
Diferența dintre stup și HBase
Apache Hive și HBase sunt tehnologii de date mari bazate pe Hadoop. Amândoi obișnuiau să interogheze datele. Hive și HBase rulează pe Hadoop și diferă în funcționalitatea lor. Hive este diagrama SQL bazată pe hartă, în timp ce HBase acceptă doar MapReduce. HBase stochează date sub forma unor perechi de chei / valori sau familii de coloane, în timp ce Hive nu stochează date.
Diferențe de la cap la cap între Hive și HBase (Infografie)
Mai jos se află diferența de top 8 între Hive și HBase
Diferențe cheie între Hive și HBase
- Hbase este conform ACID, în timp ce stupul nu este.
- Hive acceptă criteriile de partiționare și filtrare pe baza formatului datei, în timp ce HBase acceptă partiționarea automată.
- Hive nu acceptă declarațiile de actualizare, în timp ce HBase le acceptă.
- Hbase este mai rapid în comparație cu Hive în preluarea datelor.
- Hive este utilizat pentru a prelucra date structurate, în timp ce HBase, deoarece este lipsit de schemă, poate procesa orice tip de date.
- Hbase este scalabil (orizontal) în comparație cu Hive.
- Hive analizează datele de pe HDFS cu suportul interogărilor SQL și apoi le transformă într-o hartă și reduc joburile, în timp ce în Hbase, deoarece este în timp real streaming, își îndeplinește în mod direct operațiunile pe baza de date repartizând tabele și familii de coloane.
- Atunci când venim la interogarea stupului de date, utilizăm un shell cunoscut sub numele de shell Hive pentru a emite comenzile, în timp ce HBase, deoarece este baza de date, vom folosi o comandă pentru a procesa datele din HBase.
- Pentru a merge la shell-ul Hive vom folosi stupul de comandă. După ce a dat acest lucru, va apărea ca stup>. În HBase, pur și simplu dăm ca Utilizare HBase.
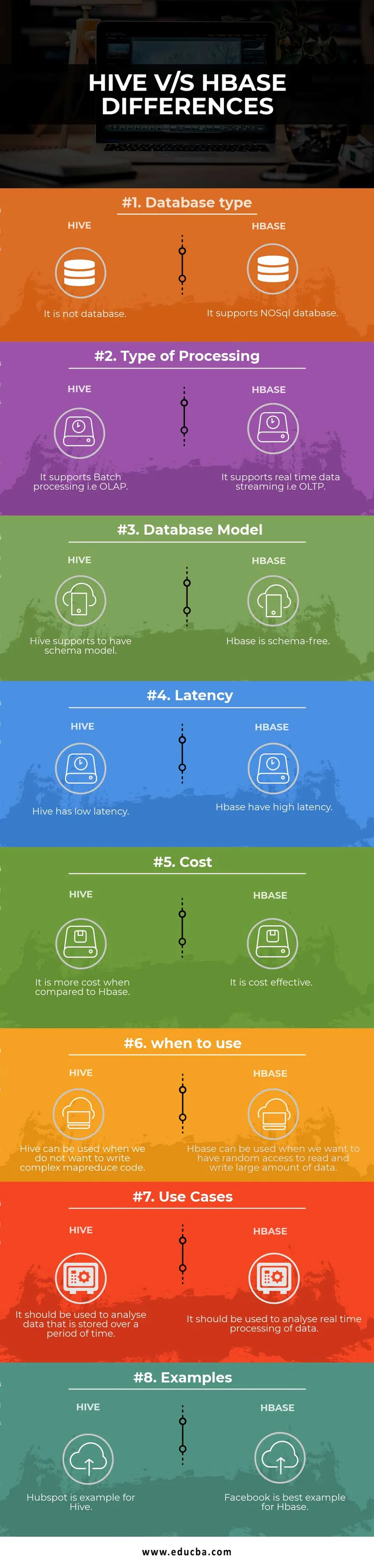
Tabelul de comparare Hive vs HBase
| Baza de comparație | Stup | Hbase |
| Tip de bază de date | Nu este o bază de date | Suporta baza de date NoSQL |
| Tipul procesării | Acceptă procesarea lotului, adică OLAP | Acceptă streaming de date în timp real, adică OLTP |
| Model de bază de date | Suportul stupului are un model de schemă | Hbase este lipsită de schemă |
| Latență | Stupul are latenta scazuta | Hbase are latență ridicată |
| Cost | Este mai costisitor în comparație cu HBase | Este rentabil |
| când să folosești | Stupul poate fi folosit atunci când nu dorim să scriem cod complex MapReduce | HBase poate fi utilizat atunci când dorim să avem acces aleatoriu pentru a citi și scrie o cantitate mare de date |
| Cazuri de utilizare | Ar trebui să fie utilizat pentru a analiza datele care sunt stocate pe o perioadă de timp | Ar trebui să fie utilizat pentru a analiza procesarea în timp real a datelor. |
| Exemple | Hubspot este un exemplu pentru Hive | Facebook este cel mai bun exemplu pentru Hbase |
Diferențe în codificarea dintre Hive și HBase
Să discutăm acum diferențele de bază dintre Hive și HBase în codificare.
| Baza de comparație | Stup | Hbase |
| Pentru a crea o bază de date | CREAȚI DATE DE DATE (DACĂ NU EXISTEAZĂ) NUMEI DE DATE; | Deoarece Hbase este o bază de date, nu trebuie să creăm o bază de date specifică |
| Pentru a arunca o bază de date | DATĂ DE DATĂ (DACĂ EXISTE) DENUMIRE DE DATĂ (RESTRICT SAU CASCADE); | N / A |
| Pentru a crea un tabel | CREAȚI (TEMPORAR SAU EXTERN) TABEL-NUME ((nume de coloană data_type (Comentariu coloană-comentariu), …)) (Comentariu tabel_comment) (ROW FORMAT rând-format) (stocat ca format fișier) | CREA '', '' |
| Pentru a modifica o masă | ALTER TABLE NUME RENAME TO new-name
ALTER TABLE nume DROP (COLUMN) nume coloană ALTER TABLE nume ADAUGĂ COLUMNE (col-spec (, col-spec ..)) ALTER TABLE nume CHANȚIE nume de coloană de tip nou de coloană ALTER TABLE NUMELE REPLACE COLUMNS (col-spec (, col-spec ..)) | ALTER "TABLE-NAME", NAME => "COLUMN-NAME", VERSIONS => |
| Dezactivarea unui tabel | N / A | dezactivați „TABLE-NAME” -> pentru a dezactiva numele tabelului specificat
disable_all 'r *' -> pentru a dezactiva toate tabelele care se potrivesc cu expresia obișnuită |
| Activarea unui tabel | N / A | activați „TABLE-NAME” |
| Pentru a arunca o masă | TABELUL DROP DACĂ EXISTE numele tabelului | Dacă dorim să aruncăm o tabelă, atunci mai întâi trebuie să o dezactivăm
dezactivează „numele tabelului” aruncați „numele tabelului” În mod similar, putem folosi disable_all și drop_all pentru a șterge tabelele care se potrivesc cu expresia regulată specificată. |
| Pentru a enumera bazele de date | arată baze de date; | N / A |
| Pentru a lista tabele în baza de date | tabele de spectacole; | listă |
| Pentru a descrie schema unui tabel | descrieți numele tabelului; | descrieți „numele tabelului” |
Integrarea Hive vs HBase
- Instalați și configurați Hive.
- Instalați și configurați HBase.
- Pentru integrarea atât a stupului, cât și a bazei HBase, folosim MANUAL DE STOCARE în stup.
- Storage Handlers este o combinație de SERDE, InputFormat, OutputFormat care acceptă orice entitate externă ca tabel în Hive.
- Prin urmare, această caracteristică ajută un utilizator să emită interogări SQL, indiferent dacă este prezent în tabelul Hadoop sau în baza de date bazată pe NOSQL, precum HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Acum vom analiza un exemplu pentru conectarea stupului cu HBase folosind HiveStorageHandler:
- În primul rând, trebuie să creăm tabela Hbase folosind comanda.
creați 'Student', 'personalinfo', 'informații dept'
-> Personalinfo și informații despre departament creează două familii de coloane diferite în tabelul Student.
- Trebuie să introducem unele date în tabelul Student. De exemplu, după cum am menționat mai jos.
pune 'student', 'sid01' ', ' personalinfo: nume ', ' Ram '
pune 'student', 'sid01' ', ' personalinfo: mailid ', ' '
pune 'student', 'sid01' ', ' deptinfo: deptname ', ' Java '
pune „Student”, „sid01”, „deptinfo: alăturat”, „1994”
-> În mod similar, putem crea date pentru sid02, sid03 …
- Acum trebuie să creăm tabelul Hive care indică tabelul HBase.
- Pentru fiecare coloană din Hbase, vom crea o tabelă specială pentru acea coloană din stup. În acest caz, vom crea 2 tabele în stup.
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> În mod similar, trebuie să creăm tabel cu detalii despre informații în stup.
- Acum putem scrie interogare SQL într-un stup, după cum am menționat mai jos.
select * from student_hbase;
În acest fel, putem integra Hive cu HBase.
Concluzie - Hive vs HBase
După cum s-a discutat, ambele sunt tehnologii diferite, care oferă funcționalități diferite în care Hive funcționează folosind limbajul SQL și poate fi numit și HQL și HBase folosesc perechi cheie-valoare pentru a analiza datele. Hive și HBase funcționează mai bine dacă sunt combinate, deoarece Hive au latență scăzută și pot prelucra o cantitate imensă de date, dar nu pot menține date actualizate, iar HBase nu acceptă analiza datelor, dar acceptă actualizări la nivel de rând pe o cantitate mare de date.
Articol recomandat
Acesta a fost un ghid pentru Hive vs HBase, semnificația lor, comparația dintre cap și cap, diferențele cheie, tabelul de comparare și concluzii. De asemenea, puteți consulta următoarele articole pentru a afla mai multe -
- Apache Pig vs Apache Hive - Top 12 diferențe utile
- Aflați cele mai bune 7 diferențe dintre Hadoop și HBase
- Top 12 Comparație dintre Apache Hive și Apache HBase (Infografie)
- Hadoop vs Hive - Aflați cele mai bune diferențe