
Introducere în eliminarea înapoi
Pe măsură ce omul și mașina se îndreaptă spre evoluția digitală, diverse mașini de tehnică sunt contabile pentru a se obține nu numai antrenate, dar instruite inteligent pentru a ieși cu o mai bună recunoaștere a obiectelor din lumea reală. O astfel de tehnică introdusă mai devreme, numită „Eliminare înapoi”, care intenționa să favorizeze caracteristici indispensabile, în timp ce eradicează caracteristici nugatorii pentru a oferi o optimizare mai bună într-o mașină. Toată competența recunoașterii obiectelor de către mașină este proporțională cu ceea ce are în vedere.
Caracteristicile care nu au nici o referință la ieșirea prevăzută trebuie descărcate de pe mașină și se încheie prin eliminare înapoi. Buna precizie și complexitatea în timp a recunoașterii oricărui obiect cuvânt real de către Mașină depind de învățarea sa. Deci eliminarea înapoi joacă rolul său rigid pentru selecția caracteristicilor. Consideră rata de dependență a caracteristicilor față de variabila dependentă găsește semnificația apartenenței sale la model. Pentru a acredita acest lucru, verifică rata calculată cu un nivel de semnificație standard (să zicem 0.06) și ia o decizie pentru selectarea caracteristicilor.
De ce facem o înlăturare înapoi ?
Trăsăturile neesențiale și redundante propulsează complexitatea logicii mașinilor. Devorează resursele timpului și modelului inutil. Deci tehnica Afore menționată joacă un rol competent pentru a forja modelul spre simplu. Algoritmul cultivă cea mai bună versiune a modelului prin optimizarea performanțelor sale și trunchierea resurselor sale numite utilizabile.
Reduce caracteristicile cele mai puțin notabile ale modelului care provoacă zgomot în luarea deciziei liniei de regresie. Trăsăturile obiectelor irelevante pot duce la clasificare greșită și predicție. Caracteristicile irelevante ale unei entități pot constitui un dezechilibru în model cu privire la alte caracteristici semnificative ale altor obiecte. Eliminarea înapoi favorizează adaptarea modelului la cel mai bun caz. Prin urmare, se recomandă eliminarea înapoi spre un model.
Cum să aplici eliminarea înapoi?
Eliminarea înapoi începe cu toate variabilele caracteristice, testând-o cu variabila dependentă în conformitate cu o potrivire selectată a criteriului modelului. Începe să eradice acele variabile care deteriorează linia de regresie adecvată. Repetarea acestei ștergeri până când modelul obține o potrivire bună. Mai jos sunt pașii pentru a exersa eliminarea înapoi:
Pasul 1: Alegeți nivelul de semnificație corespunzător pentru a avea rezidența în modelul mașinii. (Ia S = 0, 06)
Pasul 2: Alimentați toate variabilele independente disponibile modelului cu privire la variabila dependentă și calculatorul înclinați și interceptați pentru a trasa o linie de regresie sau linie de montare.
Pasul 3: Traversezi toate variabilele independente care au cea mai mare valoare (Take I) una câte una și continuați cu toastul următor: -
a) Dacă I> S, executați pasul 4.
b) Eleste altfel și modelul este perfect.
Pasul 4: Eliminați acea variabilă aleasă și creșteți traversarea.
Pasul 5: forjează din nou modelul și calculează din nou panta și interceptarea liniei de montare cu variabile reziduale.
Etapele menționate anterior sunt rezumate în respingerea acelor caracteristici a căror rată de semnificație este mai mare decât valoarea de semnificație selectată (0, 06) pentru a sustrage supra-clasificarea și suprautilizarea resurselor care au fost observate ca o complexitate ridicată.
Merite și demersuri ale eliminării înapoi
Iată câteva merite și demersuri ale eliminării înapoi, prezentate mai jos în detaliu:
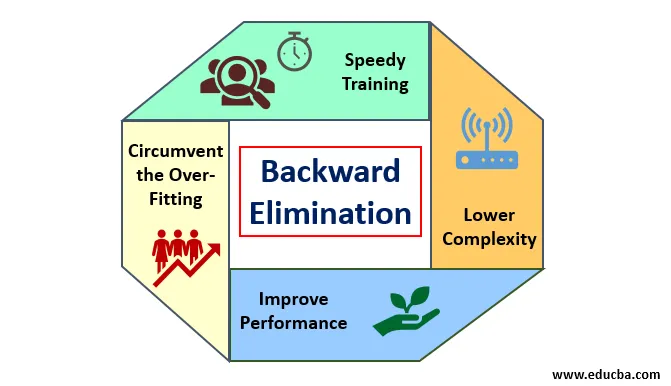
1. Merite
Meritele eliminării înapoi sunt următoarele:
- Pregătire rapidă: Mașina este instruită cu un set de caracteristici disponibile ale modelului care se realizează într-un timp foarte scurt dacă sunt eliminate funcțiile neesențiale din model. Pregătirea rapidă a setului de date intră în imagine doar atunci când modelul se ocupă de caracteristici semnificative și exclude toate variabilele de zgomot. Atrage o complexitate simplă pentru antrenament. Însă modelul nu trebuie să fie supus unei montări care apare din cauza lipsei caracteristicilor sau a probelor inadecvate. Caracteristica eșantionului trebuie să fie abundentă într-un model pentru cea mai bună clasificare. Timpul necesită pentru antrenarea modelului ar trebui să fie mai mic, păstrând exactitatea clasificării și rămânând fără o variabilă sub-predicție.
- Complexitate inferioară: Complexitatea modelului se întâmplă să fie ridicată dacă modelul are în vedere întinderea caracteristicilor, inclusiv zgomotul și caracteristicile fără legătură. Modelul consumă mult spațiu și timp pentru a procesa o asemenea gamă de funcții. Aceasta poate crește rata de acuratețe a recunoașterii modelului, dar rata poate conține și zgomot. Pentru a scăpa de o complexitate atât de ridicată a modelului, algoritmul de eliminare înapoi joacă un rol necesar prin retragerea caracteristicilor nedorite din model. Simplifică logica de procesare a modelului. Doar câteva caracteristici esențiale sunt suficiente pentru a se potrivi cu o precizie rezonabilă.
- Îmbunătățirea performanței: performanța modelului depinde de multe aspecte. Modelul suferă optimizare prin eliminarea înapoi. Optimizarea modelului este optimizarea setului de date utilizat pentru instruirea modelului. Performanța modelului este direct proporțională cu rata de optimizare a acestuia, care se bazează pe frecvența datelor semnificative. Procesul de eliminare înapoi nu este destinat să înceapă alterarea de la vreun predicator cu frecvență joasă. Dar începe doar modificarea datelor de înaltă frecvență, deoarece, în mare parte, complexitatea modelului depinde de acea parte.
- Circumventați supra-montarea: situația de montare se produce atunci când modelul are prea multe seturi de date și se realizează clasificarea sau predicția în care unii predicatori au zgomotul altor clase. În această montare, modelul trebuia să dea o precizie neașteptat de mare. În cazul montării excesive, modelul nu poate clasifica variabila din cauza confuziei create în logică din cauza prea multor condiții. Tehnica de eliminare inversă reduce caracteristicile străine pentru a evita situația de montare excesivă.
2. Demeritele
Demeritele de eliminare înapoi sunt următoarele:
- În metoda de eliminare înapoi, nu se poate afla care predicator este responsabil pentru respingerea altui predicator datorită atingerii nesemnificative. De exemplu, dacă predicatorul X are o semnificație suficient de bună pentru a locui într-un model după adăugarea predicatorului Y. Dar semnificația lui X este depășită atunci când un alt predicator Z intră în model. Așadar, algoritmul de eliminare înapoi nu este evident despre nicio dependență între doi predictori care se întâmplă în „Tehnica de selecție înainte”.
- După eliminarea oricărei caracteristici dintr-un model printr-un algoritm de eliminare înapoi, acea caracteristică nu poate fi selectată din nou. Pe scurt, eliminarea înapoi nu are o abordare flexibilă pentru a adăuga sau elimina caracteristici / predictori.
- Normele de selectare a valorii de semnificație (0, 06) în model sunt inflexibile. Eliminarea înapoi nu are o procedură flexibilă, care nu numai că alege, ci și schimbă valoarea nesemnificativă, așa cum este necesar pentru a obține cea mai bună potrivire într-un set de date adecvat.
Concluzie
Tehnica de eliminare înapoi a fost realizată pentru a ameliora performanța modelului și a optimiza complexitatea acestuia. Se folosește viu în regresii multiple, unde modelul se ocupă de setul de date extensiv. Este o abordare simplă și simplă, în comparație cu selecția înainte și validarea încrucișată în care s-a întâlnit supraîncărcare de optimizare. Tehnica de eliminare înapoi inițiază eliminarea caracteristicilor cu valoare semnificativă mai mare. Obiectivul său de bază este de a face modelul mai puțin complex și de a interzice situația de a se potrivi.
Articole recomandate
Acesta este un ghid pentru Eliminarea înapoi. Aici vom discuta despre cum să aplici eliminarea înapoi împreună cu meritele și demersurile. De asemenea, puteți consulta următoarele articole pentru a afla mai multe-
- Hyperparameter Machine Learning
- Gruparea în învățarea mașinilor
- Mașină virtuală Java
- Învățarea mașinii nesupravegheate