

Introducere în comenzile stupului
Comanda Hive este un instrument de infrastructură pentru depozitul de date care se află în topul Hadoop pentru a rezuma datele Big. Procesează date structurate. Simplifică interogarea și analizarea datelor. Comanda Hive este, de asemenea, numită „schemă la citire;” stupul nu verifică datele când sunt încărcate, verificarea se întâmplă numai atunci când este emisă o interogare. Această proprietate a stupului face rapid pentru încărcarea inițială. Este ca și cum ai copia sau pur și simplu muta un fișier fără a pune restricții sau verificări. Stupul a fost dezvoltat pentru prima dată de Facebook. Fundația software Apache a preluat-o ulterior și a dezvoltat-o în continuare.
Iată componentele comenzii Hive:
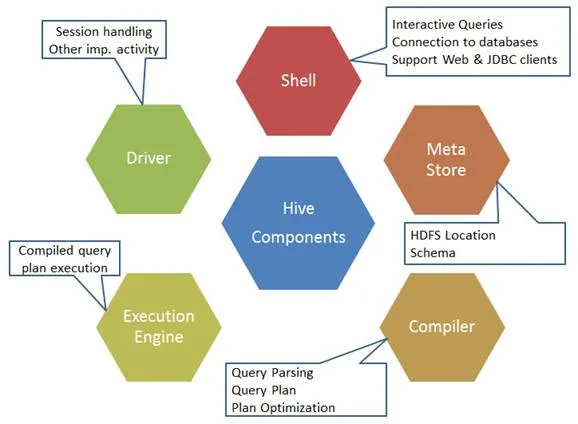
Fig 1. Componentele stupului
https://www.developer.com/
Iată caracteristicile comenzii Hive enumerate mai jos:
- Magazinele stup sunt un set de date brut și procesat în Hadoop.
- Este proiectat pentru procesarea tranzacțiilor OnLine (OLTP). OLTP este sistemele care facilitează datele cu volum mare în foarte puțin timp, fără dependență de serverul unic.
- Este rapid, scalabil și de încredere.
- Limbajul de interogare de tip SQL furnizat aici se numește HiveQL sau HQL. Acest lucru face ca sarcinile ETL și alte analize să fie mai ușoare.
Fig 2. Proprietățile stupului
Surse imagini: - Google
Există doar câteva limitări ale comenzii Hive, care sunt enumerate mai jos:
- Stupul nu suportă subînchirieri.
- Hive acceptă cu siguranță supra-scrierea, dar, din păcate, nu acceptă ștergerea și actualizările.
- Stupul nu este proiectat pentru OLTP, dar este folosit pentru el.
Pentru a intra în shell-ul interactiv al stupului:
$ HIVE_HOME / bin / stup
Comenzile de bază ale stupului
-
Crea
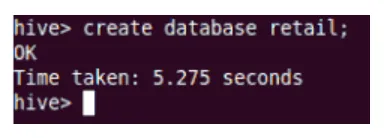
Aceasta va crea noua bază de date în Hive.
-
cădere brusca
Picătura va elimina un tabel din stup
-
Modifica
Comanda Alter vă va ajuta să redenumiți tabelele sau coloanele din tabel.
De exemplu:
stup> ALTER TABLE RENAME pentru angajat1;
-
Spectacol
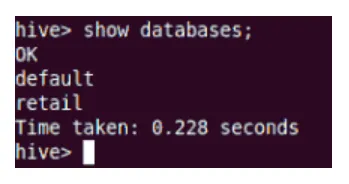
Comanda Show va arăta toate bazele de date cu domiciliul în Hive.
-
Descrie
Comanda Descriere vă va ajuta cu informațiile despre schema tabelului.
Comenzi intermediare ale stupului
Hive împarte un tabel în diferite partiții înrudite pe baza de coloane. Folosind aceste partiții, este mai ușor să interogați datele. Aceste partiții sunt împărțite în secțiuni suplimentare, pentru a efectua interogarea eficientă a datelor.
Cu alte cuvinte, gălețile distribuie date în setul de clustere, calculând codul de cheie al cheii menționat în interogare.
-
Adăugarea partiției
Adăugarea partiției se poate realiza prin modificarea tabelului. Spuneți că aveți tabelul „EMP”, cu câmpuri precum Id, Nume, Salariu, Dept, Desemnare și Yoj.
stup> angajat ALTER TABLE
> ADAUGĂ PARTITION (an = '2012')
locație '/ 2012 / part2012';
-
Redenumirea partiției
stup> PARTITION ALTER TABLE pentru angajați (an = '1203')
RENUMIRE LA PARTITION (Yoj = '1203');
-
Partition drop
stup> DROPUL angajatului ALTER TABLE (DACĂ EXISTE)
> PARTITION (an = '1203');
-
Operatori relaționali
Operatorii relaționali constau într-un anumit set de operatori, care ajută la preluarea informațiilor relevante.
De exemplu: Spuneți tabelul „EMP” arătat astfel:
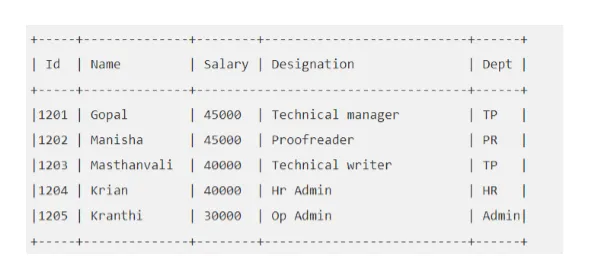
Să executăm o interogare Hive care ne va aduce angajatul al cărui salariu este mai mare de 30000.
stup> SELECTA * DE LA EMP UNDE Salariu> = 40000;
-
Operatori de aritmetică
Este vorba de operatori care ajută la executarea operațiunilor aritmetice pe operanzi și, la rândul lor, întorc întotdeauna tipuri de numere.
De exemplu: Pentru a adăuga două numere, cum ar fi 22 și 33
stup> SELECT 22 + 33 ADAUGĂ LA temp;
-
Operator logic
Acești operatori trebuie să execute operații logice, care în schimb întorc întotdeauna True / False.
stup> SELECTA * DE LA EMP UNDE Salariu> 40000 && Dept = TP;
Comenzi avansate stup
-
Vedere
Conceptul de vizualizare în Hive este similar ca în SQL. Vizualizarea poate fi creată în momentul executării unei instrucțiuni SELECT.
Exemplu:
stup> CREATE VIZIONARE EMP_30000 AS
SELECTA * DIN EMP
UNDE salariu> 30000;
-
Încărcarea datelor în tabel
Hive> Încărcați datele de intrare locală '/home/hduser/Desktop/AllStates.csv' în statele de tabel;
Aici „State” este tabelul deja creat în Hive.
https://www.tutorialspoint.com/hive/
Hive are câteva funcții încorporate care vă ajută să obțineți rezultatul într-un mod mai bun.
Ca rotund, podea, BIGINT etc.
-
A te alatura
Clauza de alăturare poate ajuta la unirea a două tabele bazate pe același nume de coloană.
Exemplu:
stup> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
DE LA CLIENTI c COMENȚII DE ÎNREGISTRARE o
ON (c.ID = o.CUSTOMER_ID);
Toate tipurile de îmbinări sunt suportate de stup: îmbinare exterioară stângă, îmbinare exterioară dreaptă, îmbinare exterioară completă.
Sfaturi și trucuri pentru a utiliza comenzile stupului
Hive face ca prelucrarea datelor să fie atât de ușoară, directă și extensibilă, încât utilizatorul să acorde o atenție mai mică la optimizarea interogărilor Hive Dar atenția la puține lucruri în timp ce scrii interogarea Hive, va aduce cu siguranță mare succes în gestionarea volumului de muncă și în economisirea de bani. Mai jos sunt câteva sfaturi cu privire la acest lucru:
- Partiții și găleți: Hive este un instrument de date mari, care poate interoga pe seturi de date mari. Cu toate acestea, scrierea interogării fără a înțelege domeniul poate aduce mari partiții în Hive.
Dacă utilizatorul cunoaște setul de date, atunci coloanele relevante și foarte utilizate ar putea fi grupate în aceeași partiție. Acest lucru va ajuta la rularea interogării mai rapid și ineficient.
În cele din urmă, nr. operațiunile mapper și I / O vor fi, de asemenea, reduse.
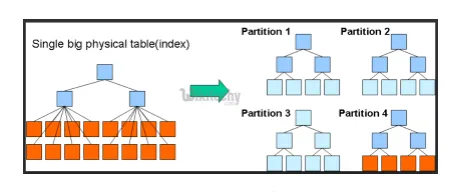
Fig 3. Compartimentare
Surse imagini: imagine Google
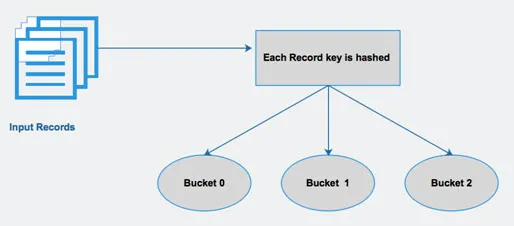
Fig 4 Bucketing
Surse imagini: - imagine Google
- Execuție paralelă: stupul rulează interogarea în mai multe etape. În unele cazuri, aceste etape pot depinde de alte etape, deci nu se poate începe, odată ce etapa anterioară este finalizată. Cu toate acestea, sarcinile independente pot rula paralel pentru a economisi timpul de rulare general. Pentru a activa rularea paralelă în stup:
set hive.exec.parallel = true;
Prin urmare, aceasta va îmbunătăți utilizarea clusterului.
- Blocarea eșantionării: Eșantionarea datelor dintr-un tabel va permite explorarea interogărilor asupra datelor.
În ciuda curgerii, mai degrabă dorim să eșantionăm setul de date mai întâmplător. Eșantionarea în bloc vine cu diverse sintaxe puternice, care ajută la prelevarea datelor într-un mod diferit.
Eșantionarea poate fi utilizată pentru găsirea a cca. informații din setul de date, cum ar fi distanța medie între origine și destinație.
Interogarea de 1% din datele mari va oferi răspunsul perfect. Explorarea devine mult mai ușoară și mai eficientă.
Concluzie - comenzi stup
Hive este o abstracție de nivel superior pe HDFS, care oferă un limbaj de interogare flexibil. Acesta ajută la interogarea și procesarea datelor într-un mod mai ușor.
Stupul poate fi îmbrăcat cu alte elemente Big Data, pentru a-și valorifica funcționalitatea într-un mod complet.
Articole recomandate
Acesta a fost un ghid pentru Comenzile stupului. Aici am discutat despre comenzile de stup, precum și cele avansate, precum și unele comenzi imediate ale stupului. De asemenea, puteți consulta articolul următor pentru a afla mai multe -
- Întrebări la interviu stup
- Hive VS Hue - Top 6 Comparații utile
- Comenzile Tableau
- Comenzi Adobe Photoshop
- Utilizarea funcției ORDER BY în stup
- Descărcați și instalați stupul pas cu pas