ori există un eșec. De asemenea, HDFS mută fișierele eliminate în directorul coșului de gunoi pentru o utilizare optimă a spațiului.
Articole recomandate
Acesta a fost un ghid pentru Arhitectura Hadoop. Aici am discutat despre Arhitectură, Reducerea hartii, plasarea replicilor, replicarea datelor. Puteți parcurge și alte articole sugerate pentru a afla mai multe -
- Deveniți dezvoltator Hadoop
- Introducere în Android
- Ce este Tableau? | O imagine de ansamblu
- Ce este MapReduce în Hadoop?