

Prezentare generală a tipurilor de clustering
Înainte de a învăța tipuri de clustering, să înțelegem ce este Clustering și de ce este atât de important în industria de învățare a mașinilor în acest moment.
Ce este Clustering? Clusteringul este un proces în care algoritmul împarte punctele de date într-un număr set de grupuri bazat pe principiul că puncte de date similare rămân aproape unul de celălalt și se încadrează în același grup.
De ce este atât de important acum? Să înțelegem că, văzând un exemplu, de exemplu, există un magazin online de îmbrăcăminte și doresc să-și înțeleagă mai bine clienții, astfel încât să își poată face strategia de publicitate mai eficientă. Nu este posibil ca aceștia să aibă un tip unic de strategie pentru fiecare client, în loc de asta, ceea ce pot face este să împartă clienții într-un anumit număr de grupuri (pe baza achizițiilor anterioare) și să aibă o strategie separată de grupuri separate. Acest lucru face ca afacerea să fie mai eficientă, acesta este motivul pentru care clusteringul este important în industrie acum.
Tipuri de clustering
Metodele generale de tehnici de clustering sunt clasificate în două tipuri, sunt metode Hard și metode soft. În metoda de clustering Hard, fiecare punct de date sau observație aparține unui singur cluster. În metoda de clustering soft, fiecare punct de date nu va aparține complet unui singur cluster, ci poate fi un membru al mai multor cluster, are un set de coeficienți de membru corespunzând probabilității de a se afla într-un anumit cluster.
În prezent, există diferite tipuri de metode de clustering în uz, aici în acest articol să vedem unele dintre cele importante precum clusteringul ierarhic, clusteringul de partiționare, clusteringul Fuzzy, clustering-ul bazat pe densitate și clustering-ul bazat pe modelul de distribuție. Acum să discutăm fiecare dintre acestea cu un exemplu:
1. Partajare Clustering
Partitionare Clustering-ul este un tip de tehnică de clustering, care împarte datele setate într-un număr set de grupuri. (De exemplu, Valoarea lui K în KNN și se va decide înainte de a antrena modelul). Poate fi numit și ca metodă bazată pe centroid. În această abordare, centrul de cluster (centroid) este format astfel încât distanța punctelor de date din acel grup să fie minimă atunci când este calculată cu alte centre de cluster. Un exemplu cel mai popular al acestui algoritm este algoritmul KNN. Așa arată un algoritm de clustering de partiționare
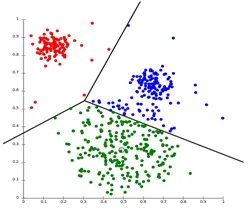
2. Gruparea Ierarhică
Clustering-ul Ierarhic este un tip de tehnică de clustering, care împarte acele date setate într-un număr de clustere, în care utilizatorul nu specifică numărul de clustere care trebuie generate înainte de instruirea modelului. Acest tip de tehnică de clustering este cunoscută și sub denumirea de metode bazate pe conectivitate. În această metodă, o simplă partajare a setului de date nu se va face, în timp ce ne oferă ierarhia clusterilor care se îmbină între ei după o anumită distanță. După ce gruparea ierarhică este făcută pe setul de date, rezultatul va fi o reprezentare bazată pe arbori a punctelor de date (Dendogramă), care sunt împărțite în clustere. Așa arată o grupare ierarhică după terminarea instruirii
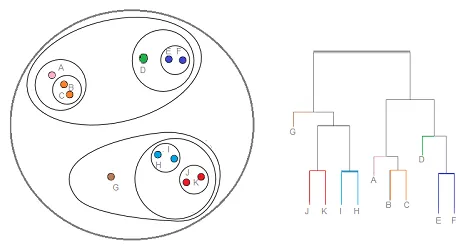
Link sursă: Agregare Ierarhică
În clusteringul de partiționare și clusterizarea ierarhică, o diferență principală pe care o putem observa este că în clusteringul de partiționare vom pre-specifica valoarea în câte clustere dorim să fie împărțite în setul de date și nu pre-specificăm această valoare în clusteringul ierarhic. .
3. Clustering bazat pe densitate
În această grupare, grupurile tehnice vor fi formate prin segregarea diferitelor regiuni de densitate bazate pe densități diferite în graficul de date. Clustering și aplicație spațială bazată pe densitate (DBSCAN) este cel mai utilizat algoritm în acest tip de tehnică. Ideea principală din spatele acestui algoritm este că ar trebui să existe un număr minim de puncte care să conțină în vecinătatea unei raze date pentru fiecare punct din cluster. Până în prezent, în tehnicile de clustering discutate mai sus, dacă observați amănunțit, putem observa un lucru obișnuit, în toate tehnicile care au forma clusterelor formate sunt sferice sau ovale sau concave. DBSCAN poate forma clustere în diferite forme, acest tip de algoritm este cel mai potrivit atunci când setul de date conține zgomot sau valori. Așa arată un algoritm de clustering spațial bazat pe densitate după pregătirea.
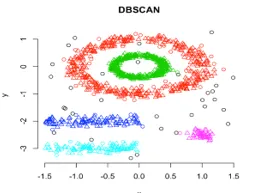
Link sursă: Clustering pe bază de densitate
4. Clustering bazat pe model de distribuție
În acest tip de clustering, grupurile tehnice sunt formate prin identificarea prin probabilitatea ca toate punctele de date din cluster să provină din aceeași distribuție (Normal, Gaussian). Cel mai popular algoritm în acest tip de tehnică este aglomerarea Expectation-Maximization (EM) folosind modele Gaussian Mixture (GMM).
Tehnicile normale de clustering, cum ar fi aglomerarea ierarhică și clusteringul de partiționare nu se bazează pe modele formale, KNN în compartimentarea clustering dă rezultate diferite cu valori K diferite. Deoarece KNN și KMN consideră media pentru centrul de cluster, nu este mai potrivit în unele cazuri cu modele de amestec Gaussian, presupunem că punctele de date sunt distribuite Gaussian, în acest fel avem doi parametri pentru a descrie forma medie a clusterilor și abaterea standard. În acest fel, pentru fiecare cluster este atribuită o distribuție Gaussiană, pentru a obține valorile optime ale acestor parametri (medie și abatere standard), se folosește un algoritm de optimizare denumit Maximizarea așteptărilor. Așa arată EM - GMM după antrenament.
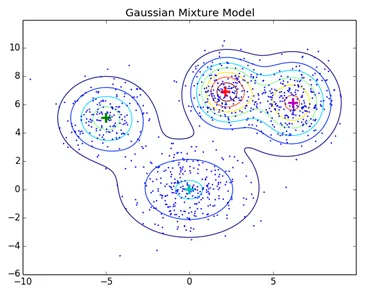
Link sursă: clustering bazat pe model de distribuție
5. Clustering fuzzy
Aparține unei ramuri a tehnicilor de clustering a metodelor soft, în timp ce toate tehnicile de clustering menționate mai sus aparțin tehnicilor de clustering a metodei dure. În acest tip de tehnică de clustering punctele sunt aproape de centru, poate o parte a celuilalt cluster într-un grad mai mare decât punctele de la marginea aceluiași cluster. Probabilitatea unui punct aparținând unui cluster dat este o valoare cuprinsă între 0 până la 1. Cel mai popular algoritm în acest tip de tehnică este FCM (Fuzzy C-înseamnă Algoritm) Aici, centroidul unui cluster este calculat ca media din toate punctele, ponderate de probabilitatea lor de apartenență la cluster.
Concluzie - Tipuri de clustering
Acestea sunt câteva dintre diferitele tehnici de clustering care sunt utilizate în prezent și în acest articol, am acoperit un algoritm popular în fiecare tehnică de clustering. Trebuie să alegem tipul de tehnologie pe care îl utilizăm, pe baza setului de date și a cerințelor pe care trebuie să le îndeplinim.
Articole recomandate
Acesta a fost un ghid pentru Tipuri de Clustering. Aici discutăm diferite tipuri de clustering cu exemple ale acestora. De asemenea, puteți arunca o privire la următoarele articole pentru a afla mai multe -
- Algoritmul de agregare ierarhică
- Gruparea în învățarea mașinilor
- Tipuri de algoritmi de învățare a mașinilor
- Tipuri de tehnici de analiză a datelor
- Cum să folosiți și să eliminați Ierarhia în Tableau?
- Ghid complet pentru tipurile de analiză a datelor