

Ce este Big Data și Hadoop?
Datele cresc exponențial în fiecare zi și cu date în creștere apare nevoia de a utiliza aceste date. Ca și în zilele mai vechi, obișnuiam să avem unități de dischetă pentru a stoca date, iar transferul de date a fost, de asemenea, lent, dar în prezent acestea sunt insuficiente, iar stocarea în cloud este folosită, deoarece avem terabyte de date. În lumea de azi, avem social media care contribuie cel mai mare la creșterea datelor. Constă din comportamentul oamenilor, mentalitatea și alte câteva aspecte. Se spune că în fiecare minut sunt încărcate 300 de videoclipuri pe YouTube, peste 20 de milioane de fotografii sunt încărcate pe Facebook și multe altele. În plus, nu există o structură adecvată a datelor încărcate, ceea ce reprezintă cea mai mare provocare pentru prelucrarea acestor date.
Deoarece date enorme sunt generate în mare viteză, sistemele tradiționale RDBMS nu au putut să gestioneze o creștere rapidă. În plus, acestea nu sunt capabile să manipuleze date nestructurate. A devenit foarte dificil să gestionați o cantitate atât de mare de date eterogene în creștere rapidă și să prelucrați aceste date cu viteză mare de procesare. Astfel, a apărut nevoia unui astfel de sistem care să poată gestiona eficient un set de date mari. Prin urmare, pentru a rezolva scenariul Hadoop a luat ființă. HDFS este componenta Hadoop care a abordat problema de stocare a setului de date mare, folosind stocarea distribuită în timp ce YARN este componenta care a abordat problema procesării, reducând timpul de procesare drastic.
Hadoop este un cadru software de tip open-source pentru stocarea și procesarea seturilor de date mari folosind un grup mare distribuit de hardware de mărfuri. A fost dezvoltat de Doug Cutting și Michael J. Cafarella și este autorizat sub numele de Apache. Este scris folosind Java și a fost dezvoltat pe baza hârtiei scrise de Google în sistemul MapReduce și aplică concepte de programare funcțională. Este fiabil, flexibil din punct de vedere economic și scalabil.
Componentele de bază ale Hadoop
Componentele de bază ale Hadoop sunt următoarele
-
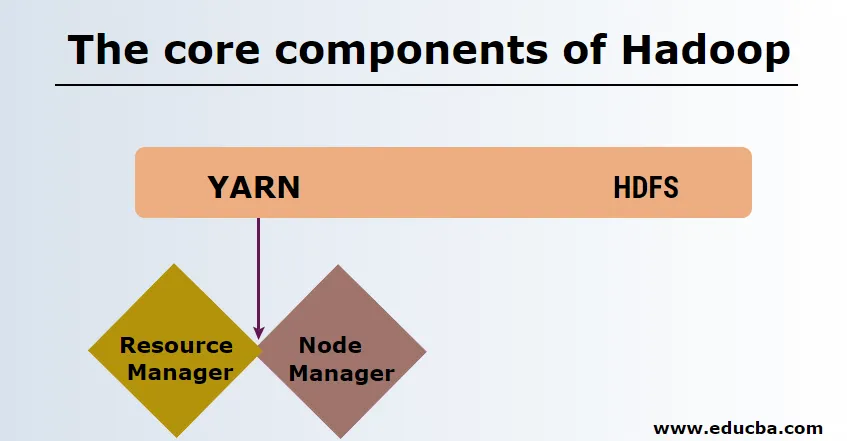
HDFS
Sistemul de fișiere distribuite HDFS sau Hadoop au Namenode și nod de date. Namenode este nodul principal care rulează demonul principal și gestionează nodurile de date și păstrează urmele tuturor operațiunilor. Datanode sunt sclavii în care datele sunt stocate efectiv.
-
FIRE
Fire este format din două componente principale:
1. ResourceManager: Se rulează pe nodul principal și gestionează toate resursele și programează toate aplicațiile. Are Scheduler & ApplicationManager.
2. NodeManager: rulează pe fiecare nod sclav și este responsabil pentru gestionarea containerelor și monitorizarea utilizării resurselor.
Mai multe componente ale Hadoop
Există mai multe componente ale Hadoop, cum ar fi porcul, stupul, mămăligă, flume, mahout, oozie, zookeeper, HBase etc.
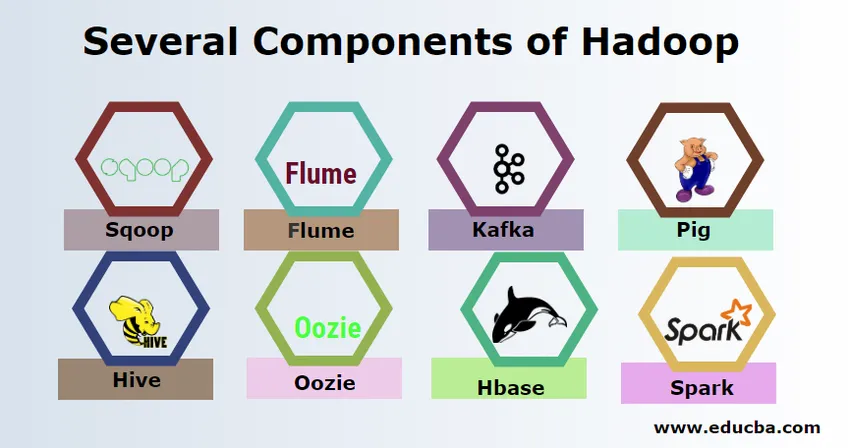
- Sqoop - Este utilizat pentru a importa și exporta date de la RDBMS la Hadoop și invers.
- Flume - Este folosit pentru a trage date în timp real în Hadoop.
- Kafka - Este un sistem de mesagerie folosit pentru a rula date în timp real în Hadoop.
- Porc - este folosit ca limbaj de script pentru prelucrarea datelor.
- Hive - Este un cadru de stocare a datelor construit pe HDFS, astfel încât utilizatorii familiarizați cu SQL pot executa interogări pentru a obține datele. Aceste interogări se numesc HiveQL.
- Oozie - Este utilizat pentru a programa fluxul de lucrări pentru a rula la evenimente sau timp specificat.
- Hbase - Este baza de date fără SQL oferită ca parte a Apache Hadoop.
- Scânteie - Este utilizat pentru a efectua procesarea în memorie, care este mult mai rapid decât reduce Harta hartă.
Furnizorii de Hadoop
Există o mulțime de companii care oferă distribuții Hadoop. Mai jos sunt câțiva dintre cei mai buni furnizori pentru Hadoop:
- Cloudera
- Hortonworks
- MapR
Există puține condiții prealabile pentru învățarea Hadoop. Experiența anterioară în limbajul Java și script-ul este necesară. Deși Hadoop are deja propriile limbaje de programare la nivel înalt, precum porcul și stupul, care generează codul backend pentru prelucrări ulterioare, totuși, este posibil să se creeze un program de reducere a hărții, orice limbaj de programare precum Ruby, Python, Perl și chiar C.
Bigdata și Hadoop au o cerere mare pe piața de astăzi. Aceasta va crește mai mult în zilele următoare. O mulțime de organizații s-au mutat deja în Hadoop și cei care nu se vor muta în curând. Există un raport curent care afirmă că marile corporații au început să investească în analiza datelor mari. Prognoza de marketing a datelor mari este întotdeauna în trend ascendent și nu este deloc o stare de scurtă durată. În afară de toate aceste locuri de muncă în Hadoop, iar datele mari oferă întotdeauna salarii mari în comparație cu alte tehnologii.
Cele mai mari companii de date mari și hadoop
Mai jos sunt câteva companii de top care utilizează cel mai mare număr de resurse Hadoop.
- Yahoo
- Amazon
- Royal Bank of Scotland
- căile aeriene britanice
- Expedia
- Walmart
Există o mulțime de companii care utilizează aplicații de date mari. Acestea sunt:
-
Nokia
Utilizează componente Cloudera și Hadoop precum HDFS, HBase, Sqoop, Scribe pentru aplicație. A utilizat în mod eficient datele utilizatorului pentru a înțelege și îmbunătăți experiența utilizatorului. Folosește prelucrarea datelor și analize complexe pentru construirea hărții cu trafic predictiv și modele de cote în straturi.
-
SAS
A colaborat cu Hadoop pentru a ajuta oamenii de știință de date să înțeleagă mai bine, oferind un mediu care oferă experiență vizuală și interactivă, ajutând astfel la explorarea noilor tendințe. Programele analitice extrag informații semnificative din date și tehnologia din memorie ajută accesul rapid la date.
Există, de asemenea, o mulțime de alte companii care folosesc platforme de date mari pentru diverse analize. Acestea sunt analiza datelor despre zboruri ale casetei negre din industria aviației, analiza diferită pe piața acționară etc.
Avantajele Haddop
Mai jos sunt câteva dintre avantajele Hadoop
- Scalabil - Spre deosebire de RDBMS tradițional, este o platformă extrem de scalabilă, deoarece poate stoca seturi de date mari în grupuri distribuite pe hardware-ul de marfă care operează în paralel.
- Eficient din punct de vedere al costurilor - Costul a fost prea mare pentru RDBMS pentru a stoca date care au fost ușurate în Hadoop.
- Rapid și flexibil - Oferă date care trebuie accesate într-o manieră rapidă prin sistemul său de fișiere distribuit. De asemenea, se oferă informații despre afaceri din date semistructurate și nestructurate.
- Tolerant la erori - Ori de câte ori sunt trimise date către un nod, aceleași date sunt replicate în alte noduri care pot fi accesate în caz de eșec al primului nod.
Concluzie - ce este Big Data și Hadoop
Datele sunt în continuă creștere și, prin urmare, va fi întotdeauna nevoie de date mari și Hadoop pentru a da sens acestor date. Din acest motiv, profesioniștii cu abilități Hadoop vor găsi întotdeauna oportunități ample în zilele următoare și pot fi un atu vital pentru o organizație care impulsionează afacerea și cariera lor.
Articole recomandate
Acesta a fost un ghid despre ceea ce este Big Data și Hadoop. Aici am discutat despre conceptele de bază și componentele Big Data și Hadoop. De asemenea, puteți consulta articolul următor pentru a afla mai multe -
- Exemple de analiză de date mari
- Utilizările Hadoop
- Ghid pentru vizualizarea datelor
- Ce este analiza Big Data?